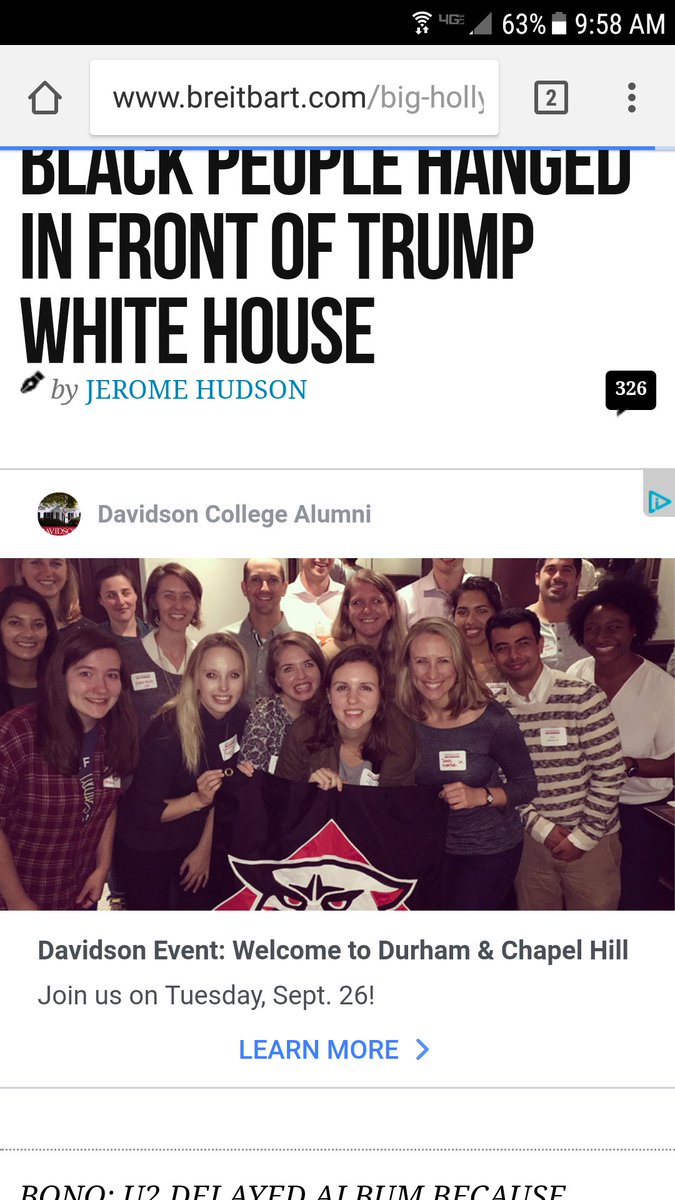
In September 2017, a Davidson College alumna alerted the college via a tweet that the Davidson College Alumni Association was advertising on the alt-right website Breitbart.
A September 2017 ad for the Davidson College Alumni Association on Breitbart.com
The display of promotional material for Davidson College next to the ultra conservative and nativist rhetoric of Breitbart was not only a jarring juxtaposition, it was also completely inadvertent, an algorithmic outcome of Facebook’s advertising platform.
Journalists have recently exposed other disturbing elements of Facebook and Google’s ad networks, such as the explosive ProPublica report that advertisers on Facebook could deliberately reach anti-Semitic audiences using targeted keywords and demographic information from Facebook’s vast data mining operations. Buzzfeed similarly showed how racist advertisers could exploit Google’s ad network.
Clearly, online advertising intersects in compelling—but usually hidden—ways with concerns about justice, equality, and community. Justice, equality, and community (JEC)—these are concepts that define a new JEC graduation requirement at Davidson College. To satisfy this requirement, students must take at least one course that addresses “the manifestations of justice and equality in various communities, locales, nations or regions, and focus on methods and theories used to analyze, spotlight, or remedy instances of injustice and inequality.”
In Spring 2018 I am teaching one such JEC-designated course, Gender and Technology (DIG 340). This course counts toward both Digital Studies and Gender and Sexuality Studies major and minor requirements. Thanks to funding from Davidson’s momentous Justice, Equality, and Community grant from the Mellon Foundation, I am developing an assignment for DIG 340 that allows students to explore, critique, and undermine social media ad platforms.
Quite simply, the assignment is to subvert social media advertising by placing justice, equality, and community-oriented materials in timelines and websites whose users would normally not encounter that material. Imagine, for example, a sponsored ad about Colson Whitehead, Davidson’s 2018 Reynolds speaker, appearing on a white supremacist website. Or #metoo promoted posts showing up on the timelines of so-called Men’s Rights activists.
Working in groups of 3-4, students will manage a JEC-focused ad campaign of their own design on either Facebook, Twitter, or Google’s ad platforms. As students explore the contours, possibilities, and limits of social media advertising, each group will manage a series of campaigns with progressively larger budgets as they fine-tune their message and promotional strategy. Groups will have a budget of only $5 for their first campaigns. But as their campaigns grow more sophisticated, budgets will increase. Groups will have $100 for their final campaigns. All the while students will critically examine the advertising apparatuses themselves, analyzing overt and implicit ideological assumptions built into the platforms. Students will be aided in this process by Sara Wachter-Boettcher’s important new book, Technically Wrong: Sexist Apps, Biased Algorithms, and Other Threats of Toxic Tech (2017).
Our implementation of the assignment is a few months away, and I am eager to hear your ideas about it. Thoughts, comments, suggestions?
A few weeks ago I wrote about studying digital culture through the lens of specific file types. In the fall I’m teaching DIG 101 (Introduction to Digital Studies)—an amorphous course that is part new media studies, part digital humanities, part science and technology studies. I was imagining spending a week on, say, something like GIFs as way to understand Internet culture. My question is, what other file types could be similarly productive to explore?
That short post generated great ideas in the comments, on Facebook, and on Twitter. To make things easier to find again (for me and others), here are just some of the file type ideas that bubbled to the surface:
PDF
As commentator Sam Popowich put it, “love it or hate it” PDFs are everywhere. Ryan Cordell pointed out that Lisa Gitelman has a chapter devoted to PDFs in Paper Knowledge. Gitelman is exactly the kind of scholar I want undergraduates to read. Clear, perceptive, uncovering seemingly archaic history and showing why it matters.
WAD
Quite a few people suggested WADs, composite files made up sounds, sprites, graphics, level information, and other digital assets for PC games. Doom popularized WADs, but PC games continue to use similar composite files. You can use tools like GCFScape to unpack these files, and they lend themselves to digital forensic lab work in the classroom. Every time I teach Gone Home, for example, students explore unpacked sound and graphic files. It’s an alternative way of experiencing the game. My own research digging to WADS to find misogynistic game developer comments could come into play here too.
JPG
At first I thought studying JPGs would be redundant if GIFs are already on the table. Allison Parrish and Jeff Thompson make a strong case for JPGs though: they organize information differently, compress differently, and of course, are glitchable. Like PDFs, their very ubiquity renders them invisible as file types, especially to students who have grown up carrying a camera with them at all times.
EXIF
Vika Zafrin and Tim Owens recommended EXIF, one of the few file types I hadn’t already considered as a possibility. Technically I guess EXIF is a metadata standard, not a file type per se, but the relationship between metadata and data is crucial to understand, and EXIF can get us there. Plus, we can talk about privacy, tracking, and my colleague Owen Mundy’s fantastic I Know Where Your Cat Lives project.
Stigmatized File Types
@TopLeftBrick mentioned NFO files and Finn Arne Jørgensen brought up .torrent files, both of which belong to the world of pirated games, software, and media. Jason Mittell similarly suggested another what I call stigmatized file type:
.FLV , a hidden file type that allows you to study YouTube.
Before the rise of HTML5, YouTube videos were Flash files (FLV = Flash Video), and there were (and are) tricks to downloading these videos to watch offline. But it was a format you weren’t supposed to encounter; YouTube strove to make streaming seamless, hiding the actual video file. I would love to spend some time in DIG 101 studying all of these stigmatized file types, not so much to understand the technical features of the file formats themselves, but to better understand the cultural rules that influence the circulation of knowledge.
The Big Picture
The above list is certainly incomplete. And leaves off the file types that originally inspired this idea (MP3s, GIFs, HTML, and JSON). But it’s a great start. It’s also important to zoom out and see the big picture. To this end, Amelia Acker pointed me toward this surprisingly philosophical technical report from Microsoft Research: “What is a File?”
Indeed, what is a file and what do they mean is something we’ll be asking in DIG 101.
I am revamping “Introduction to Digital Studies,” my program’s overview of digital culture, creativity, and methodology. One approach is to partially organize the class around file types, the idea being that a close reading of certain file types can help us better understand contemporary culture, both online and off.
It’s a bit like Raymond William’s Keywords, except with file types. A few of the file types that seem especially generative to consider:
MP3 (Jonathan Sterne’s work on MP3s is the gold standard to follow)
GIF (especially the rise and fall and rise of the animated GIF)
HTML (a gateway to understanding the early history and ethos of the web)
JSON (as a way to talk about data and APIs)
This list is just an initial start, of course. What other culturally significant file types would you have students consider? And what undergrad-friendly readings about those file types would you recommend?
Are you sick of parallax scrolling yet? You know, the way the foreground and background on a web page, iPhone screen, or Super Mario Brothers move at different speeds, giving the illusion of depth? Parallax scrolling is a gimmick. Take it away and not much changes. Your videogame might be a tad less immersive, but come on, how immersive was it in the first place? Turn off parallax scrolling on your phone and your battery life might actually improve. Parallax scrolling is ornamental, a hallmark of what will eventually be known as the Baroque Digital Age.
So it’s with hesitation that I’m attempting to recuperate the word parallax here. In my defense I’m using the word metaphorically, to describe a certain kind of hermeneutical approach to textual material.
Here it is: parallax reading, an interpretive maneuver that keeps both close and distant reading in focus at the same time.
If you’re just tuning in to the digital humanities, there’s a pretty much bogus IMHO tension between close and distant reading. Close reading is that thing we were all taught to do in high school English, paying attention to individual words and the subtle nuances of a text. Distant reading zooms out to look at a text—or even better, a massive body of texts—from a distance. In Franco Moretti’s memorable words, distance is “not an obstacle, but a specific form of knowledge: fewer elements, hence a sharper sense of their overall interconnection. Shapes, relations, structures. Patterns.”1
Cool, patterns.
“Parallax reading” is a fancy way of saying why not combine close and distant reading. And to be clear, no one is saying you can’t. Again, it’s a bogus tension, a straw man. I’m not proposing anything new here. I’m just giving it a name. And in a bit, a demo.
A parallax reading is the opposite of the “lenticular logic” that, as Tara McPherson explains, separates the two images on a 3D postcard, making it impossible to see them simultaneously. Whereas lenticular vision flips between two distinct representations, parallax reading holds multiple distances in view at once. Like its visual counterpart, parallax reading conveys a sense of depth. Unlike parallax scrolling, though, this is depth that actually matters, a depth that complicates our understanding of texts.
What would a parallax reading look like?
As a case study let’s look at Theodore Roethke’s poem “My Papa’s Waltz.” Written from the perspective of a young boy, the sixteen line poem captures a possibly tender, possibly terrifying moment, as his boozy father mock waltzes him “off to bed.” The whiskey on his father’s breath makes the boy “dizzy.” His mother looks on, barely tolerating the nonsense. The boy is so small he only comes up to his father’s waist; his dad’s belt buckle scrapes his ear with “every step.” As the boy goes to bed “still clinging” to his father’s shirt it’s not clear whether he’s clinging out of fear or love, or maybe both.
“My Papa’s Waltz” was published in 1942 and by the mid-50s was already widely anthologized. It’s a great poem, and I love teaching it. And so do other people. There’s a lot going on under its deceptively simple surface. In The Literature Workshop (a book every teacher of literature should study), Sheridan Blau uses “My Papa’s Waltz” to confront two questions that often arise in literature classes: where does meaning come from, and how the hell do we know which meaning is the right one?
Blau observes that for twenty years or so he taught “My Papa’s Waltz” and students overwhelmingly read it as nostalgic, the fond recollection of a grown man of his gruff but loving father. Then, sometime in mid-80s, Blau’s students began to read the poem more darkly, a vivid childhood memory about abuse and a dysfunctional family.
What happened? How can the poem mean both things? At this point you might be thinking, ah, so a parallax reading is simply holding two opposing meanings of the poem in place at the same time. This is what sophisticated readers and writers do all the time. For example, Sherman Alexie describes “My Papa’s Waltz” as
incredibly sad and violent, and its sadness and violence is underscored by its gentle rhymes and rhythms. It’s Mother Goose on acid, maybe. I think that its gentle music is a form of denial about the terror contained in the poem, or maybe it’s the way kids think, huh?
A love poem about, as Alexie says later on, “the unpredictability of the alcoholic father.” Two seemingly incompatible interpretations—incompatible, that is, to a naive reader. Is this what I mean by parallax reading? Are two competing perspectives we keep in simultaneous focus what parallax reading is all about?
No!
Embracing ambivalent or contradictory interpretations is nothing new. Hopefully, literary scholars practice this—and teach it—all the time. (If anything, we celebrate ambiguity a little too much, when what the world needs now is some rock solid truth, right?) Anyway, a parallax reading is not about the interpretative outcomes, it’s about the methodological process. It’s about simultaneously negotiating close and distant readings.
Think about “My Papa’s Waltz” from a close reading perspective (the foreground of the parallax). An array of historical evidence might suggest which interpretation of his poem Roethke himself preferred. For example, we could look at drafts of the poem, which indicate several significant revisions. In one draft, the small boy is a girl and the “right ear” scraping a buckle is the less particular “forehead.”
Roethke’s draft of “My Papa’s Waltz.” Courtesy of the Theodore Roethke Manuscripts Collection at the University of Washington in Seattle
Changing the gender of the speaker recasts the the father-son relationship as a father-daughter relationship. We might be less likely to read biographical details of Roethke’s own life into the poem: his father ran a gigantic greenhouse, worked with his hands, and died of cancer when Roethke was 14-years-old. Would any of that matter if the speaker is a girl? Would any of it matter either way?
We could also listen to Roethke’s own delivery of the poem. At least two recordings are available online. One features Roethke reading in a sing-song voice that bears no trace of fear or resentment. Another Roethke reading is somber, the accent on the words “you” in the third stanza and “beat” in the fourth stanza possibly ominous, possibly not.
Or—and this is novel—we could actually read the poem. Here’s what I did last time I taught “My Papa’s Waltz.” (I wasn’t teaching Roethke’s poem per se, I was teaching Blau’s book, in a grad class on the pedagogy of teaching literature.) I’m a fan of reading aloud in class, and that’s what we did. As we read, I asked students to point—literally, point with their index finger—to the words that were most freighted with abuse. “Scraped” and “beat” drew some attention from the students, but invariably the word with the strongest connotation of abuse for the students was “battered.” Roethke uses “battered” to describe the father’s hand—it was “battered on one knuckle”—but students couldn’t help displacing the word onto the small boy himself. It’s as if by metonymical extension the boy too was battered and bruised.
With “battered” coming into focus during our close reading as a key marker of abuse, let’s shift to a distant reading of “My Papa’s Waltz”—the background of the parallax. But how can we zoom out from a single poem? From a distance, what’s there to look at? If one poem is a drop of water, what’s the ocean of words that contains it?
One possible ocean is Google Books. Google ngrams offers a snazzy interface for tracking word frequency over time, based on Google Books’ dataset, a staggering 155 billion words in American English. Since my students found “battered” to be the center of traumatic gravity of “My Papa’s Waltz” I plugged that word into Google ngrams:
Which is honestly not that useful. Ngrams can show the rise and fall of certain terms, but they’re inadequate for more nuanced inquires. There are at least three reasons the Google ngram viewer fails here: (1) Google ngrams limits searches by collocates, that is, immediately preceding and succeeding words; (2) Google ngrams can’t search for parts of speech; and most significantly (3) Google ngrams provides no context for the words—no sentence context, no source context, nothing.
This is where the Corpus of Historical American English (COHA) comes in. COHA is a dataset of 400 million words from 1810 through 2009. Established by Mark Davies at Brigham Young University, COHA includes fiction (including texts from Project Gutenberg, scanned books, and scanned movie scripts) and nonfiction (including scanned newspapers and magazines). COHA is a smaller dataset than Google Books, but it holds several critical advantages over Google Books. You can search for phrases that aren’t necessarily collocated right next to each other. You can specify what part of speech you want to search for. That’s really important if you’re looking for a word like, oh, I don’t know, “trump,” which can be a verb, noun, proper noun, and a few other things. Finally, COHA provides context for its searches.
For the time period of the 1950s, when “My Papa’s Waltz” had already been widely anthologized, COHA includes nearly 12 million words from fiction sources, 5.7 millions words from popular magazines, 3.5 million words from newspapers, and just over 3 million words from nonfiction books. That’s a total of 24 million words from the 1950s, which gives us a representative view of how language was being used across a number of domains at the time. This is the ocean of words that surrounds “My Papa’s Waltz.”
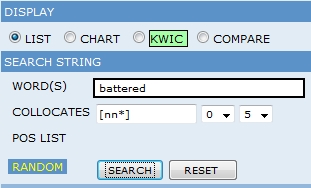
Let’s check out “battered” in COHA, to see how the word was being used during Roethke’s time and afterward.
Here are our search parameters, which tell COHA to find any occurrence of “battered” followed within five words by a noun (that’s the [nn*] in the Collocates box). This search acknowledges that the frequency of “battered” isn’t as important as its context.
Search Window for COHA
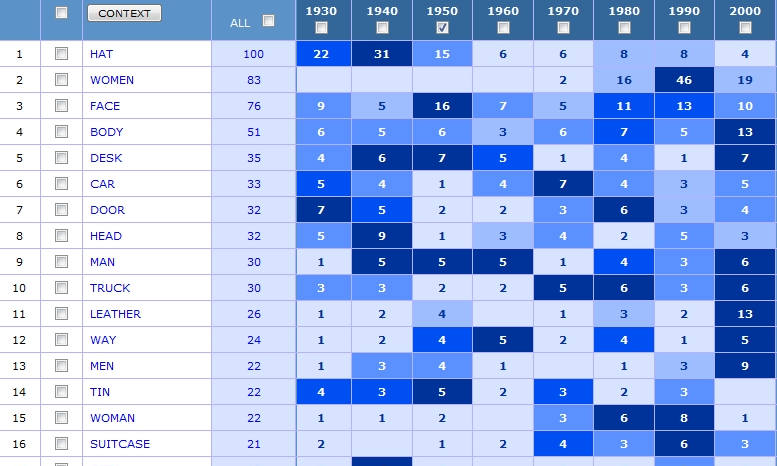
The results are immediately striking. We have the kind of patterns Moretti seeks in distant reading.
“battered” with nn* 0/5
The second most common noun following “battered” is women, as in “battered women.” This frequency would appear to support the idea that “battered” in “My Papa’s Waltz” is an indicator of abuse. At the very least, its appearance is ominous.
Yet dig deeper and notice that the variants of “battered…women” do not become prevalent until 1980 (with 16 occurrences) and peak in the 1990s with 46 occurrences. Prior to 1970, “battered” is rarely used in the context of physical abuse against women.
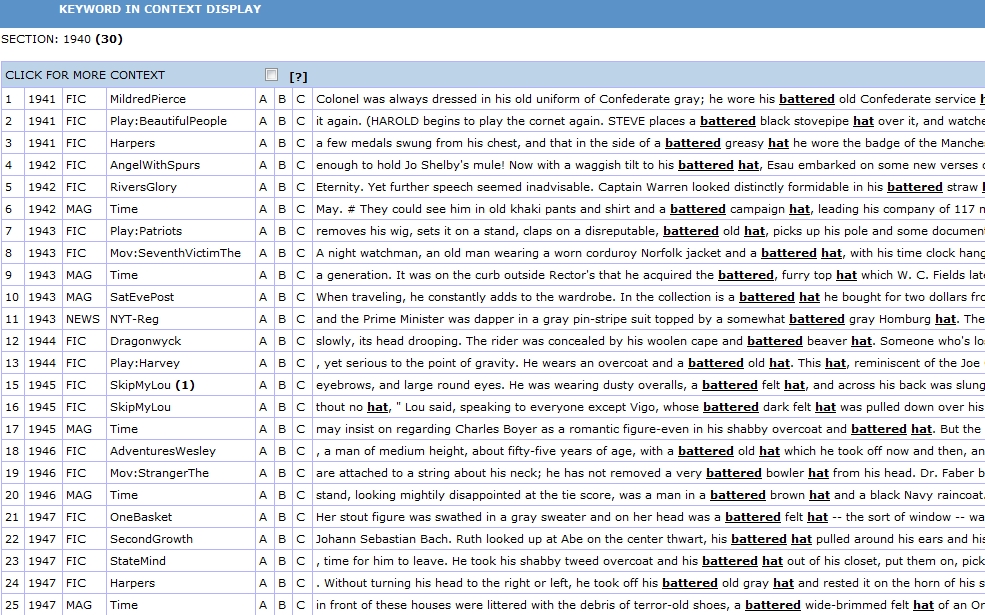
So what does “battered” typically describe when Roethke published the poem in 1942 and in the years immediately afterward? In the 1940s the most common collocate was “hat”: “a battered black stovepipe hat,” “a battered greasy hat,” “his battered hat,” “a disreputable, battered hat”—all uses that suggest a knocked-about, down-on-one’s-luck man. Here’s the KWIC (Keyword In Context) display for “battered…hat” in the 1950s:
“battered…hat” Keyword in Context
And look at the third most common noun associated with “battered.” It’s “face,” peaking in the 1950s. This detail might appear to support the negative interpretation of “My Papa’s Waltz.” But again, look at the keyword in context.
“battered…face” in the 1950s KWIC
The battered face here is predominantly a male face, battered by wind, hard living, and frequently, war. This is likely the kind of “battered” Roethke had in mind when he described the rough hands of the boy’s father in the poem.
Contrast this with how battered appears in the 1990s, when it is associated most frequently with “women”:
“battered…women” in the 1990s Keyword in Context
Here we find “battered” being used the way today’s students would understand the word, associated with the physical abuse of women by men. (Grammar fun: “battered” is technically a participial adjective. It’s an adjective that started out as a participial phrase, but was shortened. Like “there were no shelters for battered women in Michigan” (the first example from the KWIC above) really means “there were no shelters for women who were battered by men in Michigan.” The agent—the men inflicting the battering—drops out of the sentence and we’re left with inexplicably battered women, and no party to take responsibility. Basically it’s passive voice in disguise, a way for abusive men to get off scott-free, linguistically speaking.)
So, a theory: “battered” is what I would call a cusp word—a word teetering on the cusp between two opposing meanings. On one side, the word suggests strength and resilience. It’s gendered masculine in this context. On the other side it suggests helplessness and victimization. It’s gendered female in this case. In other words, once associated with men at the mercy of the elements or men who have endured hardship, “battered” is now associated with women who have suffered—though this part is kept hidden by the participial adjective—at the hands of men.
We still occasionally encounter the older meaning of the word. A line from Leonard Cohen’s “Democracy” (1992) comes to mind:
From the brave, the bold, the battered heart of Chevrolet Democracy is coming to the USA
Here “the battered heart of Chevrolet” is a stand-in for Rust Belt America, the industrial wasteland that left blue collar working men out of work. Or “stiffed,” as Susan Faludi put it in her eponymous diagnosis of 20th century masculinity.2 I’m no sociologist, but it’s not difficult to imagine that “the battered heart of Chevrolet” contributed to a sense of helplessness in men that found expression in violence against women. Emasculated men beating their way to empowerment. Thus battered souls lead to battered bodies.
We can’t know for certain, of course, but it makes sense that Roethke’s description of the father’s hands as “battered” is a kind of tribute to the man. An acknowledgment of hard work and sacrifice. Roethke’s vocabulary was shaped by the Great Depression and World Wars, an era of stoic endurance (even if that stoicism was a myth). People reading the poem today, however, see in “battered” the ugly side of human nature. Desperation, rage, brutality.
In his explanation of his students’ changing interpretation of “My Papa’s Waltz”: Blau suggests that “a change in the culture made a particular reading available that had not been culturally available before.”3 Blau’s exactly right. That shift in meaning began in the 1980s, concomitant with growing social awareness of domestic abuse. What Blau doesn’t say—because the tools weren’t culturally available to him at the time—is that thanks to a distant reading, we can find evidence of that shift within a single word of Roethke’s poem.
What’s important for a parallax reading is that neither foreground nor background disappear entirely. In fact, they only make sense when considered together. That’s where the sense of depth comes from. Armed with knowledge gleaned from distant reading we can go back to the poem and read it again. And maybe, recursively, find other words to track across time, or to contextualize historically. But we always return to the poem.
Will a parallax reading definitively answer the question, what’s “My Papa’s Waltz” about? No. The beauty of literature and language more generally is its ambiguity (argh, though again, maybe we tolerate a little too much ambiguity). But, I have discovered evidence that complicates our interpretation of the poem. At the very least, it should shock us out of our presentist approach to language, assuming the way we use words is the way those words have always been used. And even more importantly, it’s not that I have found answers about the poem. It’s that I found a new way to ask questions.
Notes
Moretti, Franco. “Graphs, Maps, Trees 2: Abstract Models for Literary History.” New Left Review, vol. 26, no. March-April, 2004, p. 94.↩
Faludi, Susan. Stiffed: The Betrayal of the American Man. Harper Perennial, 1999.↩
Blau, Sheridan. The Literature Workshop: Teaching Texts and Their Readers. Heinemann, 2003, p. 73.↩
In anticipation of the upcoming Modern Language Association annual convention, here’s a crowdsourced list of digital humanities sessions at the conference: MLA 2016 Digital Humanities Sessions.
This summer I attended the first annual Institute for Liberal Arts Digital Scholarship (ILiADS) at Hamilton College. It was an inspiring conference, highlighting the importance of collaborative faculty/student digital work at small liberal arts colleges. My own school, Davidson College, had a team at ILiADS (Professor Suzanne Churchill, Instructional Technologist Kristen Eshleman, and undergraduate Andrew Rikard, working on a digital project about the modernist poet Mina Loy). Meanwhile I was at the institute to deliver the keynote address on the final day. Here is the text of my keynote, called “Your Mistake was a Vital Connection: Oblique Strategies for the Digital Humanities.”
Forty years ago, the musician Brian Eno and painter Peter Schmidt published the first edition of what they called Oblique Strategies.Oblique Strategies resembled a deck of playing cards, each card black on one side, and white on the other, with a short aphoristic suggestion on the white side.
Doctorow, Cory. Oblique Strategies Deck, PO Box, The Barbican, London, UK. Photography, June 14, 2013. https://www.flickr.com/photos/doctorow/9041086636/.
These suggestions were the strategies—the oblique strategies—for overcoming creative blocks or artistic challenges. The instructions that came with the cards described their use: “They can be used as a pack…or by drawing a single card from the shuffled pack when a dilemma occurs in a working situation. In this case, the card is trusted even if its appropriateness is quite unclear.”
When we look at some of the strategies from the original deck of 55 cards, we can see why their appropriateness might appear unclear:
From Broackes, Victoria, and Geoffrey Marsh, eds. David Bowie Is… Special edition. London : New York: Victoria & Albert Museum, 2013.
And other strategies:
Make sure nobody wants it.
Cut a vital connection
Make a blank valuable by putting it in an exquisite frame
Do something boring
Honor thy error as a hidden intention
And one of my favorites:
Repetition is a form of change.
Brian Eno explained the origins of the cards in an interview on KPFA radio in San Francisco in 1980: The cards were a system designed to, as Eno put it, “foil the critic” in himself and to “encourage the child.” They were strategies for catching our internal critics off-guard. Eno elaborated:
The Oblique Strategies evolved from me being in a number of working situations when the panic of the situation—particularly in studios—tended to make me quickly forget that there were others ways of working and that there were tangential ways of attacking problems that were in many senses more interesting than the direct head-on approach.
If you’re in a panic, you tend to take the head-on approach because it seems to be the one that’s going to yield the best results. Of course, that often isn’t the case—it’s just the most obvious and—apparently—reliable method. The function of the Oblique Strategies was, initially, to serve as a series of prompts which said, “Don’t forget that you could adopt *this* attitude,” or “Don’t forget you could adopt *that* attitude.”
Other ways of working. There are other ways of working. That’s what the Oblique Strategies remind us. Eno and Schmidt released a second edition in 1978 and a third edition in 1979, the year before Schmidt suddenly died. Each edition varied slightly. New strategies appeared, others were removed or revised.
For example, the 2nd edition saw the addition of “Go outside. Shut the door.” A 5th edition in 2001 added the strategy “Make something implied more definite (reinforce, duplicate).” For a complete history of the various editions, check out Gregory Taylor’s indispensable Obliquely Stratigraphic Record. The cards—though issued in limited, numbered, editions—were legendary, and even more to the point, they were actually used.
David Bowie famously kept a deck of the cards on hand when he recorded his Berlin albums of the late seventies. His producer for these experimental albums was none other than Brian Eno. I’m embarrassed to say that I didn’t know about Bowie’s use of the Oblique Strategies
I knew about Tristan Tzara’s suggestion in the 1920s to write poetry by pulling words out of a bag. I knew about Brion Gysin’s cut-up method, which profoundly influenced William Burroughs. I knew about John Cage’s experimental compositions, such as his Motor Vehicle Sundown, a piece orchestrated by “any number of vehicles arranged outdoors.” Or Cage’s use of chance operations, in which lists of random numbers from Bell Labs determined musical elements like pitch, amplitude, and duration. I knew how Jackson Mac Low similarly used random numbers to generate his poetry, in particular relying on a book called A Million Random Digits with 100,000 Normal Deviates to supply him with the random numbers (Zweig 85).
RAND Corporation. A Million Random Digits with 100,000 Normal Deviates, 1955. http://www.rand.org/pubs/monograph_reports/MR1418/index2.html.
I knew about the poet Alison Knowles’ “The House of Dust,” which is a kind of computer-generated cut-up written in Fortran in 1967. I even knew that Thom Yorke composed many of the lyrics of Radiohead’s Kid A using Tristan Tzara’s method, substituting a top hat for a bag.
But I hadn’t heard encountered Eno and Schmidt’s Oblique Strategies. Which just goes to show, however much history you think you know—about art, about DH, about pedagogy, about literature, about whatever—you don’t know the half of it. And I suppose the ahistorical methodology of chance operations is part of their appeal. Every roll of the dice, every shuffle of the cards, every random number starts anew. In his magisterial—and quite frankly, seemingly random—Arcades Project, Benjamin devotes an entire section to gambling, where his collection of extracts circles around the essence of gambling. “The basic principle…of gambling…consists in this,” says Alain in one of Benjamin’s extracts, “…each round is independent of the one preceding…. Gambling strenuously denies all acquired conditions, all antecedents…pointing to previous actions…. Gambling rejects the weighty past” (Benjamin 512). Every game is cordoned off from the next. Every game begins from the beginning. Every game requires that history disappear.
That’s the goal of the Oblique Strategies—to clear a space where your own creative history doesn’t stand in the way of you moving forward in new directions. Now in art, chance operations may be all well and good, even revered. But what does something like the Oblique Strategies have to do with the reason we’re here this week: research, scholarship, the production of knowledge? After all, isn’t rejecting “the weighty past” an anathema to the liberal arts?
Well, I think one answer goes back to Eno’s characterization of the Oblique Strategies: there are other ways of working. We can approach the research questions that animate us indirectly, at an angle. Forget the head-on approach for a while.
One way of working that I’ve increasingly become convinced is a legitimate—and much-needed form of scholarship—is deformance. Lisa Samuels and Jerry McGann coined this word, a portmanteau of deform and performance. It’s an interpretative concept premised upon deliberately misreading a text. For example, reading a poem backwards line-by-line. As Samuels and McGann put it, reading backwards “short circuits” our usual way of reading a text and “reinstalls the text—any text, prose or verse—as a performative event, a made thing” (Samuels & McGann 30). Reading backwards revitalizes a text, revealing its constructedness, its seams, edges, and working parts.
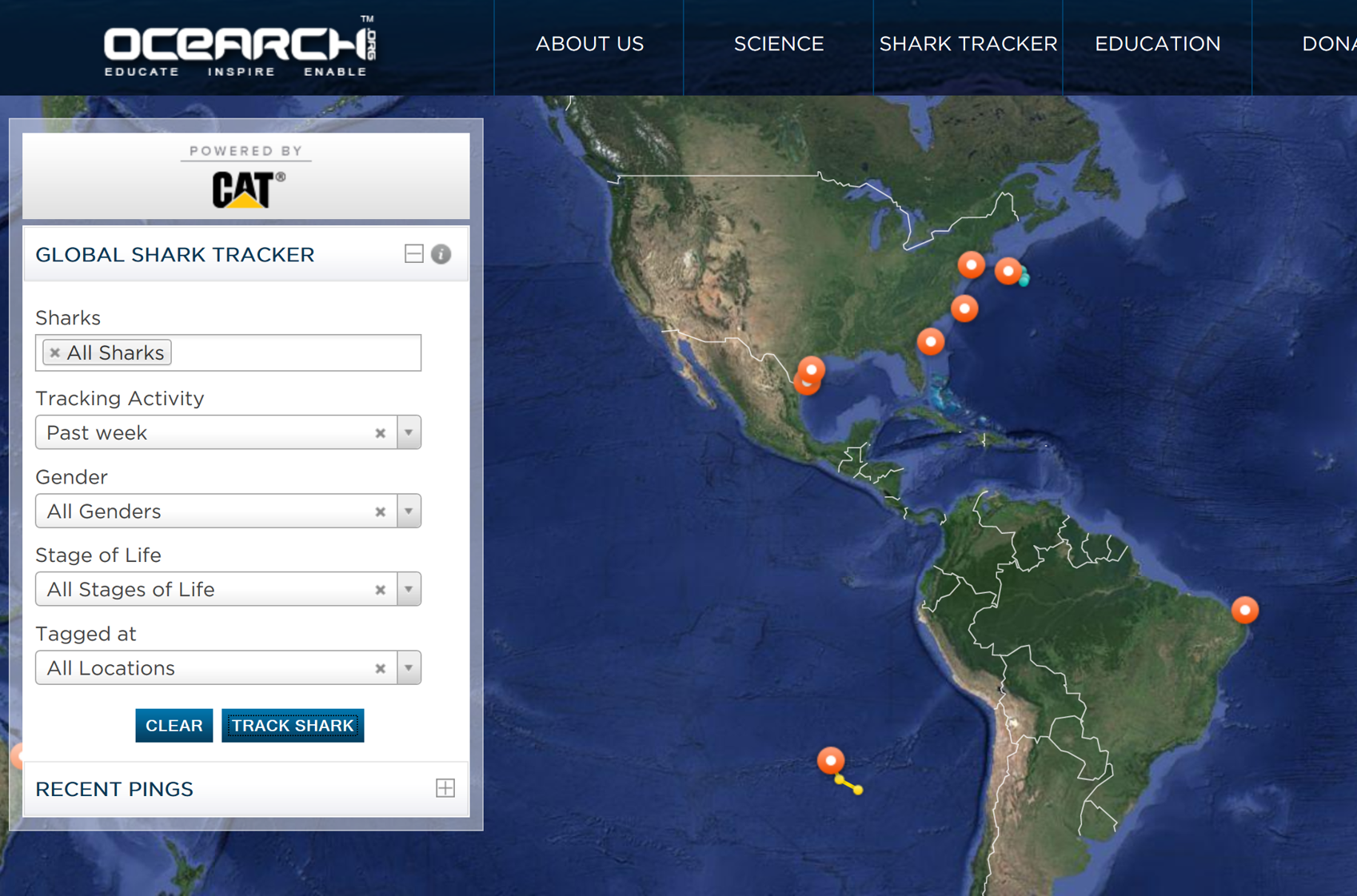
Let me give you an example of deformance. Mary Lee and Katharine are two social media stars, with tens of thousands of followers on Twitter each. They’re also great white sharks in the Atlantic Ocean, tagged with geotrackers by the non-profit research group OCEARCH. Whenever either of the sharks—or any of the dozens of other sharks that OCEARCH has tagged—surfaces longer than 90 seconds, the tags ping geo-orbiting satellites three times in order to triangulate a position. That data is then shared in real-time on OCEARCH’s site or app.
OCEARCH Tracking Map (screenshot)
The sharks’ Twitter accounts, I should say, are operated by humans. They’ll interact with followers, post updates about the sharks, tweet shark facts, and so on. But these official Mary Lee and Katharine accounts don’t automatically tweet the sharks’ location updates.
Sometime this summer—well, actually, it was during shark week—I thought wouldn’t it be cool to create a little bot, a little autonomous program, that automatically tweeted Mary Lee and Katharine’s location updates. But first I needed to get the data itself. I was able to reverse engineer OCEARCH’s website to find an undocumented API, a kind of programming interface that allows computer programs to talk to each other and share data with each other. OCEARCH’s database gives you raw JSON datathat looks like this to a human reader:
But to a computer reader, it looks like this:
Structured data is a thing of beauty.
Reverse engineering the OCEARCH API is not the deformance I’m talking about here. What I found when the bot started tweeting location updates of these two famous sharks was, it was kind of boring. Every few days one of the sharks would surface long enough to get a position, it would post to Twitter, and that was that.
21 July 2015 11:09:39 AM: Katharine pinged satellites at 33.76481, -75.01413. pic.twitter.com/nlGqhhpANG
Something was missing. I wanted to give this Twitter account texture, a sense of personality. I decided to make Mary Lee and Katharine writers. And they would share their writing with the world on this Twitter account. The only problem is, I don’t have time to be a ghost writer for two great white sharks.
So I’ll let a computer do that.
I asked some friends for ideas of source material to use as deformance pieces for the sharks. These would be texts that I could mangle or remix in order to come up with original work that I would attribute to the sharks. A friend suggested American Psycho—an intriguing choice for a pair of sharks, but not quite the vibe I was after. Mary Lee and Katharine are female sharks. I wanted to use women writers. Then Amanda French suggested Virginia Woolf’s novel Night and Day, which just happens to feature two characters named Katharine and Mary. It was perfect, and the results are magical.
Now, Katharine tweets odd mashed-up fragments from Night and Day, each one paired with historical location data from OCEARCH’s database. On December 9, 2014, Katharine was very close to the shore near Rhode Island, and she “wrote” this:
Katharine: Down all luxuriance and plenty to the verge of decency; and in the night, bereft of life (09-Dec-2014) pic.twitter.com/SEEsv3FBKm
In every case, the journal part of the tweet—the writing—is extracted randomly from complete text of Night and Day and then mangled by a Python program. These fragments, paired with the location and the character of a shark, stand on their own, and become new literary material. But they also expose the seams of the original source.
Whereas Katharine writes in prose fragments, I wanted Mary Lee to write poetry:
The line of heroes stands, godlike: Though we wander about, the tangled thread falls slack.
How does Mary Lee writer this? Her source material comes from the works of H.D.—Hilda Doolittle, whose avant-garde Imagist poems are perfect for the cut-up method.
I send you this, a single house of the hundred to freighted ships, baffled in wind and blast.
Mary Lee follows the cut-up method described by Brion Gysin decades ago. I’ve made a database of 1,288 lines of H.D.’s most anthologized poetry. Every tweet from Mary Lee is some combination of three of those 1,288 lines, along with slight typographic formatting. All in all, there are potentially 2 billion, 136 million and 719 thousand original poems that Mary Lee could write.
The snow is melted, we have always known you wanted us. My mind is reft.
What kind of project is @shark_girls? Is it a public humanities project—sharing actual data—dates, locations, maps—that helps people to think differently about wildlife, about the environment, about the interactions between humans and nature? Is it an art project, generating new, standalone postmodern poetry and prose? Is it a literary project, that lets us see Virginia Woolf and H.D. in a new light? Is it all three?
I’ll let other people decide. We can’t get too hung up on labels. What’s important to me is that whatever @shark_girls is about, it’s also about something else. As Susan Sontag wrote about literature: “whatever is happening, something else is always going on.” And the oblique nature of deformance will often point toward that something else. Deformance is a kind of oblique strategy for reading a poem. If the Oblique Strategies deck had a card for deformance it might read:
Work backwards.
Or maybe, simply,
Shuffle.
Another kind of deformance—another oblique strategy for reading—are Markov Chains. Markov chains are statistical models of texts or numbers, based on probability. Let’s say we have the text of Moby Dick.
Just eyeballing the first page we can see that certain words are more likely to be followed by some words than other words. For example, the pronoun “I” is likely to be followed by the verb “find” but not the word “the.” A two-gram Markov Chain looks at the way one pair of words is likely to be followed by a second pair of words. So the pair “I find” is likely to be followed by “myself growing” but not the pair of words “me Ishmael.” A three-gram Markov parses the source text into word triplets. The chain part of a Markov Chain happens when one of these triplets is followed by another triplet, but not necessarily the same triplet that appears in the source text. And then another triplet. And another. It’s a deterministic way to create texts, with each new block of the chain independent of the preceding blocks. Talk about rejecting the weighty past. If you work with a big enough source text, the algorithm generates sentences that are grammatically correct but often nonsensical.
Let’s generate some Markov chains of Moby Dick on the spot. Here’s a little script I made. If it takes a few seconds to load, that’s because every time it runs, it’s reading the entire text of Moby Dick and calculating all the statistical models on the fly. Then spitting out a 3-, 4-, or 5-gram Markov chain. The script tells you what kind of Markov n-gram it is. The script is fun to play around with, and I’ve used it to teach what I call deep textual hacks. When I show literature folks this deformance and teach them how to replace Moby Dick with a text from their own field or time period, they’re invariably delighted. When I show history folks this deformance and teach them how to replace Moby Dick with a primary source from their own field or time period, they’re invariably horrified. History stresses attentiveness to the nuances of a primary source document, not the way you can mangle that very same primary source. Yet, also invariably, my history colleagues realize what Samuels and McGann write about literary deformance is true of historical deformance as well: deformance revitalizes the original text and lets us see it fresh.
All of this suggests what ought to be another one of Brian Eno and Peter Schmidt’s Oblique Strategies:
Misreading is a form of reading.
And to go further, misreading can be a form of critical reading.
Now, let me get to the heart of the matter. I’ve been talking chance operations, deterministic algorithms, and other oblique strategies as a way to explore cultural texts and artifacts. But how do these oblique strategies fit in with the digital humanities? How might oblique strategies not only be another way to work in general, but specifically, another way to work with the digital scholarship and pedagogy we might otherwise more comfortably approach head-on, as Brian Eno put it.
Think about how we value—or say we value—serendipity in higher education. We often praise serendipity as a tool for discovery. When faculty hear that books are going into off-site storage, their first reaction is, how are we going to stumble upon new books when browsing the shelves?
A recent piece by the digital humanities Victorianist Paul Fyfe argues that serendipity has been operationalized, built right into the tools we use to discover new works and new connections between works (Fyfe 262). Serendipomatic, for example, is an online tool that came out of the Roy Rosenzweig Center for History and New Media. You can dump in your entire Zotero library, or even just a selection of text, and Serendipomatic will find sources from the Digital Public Library of America or Europeana that are connected—even if obliquely—to your citations. Let your sources surprise you, the tagline goes.
Tim Sherratt has created a number of bots that tweet out random finds from the National Library of Australia. I’ve done the same with the Digital Public Library of America, creating a bot that posts random items from the DPLA.Similarly, there’s @BookImages, which tweets random cat-pics images from the 3.3 million public domain images from pre-1922 books that the Internet Archive uploaded to Flickr.
Fyfe suggests that “these machines of serendipity sometimes offer simple shifts of perspective” (263)—and he’s totally right. And simple shifts of perspective are powerful experiences, highlighting the contingency and plurality of subjectivity.
But in all these cases, serendipity is a tool for discovery, not a mode of work itself. We think of serendipity as a way to discover knowledge, but not as a way to generate knowledge. This is where the oblique strategies come into play. They’re not strategies for discovery, they’re practices for creativity.
Let me state it simply: what if we did the exact opposite of what many of you have spent the entire week doing. Many of you have been here a whole week, thinking hard and working hard—which are not necessarily the same thing—trying to fulfill a vision, or at the very least, sketch out a vision. That is good. That is fine, necessary work. But what if we surrendered our vision and approached our digital work obliquely—even, blindly.
I’m imagining a kind of dada DH. A gonzo DH. Weird DH. Which is in fact the name of a panel I put together for the 2016 MLA in Austin in January. As I wrote in the CFP, “What would an avant-garde digital humanities look like? What might weird DH reveal that mainstream DH leaves out? Is DH weird enough already? Can we weird it more?”
My own answer to that last question is, yes. Yes, we can. Weird it more. The folks on the panel: Micki Kaufman, Shane Denson, Kim Knight, Jeremy Justus will all be sharing work that challenges our expectations about the research process, about the final product of scholarship, and even what counts as knowledge itself, as opposed to simply data, or information.
So many of the methodologies we use in the digital humanities come from the social sciences—network analysis, data visualization, GIS and mapping, computational linguistics. And that’s all good and I am 100 percent supportive of borrowing methodological approaches. But why do we only borrow from the sciences? What if—and this is maybe my broader point today—what if we look for inspiration and even answers from art? From artists. From musicians and poets, sculptors and quilters.
And this takes me back to my earlier question: what might a set of oblique strategies—originally formulated by a musician and an artist—look like for the digital humanities?
Well, we could simply take the existing oblique strategies and apply them to our own work.
Do something boring.
Maybe that’s something we already do. But I think we need a set of DH-specific oblique strategies. My first thought was to subject the original Oblique Strategies to the same kind of deterministic algorithm that I showed you with Moby-Dick, that is, Markov chains.
Here are a few of the Markov Chained Oblique Strategies my algorithm generated:
Breathe more human. Where is the you do?
Make what’s perfect more than nothing for as ‘safe’ and continue consistently.
Your mistake was a vital connection.
I love the koan-like feeling of these statements. The last one made so much sense that I worked it into the title of my talk: your mistake was a vital connection. And I truly believe this: our mistakes, in our teaching, in our research, are in fact vital connections. Connections binding us to each other, connections between domains of knowledge, connections between different iterations of our own work.
But however much I like these mangled oblique strategies, they don’t really speak specifically about our work in the digital humanities. So in the past few weeks, I’ve been trying to create DH-specific oblique strategies, programmatically.
The great thing about Markov chains is that you can combine multiple source texts, and the algorithm will treat them equally. My Moby Dick Markov Chains came from the entire text of the novel, but there’s no reason I couldn’t also dump in the text of Sense and Sensibility, creating a procedurally-generated mashup that combines n-grams from both novels into something we might call Moby Sense.
So I’m going to try something for my conclusion. And I have no idea if this is going to work. This could be a complete and utter failure. Altogether, taking into account the different editions of the Oblique Strategies, there are 155 different strategies. I’m going to combine those lines with texts that have circulated through the digital humanities community in the past few years. This source material includes Digital_Humanities, The Digital Humanities Manifesto, and a new project on Critical DH and Social Justice, among other texts. (All the sources are linked below.) I’ve thrown all these texts together in order to algorithmically generate my new DH-focused oblique strategies.
[At this point in my keynote I started playing around with the Oblique DH Generator. The version I debuted is on a stand-alone site, but I’ve also embedded it below. My talk concluded—tapered off?—as I kept generating new strategies and riffing on them. We then moved to a lively Q&A period, where I elaborated on some of the more, um, oblique themes of my talk. As nicely as this format worked at ILiADS, it doesn’t make for a very satisfying conclusion here. So I’ll wrap up with a new, equally unsatisfying conclusion, and then you can play with the generator below. And draw your own conclusions.]
My conclusion is this, then. A series a oblique strategies for the digital humanities that are themselves obliquely generated. The generator below is what I call a webtoy. But I’ve also been thinking about it as what Ted Nelson calls a “thinkertoy”—a toy that helps you think and “envision complex alternatives” (Dream Machines 52). In this case, the thinkertoy suggests alternative approaches to the digital humanities, both as a practice and as a construct (See Kirschenbaum on the DH construct). And it’s also just plain fun. For, as one of the generated oblique strategies for DH says, Build bridges between the doom and the scholarship. And what better way to do that than playing around?
Benjamin, Walter. The Arcades Project. Edited by Rolf Tiedemann. Translated by Howard Eiland and Kevin McLaughlin. Cambridge, Massachusetts: Belknap-Harvard UP, 1999.
Kirschenbaum, Matthew. “What Is ‘Digital Humanities,’ and Why Are They Saying Such Terrible Things about It?” Differences 25, no. 1 (2014): 46–63. doi:10.1215/10407391-2419997.
Nelson, Theodor H. Computer Lib/Dream Machines. 1st ed. Chicago: Hugo’s Book Service, 1974.
Samuels, Lisa, and Jerome McGann. “Deformance and Interpretation.” New Literary History 30, no. 1 (January 1, 1999): 25–56.
Sontag, Susan. “In Jerusalem.” The New York Review of Books, June 21, 2001. http://www.nybooks.com/articles/archives/2001/jun/21/in-jerusalem/.
Zweig, Ellen. “Jackson Mac Low: The Limits of Formalism.” Poetics Today 3, no. 3 (July 1, 1982): 79–86. doi:10.2307/1772391.
Here is a list of more or less digitally-oriented sessions at the upcoming Modern Language Association convention. These sessions address digital culture, digital tools, and digital methodology, played out across the domains of research, pedagogy, and scholarly communication. If I’ve overlooked a session, let me know in the comments. You might also be interested in my short reflection on how the 2015 program stacks up against previous MLA programs. Continue reading “Digital Humanities at MLA 2015 Vancouver, January 8-10“→
Since 2009 I’ve been compiling an annual list of more or less digitally-oriented sessions at the Modern Language Association convention. This is the list for 2015. These sessions address digital culture, digital tools, and digital methodology, played out across the domains of research, teaching, and scholarly communication. For the purposes of my annual lists I clump these varied approaches and objects of study into a single contested term, the digital humanities (DH).
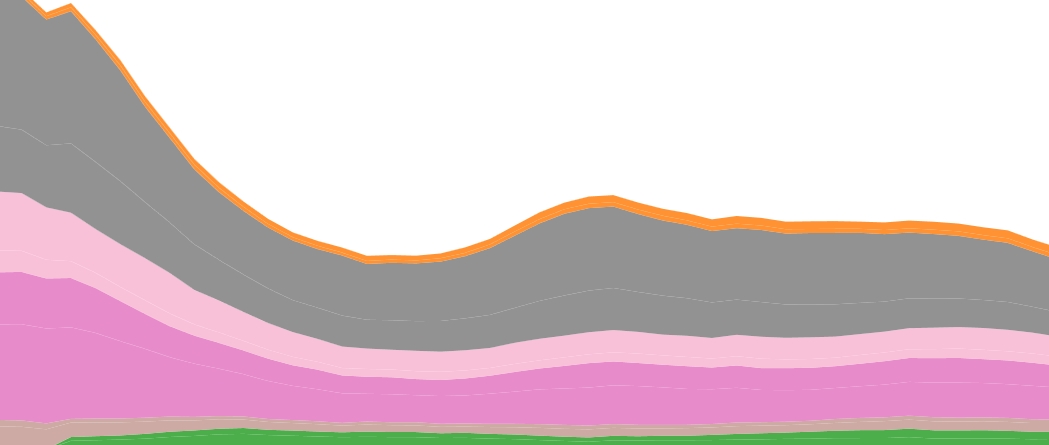
DH sessions at the 2015 convention make up 7 percent of overall sessions, down from a 9 percent high last year. Here’s what the trend looks like over the past 6 MLA conventions (there was no convention in 2010, the year the conference switched from late December to early January): Continue reading “Digital Humanities and the MLA On the state of the field at the MLA“→
Five years ago in this space I attempted what I saw as a meaningful formulation of critical thinking—as opposed to the more vapid definitions you tend to come across in higher education. Critical thinking, I wrote, “stands in opposition to facile thinking. Critical thinking is difficult thinking. Critical thinking is being comfortable with difficulty.”
Two hallmarks of difficult thinking are imagining the world from multiple perspectives and wrestling with conflicting evidence about the world. Difficult thinking faces these ambiguities head-on and even preserves them, while facile thinking strives to eliminate complexity—both the complexity of different points of view and the complexity of inconvenient facts. Continue reading “Difficult Thinking about the Digital Humanities”→
A tentative syllabus for DIG 350: History & Future of the Book, a course just approved for the Digital Studies program at my new academic home, Davidson College. Many thanks to Ryan Cordell, Lisa Gitelman, Kari Kraus, Jessica Pressman, Peter Stallybrass, and many others, whose research and classes inspired this one.
DIG 350: History & Future of the Book
Course Description
A book may only be made of paper, cardboard, ink, and glue, but it is nonetheless a remarkable piece of technology—about which we have mostly forgotten it is a piece of technology. This class is concerned with the long history, the varied present, and the uncertain future of the book in the digital age. Continue reading “History and Future of the Book (Fall 2014 Digital Studies Course)”→
If you’re an academic, you’ve probably heard about the recent New York Timesarticle covering the decline of humanity majors at places like Stanford and Harvard. As many people have already pointed out, the article is a brilliant example of cherry-picking anecdotal evidence to support an existing narrative (i.e. the crisis in the humanities)—instead of using, you know, actual facts and statistics to understand what’s going on.
Ben Schmidt, a specialist in intellectual history at Northeastern University, has put together an interactive graph of college majors over the past few decades, using the best available government data. Playing around with the data shows some surprises that counter the prevailing narrative about the humanities. For example, Computer Science majors have declined since 1986, while History has remained steady. Ben argues elsewhere that not only was the steepest decline in the humanities in the 1970s instead of the 2010s, but that the baseline year that most crisis narratives begin with (the peak year of 1967) was itself an aberration.
Of course, Ben’s data is in the aggregate and doesn’t reflect trends at individual institutions. But you can break the data down into institution type, and find that traditional humanities fields at private SLACs like my own (Davidson College) are pretty much at late-1980s levels.
Clearly we should be doing more to counter the perception that the humanities—and by extension, the liberal arts—are in crisis mode. My own experience in the classroom doesn’t support this notion, and neither does the data.
This is a list of digitally-inflected sessions at the 2014 Modern Language Association Convention (Chicago, January 9-12). These sessions in some way address digital tools, objects, and practices in language, literary, textual, cultural, and media studies. The list also includes sessions about digital pedagogy and scholarly communication. The list stands at 78 entries, making up less than 10% of the total 810 convention slots. Please leave a comment if this list is missing any relevant sessions. Continue reading “Digital Humanities at MLA 2014”→
“Non-consumptive research” is the term digital humanities scholars use to describe the large-scale analysis of a texts—say topic modeling millions of books or data-mining tens of thousands of court cases. In non-consumptive research, a text is not read by a scholar so much as it is processed by a machine. The phrase frequently appears in the context of the long-running legal debate between various book digitization efforts (e.g. Google Books and HathiTrust) and publishers and copyright holders (e.g. the Authors Guild). For example, in one of the preliminary Google Books settlements, non-consumptive research is defined as “computational analysis” of one or more books “but not research in which a researcher reads or displays substantial portions of a Book to understand the intellectual content presented within.” Non-consumptive reading is not reading in any traditional way, and it certainly isn’t close reading. Examples of non-consumptive research that appear in the legal proceedings (the implications of which are explored by John Unsworth) include image analysis, text extraction, concordance development, citation extraction, linguistic analysis, automated translation, and indexing. Continue reading “The Poetics of Non-Consumptive Reading”→
Mark Z. Danielewski’s House of Leaves is a massive novel about, among other things, a house that is bigger on the inside than the outside. Walt Whitman’s Leaves of Grass is a collection of poems about, among other things, the expansiveness of America itself.
What happens when these two works are remixed with each other? It’s not such an odd question. Though separated by nearly a century, they share many of the same concerns. Multitudes. Contradictions. Obsession. Physical impossibilities. Even an awareness of their own lives as textual objects.
To explore these connections between House of Leaves and Leaves of Grass I have created House of Leaves of Grass, a poem (like Leaves of Grass) that is for all practical purposes boundless (like the house on Ash Tree Lane in House of Leaves). Or rather, it is bounded on an order of magnitude that makes it untraversable in its entirety. The number of stanzas (from stanza, the Italian word for “room”) approximates the number of cells in the human body, around 100 trillion. And yet the container for this text is a mere 24K. Continue reading “no life no life no life no life: the 100,000,000,000,000 stanzas of House of Leaves of Grass”→
I am thrilled to share the news that in August I will join the faculty of Davidson College, where I will be building a new interdisciplinary program in Digital Studies. This is a tremendous opportunity for me, and my immodest goal is to make Davidson College a model for other liberal arts colleges—and even research universities—when it comes to digital studies.
This means I am leaving George Mason University, and I am doing so with much sadness. I have been surrounded by generous colleagues, dedicated teachers, and rigorous thinkers. I cannot imagine a better place to have begun my career. At the same time, my life at GMU has always been complicated by the challenges of a long distance commute, which I have written about here and elsewhere. My new position at Davidson will eliminate this commute. After seven or so years of flying 500 miles to work each week, it will be heaven to simply bike one mile to work every day.
And a good thing too—because I have big plans for Digital Studies at Davidson and much work to do. Students are already enrolling in my Fall 2013 courses, but more than individual classes, we have an entire program to design. I am thrilled to begin working with my new colleagues in both the humanities and sciences. Together we are going to build something both unique and uniquely Davidson.












")


{kind=link}