Over the weekend I launched Ring™ Log, which is simultaneously a critique of surveillance culture and a parody of machine vision in suburbia. In the interactive artist statement I call Ring™ Log an experiment in speculative surveillance.
“Speculative” in this context means what if?
What if Amazon’s Ring™ doorbell cams began integrating AI-powered object detection in order to identify, catalog, and report what the cameras “see” as they passively await for friends, neighbors, and strangers alike to visit your home? This is the question Ring™ Log asks. And, given the season (I write this on October 29, 2019), what would the cameras see and report on Halloween, when many of the figures that appear on your front stoop defy categorization?
I dive into the technical details and my inspirations in the artist statement, so no need to repeat myself here. I will add that I was very much inspired by an old Twilight Zone episode, even including several Easter Eggs to that effect. I was also inspired by the ridiculous posts I see on NextDoor, where paranoid neighbors routinely share Ring™ videos of “suspicious” visitors to their houses. Finally, I’m in debt to Everest Pipkin, whose work “What if Jupiter had turned into a Star” provided some of the underlying JavaScript effects for Ring™ Log. Everest’s work, like my own, appears with a permissive copyright license that allows for the reuse and modification of the code. Wouldn’t it be awesome if creative coders borrowed from Jupiter and Ring™ Log and made their own adaptations of these works, similar to what happened with Nick Montfort’s Taroko Gorge?
(Yeah, that’s a hint about what my students will be doing in my Electronic Literature course next semester!)
A few weeks ago I wrote about studying digital culture through the lens of specific file types. In the fall I’m teaching DIG 101 (Introduction to Digital Studies)—an amorphous course that is part new media studies, part digital humanities, part science and technology studies. I was imagining spending a week on, say, something like GIFs as way to understand Internet culture. My question is, what other file types could be similarly productive to explore?
That short post generated great ideas in the comments, on Facebook, and on Twitter. To make things easier to find again (for me and others), here are just some of the file type ideas that bubbled to the surface:
PDF
As commentator Sam Popowich put it, “love it or hate it” PDFs are everywhere. Ryan Cordell pointed out that Lisa Gitelman has a chapter devoted to PDFs in Paper Knowledge. Gitelman is exactly the kind of scholar I want undergraduates to read. Clear, perceptive, uncovering seemingly archaic history and showing why it matters.
WAD
Quite a few people suggested WADs, composite files made up sounds, sprites, graphics, level information, and other digital assets for PC games. Doom popularized WADs, but PC games continue to use similar composite files. You can use tools like GCFScape to unpack these files, and they lend themselves to digital forensic lab work in the classroom. Every time I teach Gone Home, for example, students explore unpacked sound and graphic files. It’s an alternative way of experiencing the game. My own research digging to WADS to find misogynistic game developer comments could come into play here too.
JPG
At first I thought studying JPGs would be redundant if GIFs are already on the table. Allison Parrish and Jeff Thompson make a strong case for JPGs though: they organize information differently, compress differently, and of course, are glitchable. Like PDFs, their very ubiquity renders them invisible as file types, especially to students who have grown up carrying a camera with them at all times.
EXIF
Vika Zafrin and Tim Owens recommended EXIF, one of the few file types I hadn’t already considered as a possibility. Technically I guess EXIF is a metadata standard, not a file type per se, but the relationship between metadata and data is crucial to understand, and EXIF can get us there. Plus, we can talk about privacy, tracking, and my colleague Owen Mundy’s fantastic I Know Where Your Cat Lives project.
Stigmatized File Types
@TopLeftBrick mentioned NFO files and Finn Arne Jørgensen brought up .torrent files, both of which belong to the world of pirated games, software, and media. Jason Mittell similarly suggested another what I call stigmatized file type:
.FLV , a hidden file type that allows you to study YouTube.
Before the rise of HTML5, YouTube videos were Flash files (FLV = Flash Video), and there were (and are) tricks to downloading these videos to watch offline. But it was a format you weren’t supposed to encounter; YouTube strove to make streaming seamless, hiding the actual video file. I would love to spend some time in DIG 101 studying all of these stigmatized file types, not so much to understand the technical features of the file formats themselves, but to better understand the cultural rules that influence the circulation of knowledge.
The Big Picture
The above list is certainly incomplete. And leaves off the file types that originally inspired this idea (MP3s, GIFs, HTML, and JSON). But it’s a great start. It’s also important to zoom out and see the big picture. To this end, Amelia Acker pointed me toward this surprisingly philosophical technical report from Microsoft Research: “What is a File?”
Indeed, what is a file and what do they mean is something we’ll be asking in DIG 101.
I am revamping “Introduction to Digital Studies,” my program’s overview of digital culture, creativity, and methodology. One approach is to partially organize the class around file types, the idea being that a close reading of certain file types can help us better understand contemporary culture, both online and off.
It’s a bit like Raymond William’s Keywords, except with file types. A few of the file types that seem especially generative to consider:
MP3 (Jonathan Sterne’s work on MP3s is the gold standard to follow)
GIF (especially the rise and fall and rise of the animated GIF)
HTML (a gateway to understanding the early history and ethos of the web)
JSON (as a way to talk about data and APIs)
This list is just an initial start, of course. What other culturally significant file types would you have students consider? And what undergrad-friendly readings about those file types would you recommend?
Digital Studies and Digital Art students at Davidson making cyborg interfaces with Makey Makeys and toys.
The Digital Studies program at Davidson College is growing! We now offer an interdisciplinary minor and, through our Center for Interdisciplinary Studies (CIS), an interdisciplinary major. Last year Digital Studies and the History Department partnered on a tenure-track search—leading to Dr. Jakub Kabala joining Davidson as a digital medievalist with a background in computational philology and digital spatial analysis.
I’m delighted to announce that Digital Studies is collaborating once again on a tenure line search, this time with the Art Department. Along with Jakub and myself, this position will form the core of the Digital Studies faculty. My vision for Digital Studies has always emphasized three areas: (1) the history, practice, and critique of digital methodologies; (2) the study of cultural texts, media, and practices made possible by modern technology; and (3) the design and creation of digital art and new media, which includes robotics, interactive installations, and physical computing. Roughly speaking, I think of these three areas in terms of methodology, culture, and creativity. This latest tenure track search addresses the last area, though of course the areas blur into each other in very interesting ways.
Here is the official search ad for the digital artist position. Please share widely!
Davidson College invites applications for a tenure-track Assistant Professor of Art and Digital Studies, with a specialization in interactive installation, transmedia art, robotics, data art, physical computing, or a similar creative field. Artists must demonstrate a distinguished record of creative work and a commitment to undergraduate education. Preference will be given to artists with a broad understanding of contemporary trends in Digital and New Media Art, including its history, theory, and practice. MFA by August 1, 2016 is required.
This tenure-track position is shared between the Art Department and Digital Studies Program. Art and Digital Studies at Davidson explore the contemporary technologies that shape daily life, focusing on critical making and digital culture. The successful applicant will teach in both Studio Art and Digital Studies. The candidate’s letter of application should highlight experiences that speak to both roles. The teaching load is 5 courses per year (reduced to 4 courses the first year). Classes include introductory and advanced digital art studio courses, as well as classes that focus on digital theory and practice.
Apply online at http://jobs.davidson.edu/. A complete application includes a letter of application, CV, artist’s statement, teaching philosophy, and a list of three or more references. In addition, submit links for up to 20 still images or up to 7 minutes of video in lieu of a portfolio. The application deadline is December 1, 2015. Do not send letters of reference until requested.
Davidson is strongly committed to achieving excellence and cultural diversity and welcomes applications from women, members of minority groups, and others who would bring additional dimensions to the college’s mission. Consistently ranked among the nation’s top liberal arts colleges, Davidson College is a highly selective, independent liberal arts college located in Davidson, North Carolina, close to the city of Charlotte. Davidson faculty enjoy a low student-faculty ratio, emphasis on and appreciation of excellence in teaching, and a collegial, respectful atmosphere that honors academic achievement and integrity.
Here (finally) is the talk I gave at the 2012 MLA Convention in Seattle. I was on Lori Emerson’s Reading Writing Interfaces: E-Literature’s Past and Present panel, along with Dene Grigar, Stephanie Strickland, and Marjorie Luesebrink. Lori’s talk on e-lit’s stand against the interface-free aesthetic worked particularly well with my own talk, which focused on Erik Loyer’s Strange Rain. I don’t offer a reading of Strange Rain so much as I use the piece as an entry point to think about interfaces—and my larger goal of reframing our concept of interfaces.
Today I want to talk about Strange Rain, an experiment in digital storytelling by the new media artist Erik Loyer.
Strange Rain came out in 2010 and runs on Apple iOS devices—the iPhone, iPod Touch, and iPad. As Loyer describes the work, Strange Rain turns your iPad into a “skylight on a rainy day.” You can play Strange Rain in four different modes. In the wordless mode, dark storm clouds shroud the screen, and the player can touch and tap its surface, causing columns of rain to pitter patter down upon the player’s first-person perspective. The raindrops appear to splatter on the screen, streaking it for a moment, and then slowly fade away. Each tap also plays a note or two of a bell-like celesta.
The other modes build upon this core mechanic. In the “whispers” mode, each tap causes words as well as raindrops to fall from the sky.
The “story” mode is the heart of Strange Rain. Here the player triggers the thoughts of Alphonse, a man standing in the rain, pondering a family tragedy.
And finally, with the most recent update of the app, there’s a fourth mode, the“feeds” mode. This allows players to replace the text of the story with tweets from a Twitter search, say the #MLA12 hashtag.
Note that any authorial information—Twitter user name, time or date—is stripped from the tweet when it appears,as if the tweet were the player’s own thoughts, making the feed mode more intimate than you might expect.
Like many of the best works of electronic literature, there are a number of ways to talk about Strange Rain, a number of ways to frame it. Especially in the wordless mode, Strange Rain fits alongside the growing genre of meditation apps for mobile devices, apps meant to calm the mind and sooth the spirit—like Pocket Pond:
In Pocket Pond, every touch of the screen creates a rippling effect.
The digital equivalent of a miniature zen garden, these apps allow us to contemplate minimalistic nature scenes on devices built by women workers in a FoxConn factory in Chengdu, China.
It’s appropriate that it’s the “wordless mode” that provides the seemingly most unmediated or direct experience of Strange Rain, when those workers who built the device upon which it runs are all but silent or silenced.
The “whispers” mode, meanwhile, with its words falling from the sky, recalls the trope in new media of falling letters—words that descend on the screen or even in large-scale multimedia installation pieces such as Camille Utterback and Romy Achituv’s Text Rain (1999).
And of course, the story mode even more directly situates Strange Rain as a work of electronic literature, allowing the reader to tap through “Convertible,” a short story by Loyer, which, not coincidentally I think, involvesa car crash, another long-standing trope of electronic literature.
As early as 1994, in fact, Stuart Moulthrop asked the question, “Why are there so many car wrecks in hypertext fiction?” (Moulthrop, “Crash” 5). Moulthrop speculated that it’s because hypertext and car crashes share the same kind of “hyperkinetic hurtle” and “disintegrating sensory whirl” (8). Perhaps Moulthrop’s characterization of hypertext held up in 1994…
…(though I’m not sure it did), but certainly today there are many more metaphors one can use to describe electronic literature than a car crash. And in fact I’d suggest that Strange Rain is intentionally playing with the car crash metaphor and even overturning it with its slow, meditative pace.
At the same time as this reflective component of Strange Rain, there are elements that make the work very much a game, featuring what any player of modern console or PC games would find familiar: achievements, unlocked by triggering particular moments in the story. Strange Rain even shows up on the iOS’s “Game Center.”
The way users can tap through Alphonse’s thoughts in Strange Rain recalls one of Moulthrop’s own works, the post-9/11 Pax, which Moulthrop calls, using a term from John Cayley, a “textual instrument”—as if the piece were a musical instrument that produces text rather than music.
We could think of Strange Rain as a textual instrument, then, or to use Noah Wardrip-Fruin’s reformulation of Cayley’s idea, as “playable media.” Wardrip-Fruin suggests that thinking of electronic literature in terms of playable media replaces a rather uninteresting question—“Is this a game?”—with a more productive inquiry, “How is this played?”
There’s plenty to say about all of these framing elements of Strange Rain—as an artwork, a story, a game, an instrument—but I want to follow Wardrip-Fuin’s advice and think about the question, how is Strange Rain played? More specifically, what is its interface? What happens when we think about Strange Rain in terms of the poetics of motion and touch?
Let me show you a quick video of Erik Loyer demonstrating the interface of Strange Rain, because there are a few characteristics of the piece that are lost in my description of it.
A key element that I hope you can see from this video is that the dominant visual element of Strange Rain—the background photograph—is never entirely visible on the screen. The photograph was taken during a tornado watch in Paulding County in northwest Ohio in 2007 and posted as a Creative Commons image on the photo-sharing site Flickr. But we never see this entire image at once on the iPad or iPhone screen. The boundaries of the photograph exceed the dimensions of the screen, and Strange Rain uses the hardware accelerometer to detect your motion, your movements. So that when you tilt the iPad even slightly, the image tilts slightly in the opposite direction. It’s as if there’s a larger world inside the screen, or rather, behind the screen. And this world is broader and deeper than what’s seen on the surface. Loyer described it to me this way: it’s “like augmented reality, but without the annoying distraction of trying to actually see the real world through the display” (Loyer 1).
This kinetic screen is one of the most compelling features of Strange Rain. As soon as you pick up the iPad or iPhone with Strange Rain running, it reacts to you. The work interacts with you before you even realize you’re interacting with it. Strange Rain taps into a kind of “camcorder subjectivity”—the entirely naturalized practice we now have of viewing the world through devices that have cameras on one end and screens on the other. Think about older videocameras, which you held up to your eye, and you saw the world straight through the camera. And then think of Flip cams or smartphone cameras we hold out in front of us. We looked through older videocameras as we filmed. We look at smartphone cameras as we film.
So when we pick up Strange Rain we have already been trained to accept this camcorder model, but we’re momentarily taken aback, I think, to discover that it doesn’t work quite the way we think it should. That is, it’s as if we are shooting a handheld camcorder onto a scene we cannot really control.
This aspect of the interface plays out in interesting ways. Loyer has an illustrative story about the first public test of Strange Rain. As people began to play the piece, many of them held it up over their heads so that “it looked like the rain was falling on them from above—many people thought that was the intended way to play the piece” (Loyer 1).
That is, people wanted it to work like a camcorder, and when it didn’t, they themselves tried to match their exterior actions to the interior environment of the piece.
There’s more to say about the poetics of motion with Strange Rain but I want to move on to the idea of touch. We’ve seen how touch propels the narrative of Strange Rain. Originally Loyer had planned on having each tap generate a single word, though he found that to be too tedious, requiring too many taps to telegraph a single thought (Loyer 1). It was, oddly enough in a work of playable media that was meant to be intimate and contemplative, too slow. Or rather, it required too much action—too much tapping—on the part of reader. So much tapping destroyed the slow, recursive feeling of the piece. It becomes frantic instead of serene.
Loyer tweaked the mechanic then, making each tap produce a distinct thought. Nonetheless, from my own experience and from watching other readers, I know that there’s an urge to tap quickly. In the story mode of Strange Rain you sometimes get caught in narrative loops—which again is Loyer playing with the idea of recursivity found in early hypertext fiction rather than merely reproducing it. Given the repetitive nature of Strange Rain, I’ve seen people want to fight against the system and tap fast. You see the same thought five times in a row, and you start tapping faster, even drumming using multiple fingers. And the piece paradoxically encourages this, as the only way to bring about a conclusion is to provoke an intense moment of anxiety for Alphonse, which you do by tapping more frantically.
I’m fascinated by with this tension between slow tapping and fast tapping—what I call haptic density—because it reveals the outer edges of the interface of the system. Quite literally.
Move from three fingers to four—easy to do when you want to bring Alphonse to a crisis moment—and the iPad translates your gestures differently. Four fingers tells the iPad you want to swipe to another application, the Windows equivalent of ALT-TAB. The multi-touch interface of the iPad trumps the touch interface of Strange Rain. There’s a slipperiness of the screen. The text is precipitously and perilously fragile and inadvertently escapable. The immersive nature of new media that years ago Janet Murray highlighted as an essential element of the form is entirely an illusion.
I want to conclude then by asking a question: what happen when we begin to think differently about interfaces? We usually think of an interface as a shared contact point between two distinct objects. The focus is on what is common. But what if we begin thinking—and I think Strange Rain encourages this—what if we begin thinking about interfaces in terms of difference. Instead of interfaces, what about thresholds, liminal spaces between two distinct elements. How does Strange Rain or any piece of digital expressive culture have both an interface, and a threshold, or thresholds? What are the edges of the work? And what do we discover when we transgress them?
Each of these works offers a meditation upon the act of reading or writing, the power of stories, the role of storytellers, and the materiality of books themselves as physical objects. In addition to these printed and (mostly) bound texts, my English Honors Seminar students will encounter a range of other unconventional narrative forms, from Jonathan Blow’s Braid to Kate Pullinger’s Inanimate Alice, from Christopher Strachey’s machine-generated love letters to Robert Coover’s deck of storytelling playing cards. Along the way we’ll also consider mash-ups, databased stories, role-playing games, interactive fiction, and a host of other narrative forms. We’ll also (a heads-up to my students) create some of our own post-print beasties…
• Italo Calvino, If on a Winter’s Night a Traveler (Harvest Books, ISBN 0156439611)
• Don DeLillo, Mao II (Penguin, ISBN 978-0140152746)
• Mark Z. Danielewski, House of Leaves (Pantheon, ISBN 978-0375703768)
• Salvador Plascencia, The People of Paper (Mariner, ISBN 978-0156032117)
• Anne Carson, Nox (New Directions, ISBN 978-0811218702)
[This is the text, more or less, of the talk I delivered at the 2011 biennial meeting of the Society for Textual Scholarship, which took place March 16-18 at Penn State University. I originally planned on talking about the role of metadata in two digital media projects—a topic that would have fit nicely with STS’s official mandate of investigating print and digital textual culture. But at the last minute (i.e. the night before), I changed the focus of my talk, turning it into a thinly-veiled call for digital textual scholarship (primarily the creation of digital editions of print works) to rethink everything it does. (Okay, that’s an exaggeration. But I do argue that there’s a lot the creators of digital editions of texts should learn from born-digital creative projects.)
Also, it was the day after St. Patrick’s Day. And the fire alarm went off several times during my talk.
None of these events are related.]
The Poetics of Metadata and the Potential of Paradata
in We Feel Fine and The Whale Hunt
I once made fun of the tendency of academics to begin their papers by apologizing in advance for the very same papers they were about to begin. I’m not exactly going to apologize for this paper. But I do want to begin by saying that this is not the paper I came to give. I had that paper, it was written, and it was a good paper. It was the kind of paper I wouldn’t have to apologize for.
But, last night, I trashed it.
I trashed that paper. Call it the Danny Boy effect, I don’t know. But it wasn’t the paper I felt I needed to deliver, here, today.
Throughout the past two days I’ve detected a low level background hum in the conference rooms, a kind of anxiety about digital texts and how we interact with them. And I wanted to acknowledge that anxiety, and perhaps even gesture toward a way forward in my paper. So, I rewrote it. Last night, in my hotel room. And, well, it’s not exactly finished. So I want to apologize in advance, not for what I say in the paper, but for all the things I don’t say.
My original talk had positioned two online works by the new media artist Jonathan Harris as two complementary expressions of metadata. I had a nice title for that paper. I even coined a new word in my title.
But this title doesn’t work anymore.
I have a new title. It’s a bit more ambitious.
But at least I’ve still got that word I coined.
Paradata.
It’s a lovely word. And truth be told, just between you and me, I didn’t coin it. In the social sciences, paradata refers to data about the data collection process itself—say the date or time of a survey, or other information about how a survey was conducted. But there are other senses of the prefix “para” I’m trying to evoke. In textual studies, of course, para-, as in paratext, is what Genette calls the threshold of the text. I’m guessing I don’t have to say anything more about paratext to this audience.
But there’s a third notion of “para” that I want to play with. It comes from the idea of paracinema, which Jeffrey Sconce first described in 1996. Paracinema is a kind of “reading protocol” that valorizes what most audiences would otherwise consider to be cinematic trash. The paracinematic aesthetic redeems films that are so bad that they actually become worth watching—worth enjoying—and it does so in a confrontational way that seeks to establish a counter-cinema.
Following Sconce’s work, the videogame theorist Jesper Juul has wondered if there can be such a thing as paragames—illogical, improbable, and unreasonably bad games. Such games, Juul suggests, might teach us about our tastes and playing habits, and what the limits of those tastes are. And even more, such paragames might actually revel in their badness, becoming fun to play in the process.
Trying to tap into these three different senses of “para,” I’ve been thinking about paradata. And I’ve got to tell you, so far, it’s a mess. (And this part of my paper was actually a mess in the original version of my paper as well). My concept of paradata is a big mess and it may not mean anything at all.
This is what I have so far: paradata is metadata at a threshold, or paraphrasing Genette, data that exists in a zone between metadata and not metadata. At the same time, in many cases it’s data that’s so flawed, so imperfect that it actually tells us more than compliant, well-structured metadata does.
So let me turn now to We Feel Fine, a massive, ongoing digital databased storytelling project rich with metadata—and possibly, paradata.
We Feel Fine is an astonishing collection of tens of thousands of sentences extracted from tens of thousands of blog posts, all containing the phrase “I feel” or “I am feeling.” It was designed by new media artist Jonathan Harris and the computer scientist Sep Kamvar and launched in May 2006.
The project is essentially an automated script that visits thousands of blogs every minute, and whenever the script detects the words “I feel” or “I am feeling,” it captures that sentence and sends it to a database. As of early this year, the project has harvested 14 million expressions of emotions from 2.5 million people. And the site has done this at a rate of 10,000 to 15,000 “feelings” a day.
Let me repeat that: every day approximately 10,000 new entries are added to We Feel Fine.
The heart of the project appears to be the multifaceted interface that has six so-called “movements”—six ways of visualizing the data collected by We Feel Fine’s crawler.
The default movement is Madness, a swarm of fifteen-hundred colored circles and squares, each one representing a single sentence from a blog post, a single “feeling.” The circles contain text only, while the squares include images associated with the respective blog post.
The colors of the particles signify emotional valence, with shades of yellow representing more positive emotions, red signaling anger. Blue is associated with sad feelings, and so on. This graphic, by the way, comes from the book version of We Feel Fine.
The book came out in 2009. In it, Harris and Kamvar curate hundreds of the most compelling additions to We Feel Fine, as well as analyze the millions of blog posts they’ve collected with with extensive data visualizations—graphs, and charts, and diagrams.
The book is an amazing project in and of itself and deserves its own separate talk. It raises important questions about archives, authorship, editorial practices, the material differences between a dynamic online project and a static printed work, and so on. I’ll leaves aside these questions right now; instead, I want to turn to the site itself. Let’s look at the Madness movement in action.
(And here I went online and interacted with the site. Why don’t you do that too, and come back later?)
(Also, right about here a fire alarm went off. Which, semantically, makes no sense. The alarm turned on, but I said it went off.)
(I can’t reproduce the sound of that particular fire alarm going off. I bet you have some sort of alarm on your phone or something you could make go off, right?)
(No? You don’t? Or you’re just as confused about on and off as I am? Then enjoy this short video intermission, which interrupts my talk, which I’m writing and which you’re reading, about as intrusively as the alarms interrupted my panel.)
(Okay. Back to my talk, which I’m writing, and which you’re reading.)
In the Madness movement you can click on any single circle, and the “feeling” will appear at the top of the screen. Another click on that feeling will drill down to the original blog post in its original context. So what’s important here is that a single click transitions from the general to the particular, from the crowd to the individual. You can also click on the squares to show “feelings” that have an image associated with them. And you have the option to “save” these images, which sends them to a gallery, just about the only way you can be sure to ever find any given image in We Feel Fine again.
At the top of the screen are are six filters you can use to narrow down what appears in the Madness movement. Working right to left, you can search by date, by location, the weather at that location at the time of the original blog post, the age of the blogger, the gender of the blogger, and finally, the feeling itself that is named in the blog post. While every item in the We Feel Fine database will have the feeling and date information attached to it, the age, gender, location, and weather fields are populated only for those items in which that information is publicly available—say a LiveJournal or Blogger profile that lists that information, or a Flickr photo that’s been geotagged.
What I want to call your attention to before I run through the other five movements of We Feel Fine is that these filters depend upon metadata. By metadata, I mean the descriptive information the database associates with the original blog post. This metadata not only makes We Feel Fine browsable, it makes it possible. The metadata is the data. The story—if there is one to be found in We Feel Fine—emerges only through the metadata.
You can manipulate the other five movements using these filters. At first, for example, the Murmurs movement displays a reverse chronological streaming, like movie credits, of the most recent emotions. The text appears letter-by-letter, as if it were being typed. This visual trick heightens the voyeuristic sensibility of We Feel Fine and makes it seem less like a database and more like a narrative, or even more to the point, like a confessional.
The Montage movement, meanwhile, organizes the emotions into browsable photo galleries:
By clicking on a photo and selecting save, you can add photos to a permanent “gallery.” Because the database grows so incredibly fast, this is the only way to ensure that you’ll be able to find any given photograph again in the future. There’s a strong ethos of ephemerality in We Feel Fine. To use one of Marie-Laure Ryan’s metaphors for a certain kind of new media, We Feel Fine is a kaleidoscope, an assemblage of fragments always in motion, never the same reading or viewing experience twice. We have little control over the experience. It’s only through manipulating the filters that we can hope to bring even a little coherency to what we read.
The next of the five movements is the Mobs movement. Mobs provides five separate data visualization of the most recent fifteen-hundred feelings. One of the most interesting aspects of the Mobs movement is that it highlights those moments when the filters don’t work, or at least not very well, because of missing metadata.
For instance, clicking the Age visualizations tells us that 1,223 (of the most recent 1,500) feelings have no age information attached to them. Similarly, the Location visualization draws attention to the large number of blog posts that lack any metadata regarding their location.
Unlike many other massive datamining projects, say, Google’s Ngram Viewer, We Feel Fine turns its missing metadata into a new source of information. In a kind of playful return of the repressed, the missing metadata is colorfully highlighted—it becomes paradata. The null set finds representation in We Feel Fine.
The Metrics movement is the fourth movement. And it shows what Kamvar and Harris call the “most salient” feelings, by which they mean “the ways in which a given population differs from the global average.”
Right now, for example, we see that “Crazy” is trending 3.8 times more than normal, while people are feeling “alive” 3.1 times more than usual. (Good for them!). Here again we see an ability to map the local against the global. It addresses what I see as one of the problems of large-scale data visualization projects, like the ones that Lev Manovich calls “cultural analytics.”
Ngram and the like are not forms of distant reading. There’s distant reading, and then there’s simply distance, which is all they offer. We Feel Fine mediates that distance, both visually, and practically.
(And here I was going to also say the following, but I was already in hot water at the conference for my provocations, so I didn’t say it, but I’ll write it here: Cultural analytics echo a totalitarian impulse for precise vision and control over broad swaths of populations.)
And finally, the Mounds movement, which simply shows big piles of emotion, beginning with whatever feeling is the most common at the moment, and moving on down the line towards less common emotions. The Mounds movement is at once the least useful visualization but also the most playful, with its globs that jiggle as you move your cursor over them.
(Obviously you can’t see it above, in the static image but…) The mounds convey what game designers call “juiciness.” As Jesper Juul characterizes juiciness, it’s “excessive positive feedback in response to the player’s actions.” Or, as one game designer puts it, a juicy game “will bounce and wiggle and squirt…it feels alive and responds to everything that you do.”
Harris’s work abounds with juicy, playful elements, and they’re not just eye candy. They are part of the interface, part of the design, and they make We Feel Fine welcoming, inviting. You want to spend time with it. Those aren’t characteristics you’d normally associate with a database. And make no mistake about it. We Feel Fine is a database. All of these movements are simply its frontend—a GUI Java applet written in Processing that obscures a very deliberate and structured data flow.
The true heart of We Feel Fine is not the responsive interface, but the 26,000 lines of code running on 5 different servers, and the MySQL database that stores the 10,000 new feelings collected each and every day. In their book, Kamvar and Harris provide an overview of the dozen or so main components that make up We Feel Fine’s backend.
It begins with a URL server that maintains the list of URLs to be crawled and the crawler itself, which runs on a single dedicated server.
Pages retrieved by the crawler are sent to the “Feeling Indexer,” which locates the words “feel” or “feeling” in the blog post. The adjective following “feel” or “feeling” is matched against the “emotional lexicon”—a list of 2,178 feelings that are indexed by We Feel Fine. If the emotion is not in the lexicon, it won’t be saved. That emotion is dead to We Feel Fine. But if the emotion does match the index, the script extracts the sentence with that feeling and any other information available (this is where the gender, location, and date data are parsed).
Next there’s the actual MySQL database, which stores the following fields for each data item: the extracted sentence, the feeling, the date, time, post URL, weather, and gender, age, and location information.
Then there’s an open API server and several other client applications. And finally, we reach the front end.
Now, why have I just taken this detour into the backend of We Feel Fine?
Because, if we pay attention to the hardware and software of We Feel Fine, we’ll notice important details that might otherwise escape us. For example, I don’t know if you noticed from the examples I showed earlier, but all of the sentences in We Feel Fine are stripped of their formatting. This is because the Perl code in the backend converts all of the text to lowercase, removes any HTML tags, and eliminates any non-alphanumeric characters:
The algorithm tampers with the data. The code mediates the raw information. In doing so, We Feel Fine makes both an editorial and aesthetic statement.
In fact, once we understand some of the procedural logic of We Feel Fine, we can discover all sorts of ways that the database proves itself to be unreliable.
I’ve already mentioned that if you express a feeling that is not among the 2,178 emotions tabulated, then your feeling doesn’t count. But there’s also the tricky language misdirection the algorithm pulls off, in which the same “feeling” is interpreted by the machine to be the same, no matter how it is used in the sentence. In this way, the machine exhibits the same kind of “naïve empiricism” (using Johanna Drucker’s dismissive phrase) that some humanists do interpreting quantitative data.
And finally, consider many of the images in the Montage movement. When there are multiple images on a blog page, the crawler only grabs the biggest one—and not biggest in dimensions, but biggest in file size, because that’s easier for the algorithm to detect—and this image often ends up being the header image for the blog, rather than connected to the actual feeling itself, as in this example.
The star pattern happens to be a sidebar image, rather than anything associated with the actual blog post that states the feeling:
So We Feel Fine forces associations. In experimental poetry or electronic literature communities, these kinds of random associations are celebrated. The procedural creation of art, literature, or music has a long tradition.
But in a database that seeks to be a representative “almanac of human emotions”? We’re in new territory there.
But in fact, it is representative, in the sense that human emotions are fungible, ephemeral, disjunctive, and, let’s face, sometimes random.
Let me bring this full circle, by returning to the revised title of my talk. I mentioned at the beginning that I felt this low-grade but pervasive concern about digital work these past few days at STS. I’ve heard questions like Are we doing everything we can to make digital editions accessible, legible, readable, and teachable? Where are we failing, some people have wondered. Why are we failing? Or at least, Why have we not yet reached the level of success that many of the very same people at this conference were predicting ten or fifteen or, dare I say it, twenty years ago?
Maybe because we’re doing it wrong.
I want to propose that we can learn a lot from We Feel Fine as we exit out the far end of what some media scholars have called the Gutenberg Parenthesis.
What can we learn from We Feel Fine?
Four things:
It’s inviting
It’s paradata
It’s open
It’s juicy
Imagine if textual scholars built their digital editions and archives using these four principles.
Think about We Feel Fine and what makes work. Most importantly, We Feel Fine is a compelling reading experience. It’s not daunting. There’s a playful balance between interactivity and narrative coherence.
Secondly, and this goes back to my idea of paradata. Harris and Kamvar are not afraid to corrupt the source data, or to create metadata that blurs the line between metadata and not-metadata. They are not afraid to play with their sources, and for the most part, they are up front about how they’re playing with them.
This relates to the third feature of We Feel Fine that we should learn from. It’s open. Some of the source code is available. The list of emotions is available. There’s an open API, which anyone can use to build their own application on top of We Feel Fine, or more generally extract data from.
And finally, it’s juicy. I admit, this is probably not a term many textual scholars use in their research, but it’s essential for the success of We Feel Fine. The text responds to you. It’s alive in your hands, and I don’t think there’s much more we could ever ask from a text.
Bibliography
Drucker, Johanna. 2010. “Humanistic Approaches to the Graphical Expression of Interpretation” presented at the Hyperstudio: Digital Humanities at MIT, May 20, Cambridge, MA. http://mitworld.mit.edu/video/796.
Genette, Gerard. 1997. Paratexts: Thresholds of Interpretation. Cambridge: Cambridge University Press.
Juul, Jesper. 2010. A Casual Revolution: Reinventing Video Games and Their Players. Cambridge, MA: MIT Press.
Ryan, Marie-Laure. 2001. Narrative as Virtual Reality: Immersion and Interactivity in Literature and Electronic Media. Baltimore: Johns Hopkins University Press.
Sconce, Jeffrey. 1995. “‘Trashing’ the academy: taste, excess, and an emerging politics of cinematic style.” Screen 36 (4) (December 1): 371-393.
[This is the text of my second talk at the 2011 MLA convention in Los Angeles, for a panel on “Close Reading the Digital.” My talk was accompanied by a Prezi “Zooming” presentation, which I have replicated here with still images (the original slideshow is at the end of this post). In 15 minutes I could only gesture toward some of the broader historical and cultural meanings that resonate outward from code—but I am pursuing this project further and I welcome your thoughts and questions.]
New media critics such as Nick Montfort and Matthew Kirschenbaum have observed that a certain “screen essentialism” pervades new media studies, in which the “digital event on the screen,” as Kirschenbaum puts it (Kirschenbaum 4), becomes the sole object of study at the expense of the underlying computer code, the hardware, the storage devices, and even the non-digital inputs and outputs that make the digital object possible in the first place. There are a number of ways to remedy this essentialism, and the approach that I want to focus on today is the close reading of code.
Frederich Kittler has said that code is the only language that does what it says. But the close reading of code insists that code not only does what it says, it says things it does not do. Like any language, code operates on a literal plane—literal to the machine, that is—but it also operates on an evocative plane, rife with gaps, idiosyncrasies, and suggestive traces of its context. And the more the language emphasizes human legibility (for example, a high-level language like BASIC or Inform 7), the greater the chance that there’s some slippage in the code that is readable by the machine one way and readable by scholars and critics in another.
Today I want to close read some snippets of code from Micropolis, the open-source version of SimCity that was included on the Linux-based XO computers in the One Laptop per Child program.
Designed by the legendary Will Wright, SimCity was released by Maxis in 1989 on the Commodore 64, and it was the first of many popular Sim games, such as SimAnt and SimFarm, not to mention the enduring SimCity series of games—that were ported to dozens of platforms, from DOS to the iPad. Electronic Arts owns the rights to the SimCity brand, and in 2008, EA released the source code of the original game into the wild under a GPL License—a General Public License. EA prohibited any resulting branch of the game from using the SimCity name, so the developers, led by Don Hopkins, called it Micropolis, which was in fact Wright’s original name for his city simulation.
From the beginning, SimCity was criticized for presenting a naive vision of urban planning, if not an altogether egregious one. I don’t need to rehearse all those critiques here, but they boil down to what Ian Bogost calls the procedural rhetoric of the game. By procedural rhetoric, Bogost simply means the implicit or explicit argument a computer model makes. Rather than using words like a book, or images like a film, a game “makes a claim about how something works by modeling its processes” (Bogost, “The Proceduralist Style“).
In the case of SimCity, I want to explore a particularly rich site of embedded procedural rhetoric—the procedural rhetoric of crime. I’m hardly the first to think about the way SimCity or Micropolis models crime. Again, these criticisms date back to the nineties. And as recently as 2007, the legendary computer scientist Alan Kay called SimCity a “pernicious…black box,” full of assumptions and “somewhat arbitrary knowledge” that can’t be questioned or changed (Kay).
Kay goes on to illustrate his point using the example of crime in SimCity. SimCity, Kay notes, “gets the players to discover that the way to counter rising crime is to put in more police stations.” Of all the possible options in the real world—increasing funding for education, creating jobs, and so on—it’s the presence of the police that lowers crime in SimCity. That is the procedural rhetoric of the game.
And it doesn’t take long for players to figure it out. In fact, the original manual itself tells the player that “Police Departments lower the crime rate in the surrounding area. This in turn raises property values.”
It’s one thing for the manual to propose a relationship between crime, property values, and law enforcement, but quite another for the player to see that relationship enacted within the simulation. Players have to get a feel for it on their own as they play the game. The goal of the simulation, then, is not so much to win the game as it is to uncover what Lev Manovich calls the “hidden logic” of the game (Manovich 222). A player’s success in a simulation hinges upon discovering the algorithm underlying the game.
But, if the manual describes the model to us and players can discover it for themselves through gameplay, then what’s the value of looking at the code of the game. Why bother? What can it tell us that playing the game cannot?
Before I go any further, I want to be clear: I am not a programmer. I couldn’t code my way out of a paper bag. And this leads me to a crucial point I’d like to make today: you don’t have to be a coder to talk about code. Anybody can talk about code. Anybody can close read code. But you do need to develop some degree of what Michael Mateas has called “procedural literacy” (Mateas 1).
Let’s look at a piece of code from Micropolis and practice procedural literacy. This is a snippet from span.cpp, one of the many sub-programs called by the core Micropolis engine.
It’s written in C++, one of the most common middle-level programming languages—Firefox is written in C++, for example, as well as Photoshop, and nearly every Microsoft product. By paying attention to variable names, even a non-programmer might be able to discern that this code scans the player’s city map and calculates a number of critical statistics: population density, the likelihood of fire, pollution, land value, and the function that originally interested me in Micropolis,a neighborhood’s crime rate.
This specific calculation appears in lines 413-424. We start off with the crime rate variable Z at a baseline of 128, which is not as random at it seems, being exactly half of 256, the highest 8-bit binary value available on the original SimCity platform, the 8-bit Commodore 64.
128 is the baseline and the crime rate either goes up or down from there. The land value variable is subtracted from Z, and then the population density is added to Z:
While the number of police stations lowers Z.
It’s just as the manual said: crime is a function of population density, land value, and police stations, and a strict function at that. But the code makes visible nuances that are absent from the manual’s pithy description of crime rates. For example, land that has no value—land that hasn’t been built upon or utilized in your city—has no crime rate. This shows up in lines 433-434:
Also, because of this strict algorithm, there is no chance of a neighborhood existing outside of this model. The algorithm is, in Jeremy Douglass’s words when he saw this code, “absolutely deterministic.” A populous neighborhood with little police presence can never be crime free. Land value is likewise reduced to set formula, seen in this equation in lines 264-271:
Essentially these lines tell us that land value is a function of the property’s distance from the city center, the type of terrain, the nearby pollution, and the crime rate. Again, though, players will likely discover this for themselves, even if they don’t read the manual, which spells out the formula, explicitly telling us that “the land value of an area is based on terrain, accessibility, pollution, and distance to downtown.”
So there’s an interesting puzzle I’m trying to get at here. How does looking at the code teach us something new? If the manual describes the process, and the game enacts it, what does exploring the code do?
I think back to Sherry Turkle’s now classic work, Life on the Screen, about the relationship between identity formation and what we would now call social media. Turkle spends a great deal of time talking about what she calls, in a Baudrillardian fashion, the “seduction of the simulation.” And by simulations Turkle has in mind exactly what I’m talking about here, the Maxis games like SimCity, SimLife, and SimAnt that were so popular 15 years ago.
Turkle suggests that players can, on the one hand, surrender themselves totally to the simulation, openly accepting whatever processes are modeled within. On the other hand, players can reject the simulation entirely—what Turkle calls “simulation denial.” These are stark opposites, and our reaction to simulations obviously need not be entirely one or the other.
There’s a third alternative Turkle proposes: understanding the simulation, exploring its assumptions, both procedural and cultural (Turkle 71-72).
I’d argue that the close reading of code adds a fourth possibility, a fourth response to a simulation. Instead of surrendering to it, or rejecting it, or understanding it, we can deconstruct it. Take it apart. Open up the black box. See all the pieces and how they fit together. Even tweak the code ourselves and recompile it with our own algorithms inside.
When we crack open the code like this, we may well find surprises that playing the game or reading the manual will not tell us. Remember, code does what it says, but it also says things it does not do. Let’s consider the code for a file called disasters.cpp. Anyone with a passing familiarity with SimCity might be able to guess what a file called disasters.cpp does. It’s the routine that determines which random disasters will strike your city. The entire 408 line routine is worth looking at, but what I’ll draw your attention to is the section that begins at line 109, where the probability of the different possible disasters appears:
In the midst of rather generic biblical disasters (you see here there’s a 22% chance of a fire, and a 22% chance of a flood), there is a startling excision of code, the trace of which is only visible in the programmer’s comments. In the original SimCity there was a 1 out of 9 chance that an airplane would crash into the city. After 9/11 this disaster was removed from the code at the request Electronic Arts.
Playing Micropolis, say perhaps as one of the children in the OLPC program, this erasure is something we’d never notice. And we’d never notice because the machine doesn’t notice—it stands outside the procedural rhetoric of the game. It’s only visible when we read the code. And then, it pops, even to non-programmers. We could raise any number of questions about this decision to elide 9/11. There are questions, for example, about the way the code is commented. None of the other disasters have any kind of contextual, historically-rooted comments, the effect of which is that the other disasters are naturalized—even the human-made disasters like Godzilla-like monster that terrorizes an over-polluted city.
There are questions about the relationship between simulation, disaster, and history that call to mind Don DeLillo’s White Noise, where one character tells another, “The more we rehearse disaster, the safer we’ll be from the real thing…..There is no substitute for a planned simulation” (196).
And finally there are questions about corporate influence and censorship—was EA’s request to remove the airplane crash really a request, or more of a condition? How does this relate to EA’s more recent decision in October of 2010 to remove the Taliban from its most recent version of Medal of Honor? If you don’t know, a controversy erupted last fall when word leaked out that Medal of Honor players would be able to assume the role of the Taliban in the multiplayer game. After weeks of holding out, EA ended up changing all references to the Taliban to the unimaginative “Opposing Force.” So at least twice, EA, and by proxy, the videogame industry in general, has erased history, making it more palatable, or as a cynic might see it, more marketable.
I want to close by circling back to Michael Mateas’s idea of procedural literacy. My commitment to critical code studies is ultimately pedagogical as much as it is methodological. I’m interested in how we can teach everyday people, and in particular, nonprogramming undergraduate students, procedural literacy. I think these pieces of code from Micropolis make excellent material for novices, and in fact, I do have my videogame studies students dig around in this source code. Most of them have never programmed, let alone in C++, so I give them some prompts to get them started.
And for you today, here in the audience, I have similar questions, about the snippets of code that I showed, but also questions more generally about close reading digital objects. What other approaches are worth taking? What other games, simulations, or applications have the source available for study, and what might you want to look at with those programs? And finally, what are the limits of reading code from a humanist perspective?
My head is buzzing from the one-day Archiving Social Media workshop organized by the Center for History and New Media at George Mason University and our close neighbor, the University of Mary Washington. The workshop wrapped upon only a few hours ago, but I’m already feeling a need to synthesize some thoughts about archives, social media, and the humanities. And I know I won’t have time in the next day or two to do this, so I’m taking a moment to synthesize a single thought.
And it is this: we need a politics and poetics of the digital archive. We need a politics and poetics of the social media archive.
Much work has been done on the poetics of traditional archives—Carolyn Steedman’s Dust comes to mind—and there’s emerging political work on social media archives. But there is no deliberate attempt by humanists to understand and articulate the poetics of the social media archive.
And this is exactly what humanists should be doing. Matthew Kirschenbaum asked today, incisively, what can humanists bring to discussions about social media and archives. My answer is this: we don’t need to design new tools, create new implementation plans, or debate practical use issues. We need to think through social media archives and think through the poetics of these archives. We need to discern and articulate the social meaning of social archives. That’s what humanists can do.
Over a period of a few days last week I posted a series of updates onto Twitter that, taken together, added up to less than twenty words. I dragged out across fourteen tweets what could easily fit within one. And instead of text alone, I relied on a combination words and images. I’m calling this elongated, distributed form of social media artisanal tweeting. Maybe you could call it slow tweeting. I think some of my readers simply called it frustrating or even worthless.
If you missed the original sequence of updates as they unfolded online, you can approximate the experience in this thinly annotated chronological trail.
I’m not yet ready to discuss the layers of meaning I was attempting to evoke, but I am ready to piece the whole thing together—which, as befits my theme, actually destroys much of the original meaning. Nonetheless, here it is:
This is the first academic semester in which students have been using the revised 7th edition of the MLA Handbook (you know, that painfully organized book that prescribes the proper citation method for material like “an article in a microform collection of articles”).
From the moment I got my copy of the handbook in May 2009, I have been skeptical of some of the “features” of the new guidelines, and I began voicing my concerns on Twitter:
But not only does the MLA seem unprepared for the new texts we in the humanities study, the association actually took a step backward when it comes to locating, citing, and cataloging digital resources. According to the new rules, URLs are gone, no longer “needed” in citations. How could one not see that these new guidelines were remarkably misguided?
To the many incredulous readers on Twitter who were likewise confused by the MLA’s insistence that URLs no longer matter, I responded, “I guess they think Google is a fine replacement.” Sure, e-journal articles can have cumbersome web addresses, three lines long, but as I argued at the time, “If there’s a persistent URL, cite it.”
Now, after reading a batch of undergraduate final papers that used the MLA’s new citation guidelines, I have to say that I hate them even more than I thought I would. Although “hate” isn’t quite the right word, because that verb implies a subjective reaction. In truth, objectively speaking, the new MLA system fails.
The MLA apparently believes that all texts are the same
In a strange move for a group of people who devote their lives to studying the unique properties of printed words and images, the Modern Language Association apparently believes that all texts are the same. That it doesn’t matter what digital archive or website a specific document came from. All that is necessary is to declare “Web” in the citation, and everyone will know exactly which version of which document you’re talking about, not to mention any relevant paratextual material surrounding the document, such as banner ads, comments, pingbacks, and so on.
The MLA turns out to be extremely shortsighted in its efforts to think “digitally.” The outwardly same document (same title, same author) may in fact be very different depending upon its source. Anyone working with text archives (think back to the days of FAQs on Gopher) knows that there can be multiple variations of the same “document.” (And I won’t even mention old timey archives like the Short Title Catalogue, where the same 15th century title may in fact reflect several different versions.)
The MLA’s new guidelines efface these nuances, suggesting that the contexts of an archive are irrelevant. It’s the Ghost of New Criticism, a war of words upon history, “simplification” in the name of historiographic homicide.
Below are all of the upcoming 2009 MLA sessions related to new media and the digital humanities. Am I missing something? Let me know in the comments and I’ll add it to the list. You may also be interested in following the Digital Humanities/MLA list on Twitter. (And if you are on Twitter and going to the MLA, let Bethany Nowviskie know, and she’ll add you to the list.)
MONDAY, DECEMBER 28
116. Play the Movie: Computer Games and the Cinematic Turn
8:30–9:45 a.m., 411–412, Philadelphia Marriott
Presiding: Anna Everett, Univ. of California, Santa Barbara; Homay King, Bryn Mawr Coll.
“The Flaneur and the Space Marine: Temporal Distention in First-Person Shooters,” Jeff Rush, Temple Univ., Philadelphia
“Viral Play: Internet Humor, Viral Marketing, and the Ubiquitous Gaming of The Dark Knight,” Ethan Tussey, Univ. of California, Santa Barbara
“Playing the Cut Scene: Agency and Vision in Shadow of the Colossus,” Mark L. Sample, George Mason Univ.
“Suture and Play: Machinima as Critical Intimacy for Game Studies,” Aubrey Anable, Hamilton Coll.
120. Virtual Worlds and Pedagogy
8:30–9:45 a.m., Liberty Ballroom Salon C, Philadelphia Marriott
Presiding: Gloria B. Clark, Penn State Univ., Harrisburg
“Rhetorical Peaks,” Matt King, Univ. of Texas, Austin
“Virtual Theater History: Teaching with Theatron,” Mark Childs, Warwick Univ.; Katherine A. Rowe, Bryn Mawr Coll.
“Realms of Possibility: Understanding the Role of Multiuser Virtual Environments in Foreign Language Curricula,” Julie M. Sykes, Univ. of New Mexico
“Information versus Content: Second Life in the Literature Classroom,” Bola C. King, Univ. of California, Santa Barbara
“Literature Alive,” Beth Ritter-Guth, Hotchkiss School
“Virtual World Building as Collaborative Knowledge Production: The Online Crystal Palace,” Victoria E. Szabo, Duke Univ.
“Teaching in Virtual Worlds: Re-Creating The House of Seven Gables in Second Life,” Mary McAleer Balkun, Seton Hall Univ.
“3-D Interactive Multimodal Literacy and Avatar Chat in a College Writing Class,” Jerome Bump, Univ. of Texas, Austin
8:30–9:45 a.m., Liberty Ballroom Salon A, Philadelphia Marriott
“‘A Breach, [and] an Expansion’: The Humanities and Digital Media,” Dene M. Grigar, Washington State Univ., Vancouver
“Locating the Literary in New Media: From Key Words and Metatags to Network Recognition and Institutional Accreditation,” Joseph Paul Tabbi, Univ. of Illinois, Chicago
“Digital, Banal, Residual, Experimental,” Paul Benzon, Rutgers Univ., New Brunswick
“Genre Discovery: Literature and Shared Data Exploration,” Jeremy Douglass, Univ. of California, San Diego
170. Value Added: The Shape of the E-Journal
10:15–11:30 a.m., Liberty Ballroom Salon C, Philadelphia Marriott
212. Language Theory and New Communications Technologies
12:00 noon–1:15 p.m., Jefferson, Loews
Presiding: David Herman, Ohio State Univ., Columbus
“Learning around Place: Language Acquisition and Location-Based Technologies,” Armanda Lewis, New York Univ.
“Constructing the Digital I: Subjectivity in New Media Composing,” Jill Belli, Graduate Center, City Univ. of New York
“French and Spanish Second-Person Pronoun Use in Computer-Mediated Communication,” Lee B. Abraham, Villanova Univ.; Lawrence Williams, Univ. of North Texas
245. Old Media and Digital Culture
1:45–3:00 p.m., Washington C, Loews
Presiding: Reinaldo Carlos Laddaga, Univ. of Pennsylvania
“Paper: The Twenty-First-Century Novel,” Jessica Pressman, Yale Univ.
“First Publish, Then Write,” Craig Epplin, Reed Coll.
“Digital Literature and the Brazilian Historic Avant-Garde: What Is Old in the New?” Eduardo Ledesma, Harvard Univ.
264. Media Studies and the Digital Scholarly Present
1:45–3:00 p.m., 411–412, Philadelphia Marriott
Presiding: Kathleen Fitzpatrick, Pomona Coll.
“Blogging, Scholarship, and the Networked Public Sphere,” Chuck Tryon, Fayetteville State Univ.
“The Decline of the Author, the Rise of the Janitor,” David Parry, Univ. of Texas, Dallas
“Remixing Dada Poetry in MySpace: An Electronic Edition of Poetry by the Baronness Elsa von Freytag-Loringhoven in N-Dimensional Space,” Tanya Clement, Univ. of Maryland, College Park
“Right Now: Media Studies Scholarship and the Quantitative Turn,” Jeremy Douglass, Univ. of California, San Diego
265. Getting Funded in the Humanities: An NEH Workshop
1:45–3:45 p.m., Liberty Ballroom Salon A, Philadelphia Marriott
Presiding: John David Cox, National Endowment for the Humanities; Jason C. Rhody, National Endowment for the Humanities
This workshop will highlight recent awards and outline current funding opportunities. In addition to emphasizing grant programs that support individual and collaborative research and education, this workshop will include information on new developments such as the NEH’s Office of Digital Humanities. A question-and-answer period will follow.
268. Lives in New Media
3:30–4:45 p.m., 305–306, Philadelphia Marriott
Presiding: William Craig Howes, Univ. of Hawai‘i, Mānoa
“Blogging the Pain: Disease and Grief on the Internet,” Bärbel Höttges, Univ. of Mainz
“New Media and the Creation of Autistic Identities,” Ann Jurecic, Rutgers Univ., New Brunswick
“‘25 Random Things about Me’: Facebook and the Art of the Autobiographical List,” Theresa A. Kulbaga, Miami Univ., Hamilton
322. Looking for Whitman: A Cross-Campus Experiment in Digital Pedagogy
7:15–8:30 p.m., 410, Philadelphia Marriott
Presiding: Matthew K. Gold, New York City Coll. of Tech., City Univ. of New York
Speakers: D. Brady Earnhart, Univ. of Mary Washington; Matthew K. Gold; James Groom, Univ. of Mary Washington; Tyler Brent Hoffman, Rutgers Univ., Camden; Karen Karbiener, New York Univ.; Mara Noelle Scanlon, Univ. of Mary Washington; Carol J. Singley, Rutgers Univ., Camden
7:15–8:30 p.m., Liberty Ballroom Salon C, Philadelphia Marriott
Presiding: Bruce R. Smith, Univ. of Southern California
“English Broadside Ballad Archive: A Digital Home for the Homeless Broadside Ballad,” Patricia Fumerton, Univ. of California, Santa Barbara; Carl Stahmer, Univ. of Maryland, College Park
“The Total (Digital) Archive: Collecting Knowledge in Online Environments,” Katherine D. Harris, San José State Univ.
“Displacing ‘Shakespeare’ in the World Shakespeare Encyclopedia,” Katherine A. Rowe, Bryn Mawr Coll.
TUESDAY, DECEMBER 29
361. Making Research: Limits and Barriers in the Age of Digital Reproduction
8:30–9:45 a.m., 411–412, Philadelphia Marriott
Presiding: Robin G. Schulze, Penn State Univ., University Park
“The History and Limitations of Digitalization,” William Baker, Northern Illinois Univ.
“Moving Past the Hype of Hypertext: Limits of Scholarly Digital Ventures,” Elizabeth Vincelette, Old Dominion Univ.
“Transforming the Study of Australian Literature through a Collaborative eResearch Environment,” Kerry Kilner, Univ. of Queensland
4. “A Proposed Model for Peer Review of Online Publications,” Jan Pridmore, Boston Univ.
413. Has Comp Moved Away from the Humanities? What’s Lost? What’s Gained?
10:15–11:30 a.m., 411–412, Philadelphia Marriott
Presiding: Krista L. Ratcliffe, Marquette Univ.
“Turning Composition toward Sovereignty,” John L. Schilb, Indiana Univ., Bloomington
“Composition and the Preservation of Rhetorical Traditions in a Global Context,” Arabella Lyon, Univ. at Buffalo, State Univ. of New York
“What Composition Can Learn from the Digital Humanities,” Olin Bjork, Georgia Inst. of Tech.; John Pedro Schwartz, American Univ. of Beirut
490. Links and Kinks in the Chain: Collaboration in the Digital Humanities
1:45–3:00 p.m., 410, Philadelphia Marriott
Presiding: Tanya Clement, Univ. of Maryland, College Park
Speakers: Jason B. Jones, Central Connecticut State Univ.; Laura C. Mandell, Miami Univ., Oxford; Bethany Nowviskie, Univ. of Virginia; Timothy B. Powell, Univ. of Pennsylvania; Jason C. Rhody, National Endowment for the Humanities
512. Journal Ranking, Reviewing, and Promotion in the Age of New Media
3:30–4:45 p.m., Liberty Ballroom Salon C, Philadelphia Marriott
Presiding: Meta DuEwa Jones, Univ. of Texas, Austin
Speakers: Daniel Brewer, L’Esprit Créateur; Mária Minich Brewer, L’Esprit Créateur; Martha J. Cutter, MELUS; Mike King, New York Review of Books; Joycelyn K. Moody, African American Review; Bonnie Wheeler, Council of Editors of Learned Journals
560. (Re)Framing Transmedial Narratives
7:15–8:30 p.m., Congress A, Loews
Presiding: Marc Ruppel, Univ. of Maryland, College Park
“From Narrative, Game, and Media Studies to Transmodiology,” Christy Dena, Univ. of Sydney
“To See a Universe in the Spaces In Between: Migratory Cues and New Narrative Ontologies,” Marc Ruppel
“Works as Sites of Struggle: Negotiating Narrative in Cross-Media Artifacts,” Burcu S. Bakioglu, Indiana Univ., Bloomington
575. Gaining a Public Voice: Alternative Genres of Publication for Graduate Students
7:15-8:30 p.m., Room 405, Philadelphia Marriott
Presiding: Jens Kugele, Georgetown Univ.
“Animating Audiences: Digital Publication Projects and Their Publics,” Jentery Sayers, Univ. of Washington, Seattle
“Blogging Beowulf,” Mary Kate Hurley, Columbia Univ.
“Hope Is Not a Husk but Persists in and as Us: A Proposal for Graduate Collaborative Publication,” Emily Carr, Univ. of Calgary
“The Alternative as Mainstream: Building Bridges,” Katherine Marie Arens, Univ. of Texas, Austin
WEDNESDAY, DECEMBER 30
625. Making Research: Collaboration and Change in the Age of Digital Reproduction
8:30–9:45 a.m., Grand Ballroom Salon L, Philadelphia Marriott
Presiding: Maura Carey Ives, Texas A&M Univ., College Station
“What Is Digital Scholarship? The Example of NINES,” Andrew M. Stauffer, Univ. of Virginia
“Critical Text Mining; or, Reading Differently,” Matthew Wilkens, Rice Univ.
“‘The Apex of Hipster XML GeekDOM’: Using a TEI-Encoded Dylan to Help Understand the Scope of an Evolving Community in Digital Literary Studies,” Lynne Siemens, Univ. of Victoria; Raymond G. Siemens, Univ. of Victoria
632. Quotation, Sampling, and Appropriation in Audiovisual Production
8:30–9:45 a.m., 406, Philadelphia Marriott
Presiding: Nora M. Alter, Univ. of Florida; Paul D. Young, Vanderbilt Univ.
“‘We the People’: Imagining Communities in Dave Chappelle’s Block Party,” Badi Sahar Ahad, Loyola Univ., Chicago
“Pinning Down the Pinup: The Revival of Vintage Sexuality in Film, Television, and New Media,” Mabel Rosenheck, Univ. of Texas, Austin
“Playful Quotations,” Lin Zou, Indiana Univ., Bloomington
“For the Record: The DJ Is a Critic, ‘Constructing a Sort of Argument,’” Mark McCutcheon, Athabasca Univ.
643. New Models of Authorship
8:30–9:45 a.m., Grand Ballroom Salon K, Philadelphia Marriott
Presiding: Carolyn Guertin, Univ. of Texas, Arlington
“Authors for Hire: Branded Entertainment’s Challenges to Legal Doctrine and Literary Theory,” Zahr Said Stauffer, Univ. of Virginia
“The Digital Archive in Motion: Data Mining as Authorship,” Paul Benzon, Temple Univ., Philadelphia
“Scandalous Searches: Rhizomatic Authorship in America’s Online Unintentional Narratives,” Andrew Ferguson, Univ. of Tulsa
“Ning: Teaching Writing to the Net Generation,” Nathalie Ettzevoglou, Univ. of Connecticut, Storrs; Jessica McBride, Univ. of Connecticut, Storrs
“Online Tutoring from the Ground Up,” William L. Magrino, Jr., Indiana Univ. of Pennsylvania; Peter B. Sorrell, Rutgers Univ., New Brunswick
“Using Facebook for Online Discussion in the Literature Classroom,” Emily Meyers, Univ. of Oregon
676. The Impact of Obama’s Rhetorical Strategies
12:00 noon–1:15 p.m., Grand Ballroom Salon K, Philadelphia Marriott
Presiding: Linda Adler-Kassner, Eastern Michigan Univ.
“Keeping Pace with Obama’s Rhetoric: Digital Ecologies in the Writing Program and the White House,” Shawn Casey, Ohio State Univ., Columbus
“Classroom 2.0 Connecting with the Digital Generation: Pedagogical Applications of Barack Obama’s Rhetorical Use of Twitter,” Jeff Swift, Brigham Young Univ., UT
“Obama Online: Using the White House as an Exemplar for Writing Instruction,” Elizabeth Mathews Losh, Univ. of California, Irvine
“Made Not Only in Words: The Politics and Rhetoric of Barack Obama’s New Media Presidency as a Moment for Uniting Civic Rhetoric and Civic Engagement,” Michael X. Delli Carpini, Univ. of Pennsylvania; Dominic DelliCarpini, York Coll. of Pennsylvania
Respondent: Linda Adler-Kassner
703. Teaching Literature by Integrating Technology
12:00 noon–1:15 p.m., Commonwealth Hall A1, Loews
Presiding: Peter Höyng, Emory Univ.
“Tatort Technology: Teaching German Crime Novels,” Christina Frei, Univ. of Pennsylvania
“Old Meets New: Teaching Fairy Tales by Using Technology,” Angelika N. Kraemer, Michigan State Univ.
“The Role of E-Learning in Excellence Initiatives: Ideal Scenarios and Practical Limitations,” David James Prickett, Humboldt-Universität
Respondent: Caroline Schaumann, Emory Univ.
706. Digital Africana Studies: Creating Community and Bridging the Gap between Africana Studies and Other Disciplines
12:00 noon–1:15 p.m., Adams, Loews
Presiding: Zita Nunes, Univ. of Maryland, College Park
Speakers: Kalia Brooks, Inst. for Doctoral Studies in the Visual Arts; Bryan Carter, Univ. of Central Missouri; Kara Keeling, Univ. of Southern California
Every six months or so it seems as if the entire Internet discovers for the first time that people are making data visualizations of the Choose Your Own Adventure books that were popular in the early eighties. Computer scientist Christian Swinehart’s stunning visualizations are only the most recent to capture the imagination of scores of old fans, academics, and data fanatics.
Here then is a brief history of these CYOA maps:
September 2003 Andrew Stern maps a CYOA-inspired book (Night of a Thousand Boyfriends) on the group-blog Grand Text Auto. As far as I can determine, Stern’s is the ur-map, the CYOA map that started it all. Stern modestly calls his rudimentary hand-drawn map “a fun exercise,” but as the CYOA visualizations he inspired increase in complexity over time, Stern’s map is revealed to be visionary.
April 2004 Inspired directly by Stern, Matthew Kirschenbaum assigns a CYOA mapping assignment to undergraduate students in his Computer and Text course at the University of Maryland. One of Matt’s goals is to test the assumption that electronic literature is “simply a souped-up version of CYOA.”
December 2004 Greg Lord, one of Kirschenbaum’s students from the Fall 2004 section of Computer and Text, creates an interactive map of The Third Planet from Altair (CYOA #7). It is the most visually sophisticated map so far, and Lord’s analysis of the book’s various kinds of paths is especially thoughtful.
September 2005 I borrow Kirschenbaum’s assignment and revise it for a class at George Mason University on new media. As an example for my students, I map the first book in the series, The Cave of Time (CYOA #1). My own interest in the mapping of these books lies in the moral structure embedded within the novels, in which certain choices are rewarded and others are not. I’m also fascinated by the assumptions the books make about what constitutes a failed or satisfying ending.
March 2008 Sean Ragan turns The Mystery of Chimney Rock (CYOA #5) into a directed graph. Ragan uses AT&T’s open source Graphviz software for his map, which takes a simple text file of options (e.g. “3 -> 4, 3-> 6) and compiles them into a diagram.
September 2008 My GMU students map CYOA books for a class on ergodic literature (ergodic: a neologism coined by Espen Aarseth to describe literature that requires non-trivial choices from the reader). The assignment is a revision of the September 2005 assignment, and I connect it to Franco Moretti’s idea of a “distant reading” of literature.
July 2009 Designer Michael Niggel creates an analysis of paths and outcomes of Journey Under the Sea (CYOA #2). Niggel finds that over 75 percent of the book’s endings are unfavorable (50 percent will actually end in death).
November 2009 Christian Swinehart offers multiple data views of twelve CYOA books, a project that took 13 months to complete. Swinehart’s project is in effect a longitudinal study of CYOA’s evolution, showing that later books were more linear and offered fewer endings.
Conclusions?
Given the recurring interest in these maps from both literature professors and computer scientists, I imagine we haven’t seen the last of these maps. I also imagine the trend to treat CYOA books as data sets will intensify. And as data sets, they can be manipulated in novel and ingenious ways, in which subtle patterns can be extracted, patterns which may tell us a great deal about what we humans like and don’t like in the stories we tell ourselves about ourselves.
Last spring I participated in an interdisciplinary symposium called Unthinking Television: Visual Culture[s] Beyond the Console. I was an invited guest on a roundtable devoted to the vague idea of “Screen Life.” I wasn’t sure what that phrase meant at the time, and I still don’t know. But I thought I’d go ahead and share what I saw then — and still see now — as four trends in what we might call the infrastructure of screens.
Moving from obvious to less obvious, these four emergent structural changes are:
Proliferating screens
Bigger is better and so is smaller
Screens aren’t just to look at it
Our screens are watching us
And a few more details about each development:
1. Proliferating screens
I can watch episodes of The Office on my PDA, my cell phone, my mp3 player, my laptop, and even on occasion, my television.
2. Bigger is better and so is smaller
There is a much greater range in sizes of screens that we encounter on a daily basis. My high definition videocamera has a 2″ screen and I can hook that up directly via HDMI cable to my 36″ flat screen, and there are screen sizes everywhere in between and beyond.
3. Screens aren’t just to look at
We now touch our screens. Tactile response will soon be just as important as video resolution.
4. Our screens are watching us
Distribution networks like Tivo, Dish, and Comcast have long had unobtrusive ways to track what we’re watching, or at least what our televisions were tuned to. But now screens can actually look at us. I’m referring to screens that aware of us, of our movements. The most obvious example is the Wii and its use of IR emitters in its sensor bar to triangulate the position of the Wiimote, and hence, the player. GE’s website has been showcasing an interactive hologram that uses a webcam. In both cases, the screen sees us. I think this is potentially the biggest shift in what it means to have a “screen life.” In this trend and my previous trend concerning the new haptic nature of screens, we are completing a circuit that runs between human and machine, machine and human.
One of the more brilliant works of electronic literature I savor teaching is Brian Kim Stefan’s Star Wars, One Letter at a Time, which is exactly what it sounds like. Aside what’s going on in the piece itself (which deserves its own separate blog post), what I enjoy is the almost violent reaction it provokes in students. Undergraduate and graduate students alike are incredibly resistant to SWOLAAT, in most cases flat-out denying any claims Stefan’s reworking of Star Wars might make toward literariness.
The dismissive response of my students to SWOLAAT is only the most extreme example of what happens with many pieces of electronic literature, both in my classroom and in the wider world. For example, I’ve been reading through Johanna Drucker’s review of Matthew Kirschenbaum’s groundbreaking Mechanisms, as well as the e-lit community’s reaction to her statement that no works have “appeared in digital media whose interest goes beyond novelty value.” A bit aghast at Drucker’s remark, Noah Wardrip-Fruin and Scott Rettberg have both responded, and I was struck by Rettberg’s observation that
ELO [The Electronic Literature Organization] has submitted a number of very good digital humanities grant proposals to the NEH, and we have had the same response nearly every time — on a panel of three reviewers, two will find the proposal worth funding, and one of whom will state flatly that it has no merit, not on the basis of the proposal itself or its relevance to the call, but because they find electronic literature itself to be without merit.
It occurred to me recently that the denial of electronic literature’s literary merit — whether it’s coming from my students or a distinguished NEH panel — is not due to a misplaced desire to preserve the sanctity of what counts as literature as it is sheer xenophobia.
Electronic literature is a foreign land.
Electronic literature might as well be the national literature of Moldavia. To the uninitiated student or scholar, e-lit is at worst strange, incomprehensible, and inscrutable, and at best, simply silly.
So, I’m wondering, would the same process by which a stranger in a strange land grows accustomed to foreignness and even appreciates and incorporates cultural difference into his or her own life — could that process apply to e-lit?
Below (larger image) is a six stage model of intercultural sensitivity, designed by Milton J. Bennett in the late eighties and early nineties to describe the progress of individuals as they experience greater and more frequent cultural difference. And I think this model could help us introduce students to the foreign world of electronic literature.
In the early ethnocentric stages of Bennett’s model, individuals begin by first denying that cultural difference exists in the first place, either because of their own isolation or because of willful ignorance. Greater exposure to cultural difference next prompts a defensive posture, an us-versus-them mentality in which existing cognitive categories are reinforced and any comment directed toward one’s own culture is perceived as an attack. The last ethnocentric stage is characterized by a minimization of difference. Individuals tell themselves that “people are the same everywhere,” a superficially benign attitude that in fact masks uniqueness and still evaluates other cultures from a reference point within one’s own culture. The final three stages are marked by an understanding that behaviors, norms, beliefs and so on are all relative. The first ethnorelative stage is acceptance, genuinely acknowledging cultural difference and seeing that difference within its own cultural context. Next comes adaptation, when individuals change their own attitudes, behaviors, and even language to match their surroundings in an attempt to communicate and empathize. Finally, integration occurs when individuals move freely between cultures, practicing what Bennett calls “constructive marginality,” that is, seeing identity construction as an ongoing process that is always marginal to any specific social group.
If we think of electronic literature as a foreign land, then I propose we use this developmental model to accurately chart a stranger’s encounter with the genre. As my experience with Star Wars, One Letter at a Time illustrates, students first begin reading electronic literature in either the denial or defense stages (meaning they’ve either never experienced e-lit before or they have and they hate it). I can imagine an entire syllabus structured around the goal of moving students from denial to integration. Just as educators and sociologists have come up with practical strategies to facilitate the progress of study abroad students along Bennett’s continuum, so too can we design specific assignments that develop students’ competencies in each of these stages: from a total inability to read the differences between traditional literature and born digital literature to an integration of those very differences into their non-e-lit lives. And with each point in between, we target stage-appropriate skills and practices, meeting the students where they are, rather than expecting them to reflexively appreciate the virtues of something as alien as Reiner Strasser and M.D Coverley’s ii: in the white darkness or something as unsettling as Jason Nelson’s This Is How You Will Die. This type of approach to teaching electronic literature would be far more rewarding (to both the professor and the students) than the kind of sink-or-swim model in Katherine Hayle’s theoretically dense (and unteachable, as I’ve discovered) introduction to Electronic Literature.
Imagine too that we begin writing grant and publishing proposals with these stages in mind, understanding that committees and panels and editors are likely stuck in the ethnocentric stages, judging literature from what we might call the “Great Works” perspective. E-lit challenges this perspective, but not on grounds of literariness; it challenges existing notions of literature simply because it’s different. We can teach sensitivity to difference to our students, and we should model sensitivity in our own writings as well. Teachers and researchers of electronic literature are its ambassadors, and it is up to us to introduce strangers to the medium in a firm, but welcoming, guiding way.
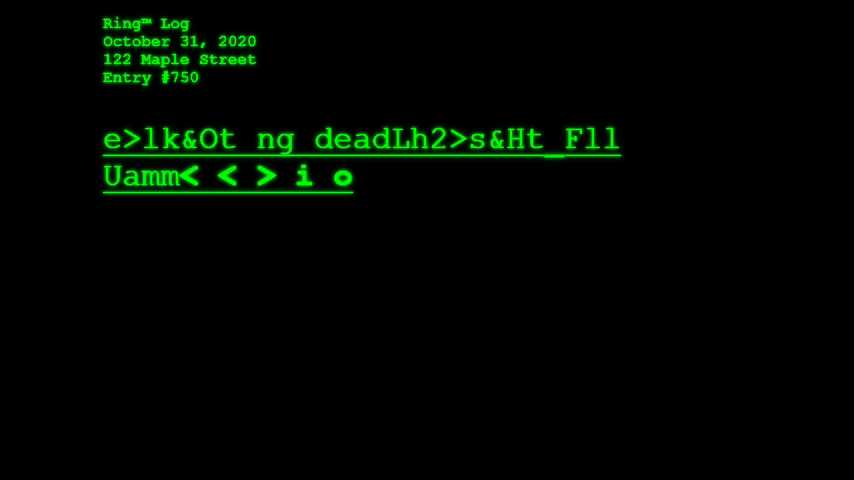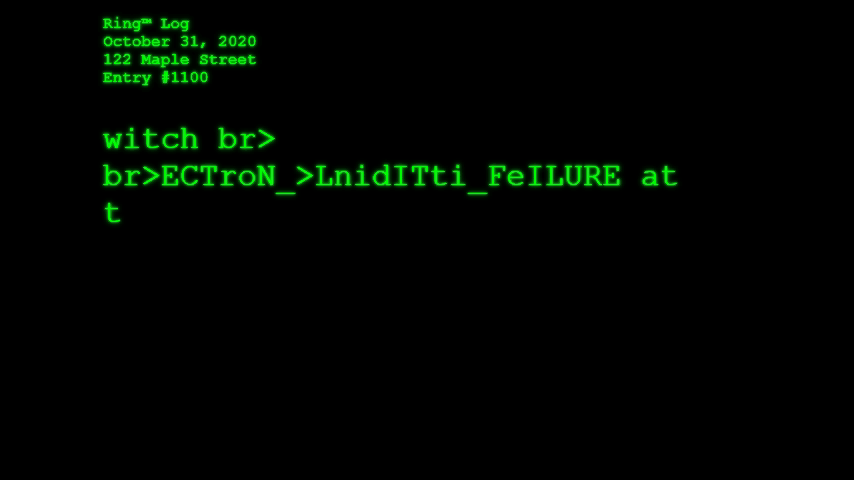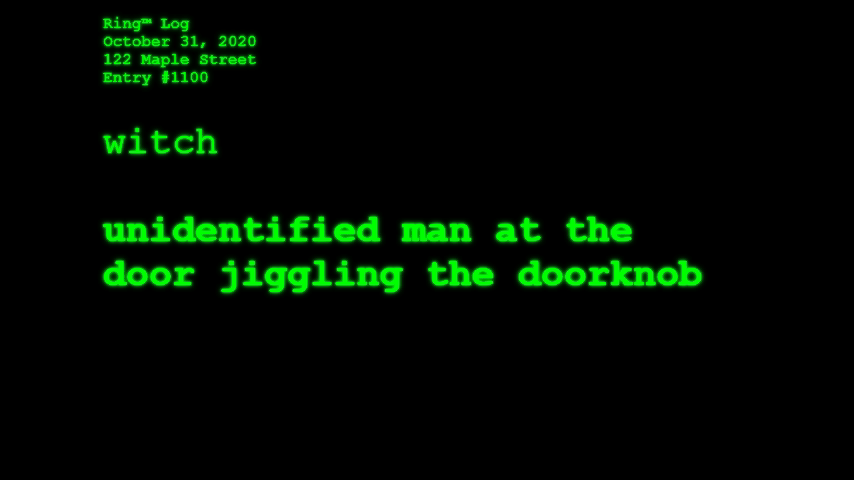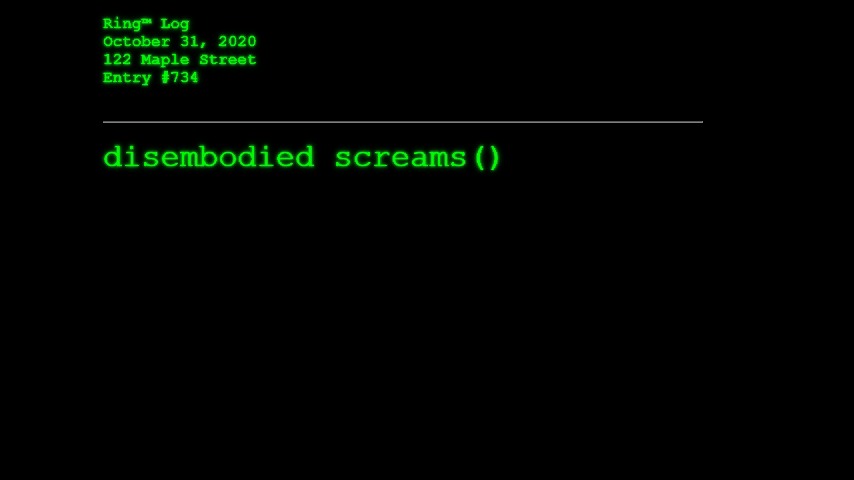







































































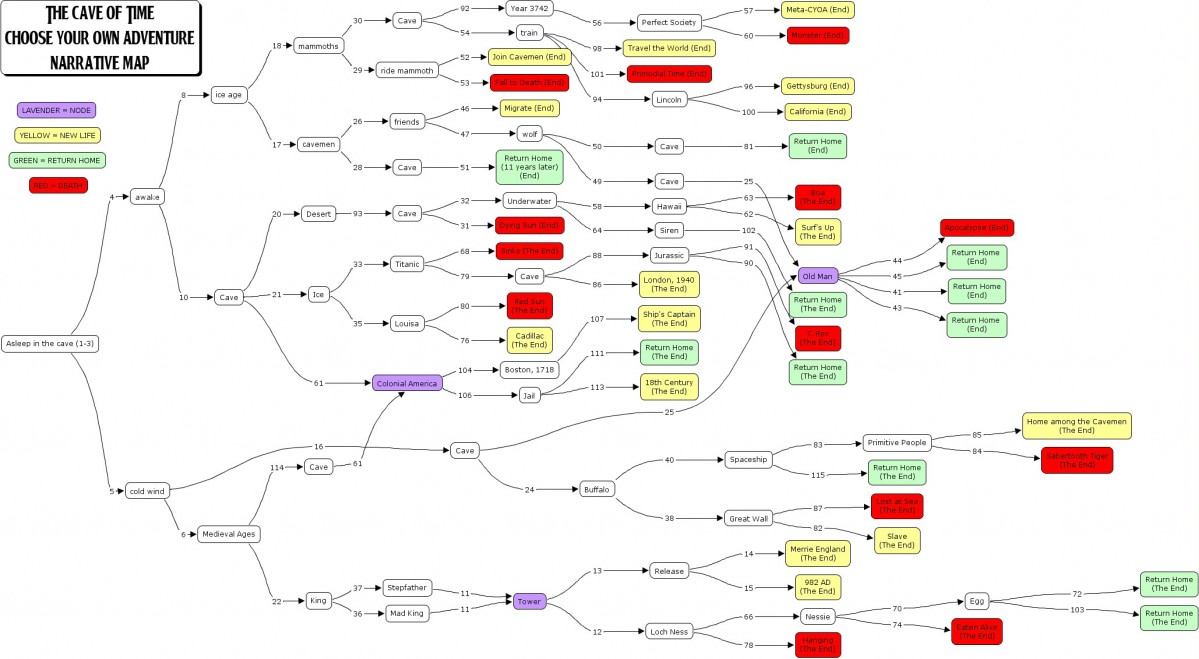{kind=link}