")
“Non-consumptive research” is the term digital humanities scholars use to describe the large-scale analysis of a texts—say topic modeling millions of books or data-mining tens of thousands of court cases. In non-consumptive research, a text is not read by a scholar so much as it is processed by a machine. The phrase frequently appears in the context of the long-running legal debate between various book digitization efforts (e.g. Google Books and HathiTrust) and publishers and copyright holders (e.g. the Authors Guild). For example, in one of the preliminary Google Books settlements, non-consumptive research is defined as “computational analysis” of one or more books “but not research in which a researcher reads or displays substantial portions of a Book to understand the intellectual content presented within.” Non-consumptive reading is not reading in any traditional way, and it certainly isn’t close reading. Examples of non-consumptive research that appear in the legal proceedings (the implications of which are explored by John Unsworth) include image analysis, text extraction, concordance development, citation extraction, linguistic analysis, automated translation, and indexing.
More recently, Matthew Sag has reformulated non-consumptive research as “nonexpressive use.” In an amicus brief filed on behalf of HathiTrust, Sag, Matthew Jockers, and Jason Schultz explain that with digital humanities-style book digitization, “works are copied for reasons unrelated to their protectable expressive qualities; none of the works in question are being read by humans as they would be if sitting on the shelves of a library or bookstore.” Scholars “do not read, understand, or enjoy” the copyrighted works in question. The works’ expressive qualities—tone, perspective, figurative language, thematic content, and so on—are mere words on a page, pieces of data used to generate metadata. This nonexpressive use is the primary legal defense of digitization for the sake of large-scale textual analysis.
In the last chapter of Macroanalysis (2013), Jockers argues that unless the law recognizes the value of nonexpressive use of copyrighted works, digital humanists will be stuck studying books in the public domain. “Today’s digital-minded literary scholar is shackled in time,” Jockers writes. “We are all, or are all soon to become, nineteenth centuryists.” This sentiment echoes my own argument in Debates in the Digital Humanities, in which I use the contemporary American novelist Don DeLillo as a case study. Yet as I hope is obvious in my chapter, I am somewhat skeptical about what large-scale text analysis might reveal about DeLillo’s novels that we don’t already know. I present a counterfactual timeline that satirizes what scholars might learn about DeLillo from non-consumptive research. I particularly like this entry from 1999, with its oblique reference to Barthes’ “The Death of the Author”:
An English professor skilled in computational analysis uses word frequency counts to compare the text of the White Noise Omnibus CD-ROM with a scanned and OCR’d version of the raucous but out-of-print novel Amazons by Cleo Birdwell, long suspected to be the work of DeLillo. The professor’s computer proves with a +/– 10 percent error rate that DeLillo is the author of Amazons, primarily based on the recurrence of the name “Murray Jay Siskind” in both novels. The English professor publishes his findings in the journal Social Text, concluding that “now that the author has been found, the text is explained.”
The joke—one of them, at least— is that everyone already knows DeLillo is the primary author of Amazons. No text analysis is needed. There is no +/-10 percent error rate. We know it with with 100% certainty, and a trip to the Don DeLillo Papers at the Harry Ransom Center at UT-Austin will reveal not only draft manuscripts of Amazons but also a letter from DeLillo to his agent that explains why he wants to publish under a pseudonym. (“I want to be out of the picture. I want to disengage myself,” DeLillo writes.)
My counterfactual timeline parodies other digital humanities applications as well, including data-mining, GIS, and 3D environments. I don’t mean to suggest these digital tools have no place in humanities research. My chapter has a lot of hyperbole, and I routinely overstate my case in order to make my point (a rhetorical flourish that itself parodies academic discourse). In any case, I’ve been thinking more critically lately about what non-consumptive research—that is, nonexpressive use—of contemporary copyright-protected works can add to our understanding of those works. I want to propose an approach to non-consumptive research that stands in direct opposition to the stance articulated by most digital humanists:
Let’s turn our non-consumptive use of digitized works into expressive use of digitized works.
Consider my project House of Leaves of Grass as an illustrative example. As I explain in my artist’s statement, House of Leaves of Grass is a 100 trillion stanza-long mashup of Walt Whitman’s Leaves of Grass (which is in the public domain) and Mark Z. Danielewski’s House of Leaves (which is not). To create the work (which was inspired by Sea and Spar Between by Nick Montfort and Stephanie Strickland), I subjected the source texts to a number of typical non-consumptive analyses. The most conventional of these analyses were simply word frequency lists, made using Voyant Tools. Here’s my list of the 2,017 most frequently used words in House of Leaves; these are all the words in Danielewski’s novel that appear ten times or more. Guided by this list and other non-consumptive analyses, I reassembled both common and unique words and phrases from Leaves of Grass and House of Leaves into an entirely new work. In other words, House of Leaves of Grass transforms a non-consumptive engagement of House of Leaves and Leaves of Grass into an expressive engagement of those texts, which can be read, understood, and enjoyed. I transformed what Franco Moretti would call a distant reading into a new textual—and expressive—object.
The way House of Leaves of Grass calls attention to key lines—say the variations of “This is not for you” from House of Leaves or the repetition of “I Sing!” from Leaves of Grass—reinstates the expressive potential of what had become, in my non-consumptive research, a database of words. The seemingly empirical “model” of a corpus typically built from distant reading offers itself up as an aesthetic object on its own terms. Furthermore, not only can we close-read House of Leaves of Grass (and, given its size, close reading may be the only conceivable way to read it), we can use House of Leaves of Grass to aid in a close reading of its source texts. My distant reading of House of Leaves and Leaves of Grass became a close reading.
Borrowing from my experience making House of Leaves of Grass, I want to advocate for a poetics of non-consumptive reading in the digital humanities. Scholars and students of art, literature, history, and culture ought to transform more of our non-consumptive research into expressive objects. Nonexpressive use of texts is a dead-end for the humanities. A computer model surrounded by a wall of explanatory words is not enough. Make the computer model itself an expressive object. Turn your data into a story, into a game, into art. Call it aesthetic empiricism or empirical aesthetics. Call it whatever you want. But without a poetics of machine reading, there is nothing.
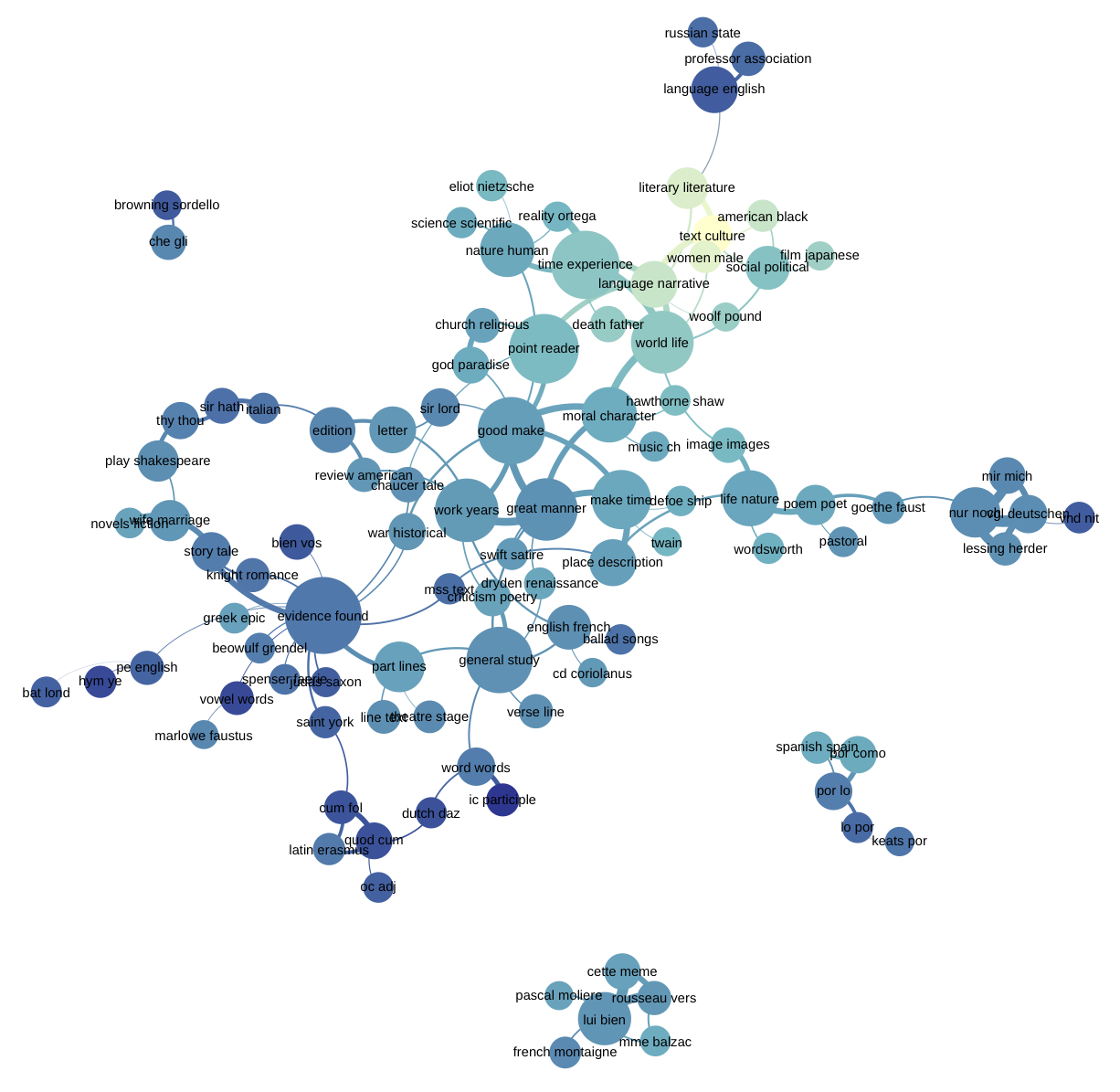
Header image is Ted Underwood’s visualization of Andrew Goldstone’s topic model of the PMLA, from the Journal of Digital Humanities, Vol. 2., No. 1 (Winter 2012)
“Turn your data into a story, into a game, into art.” Aesthetics, expression as part of DH work: MT @samplereality: http://t.co/Jx5eF7guHO
#elit + #dh “Make the computer model itself an expressive object. Turn your data into a story, into a game, into art” http://t.co/mrQT1qtB0v
“Let’s turn our non-consumptive use of digitized works into expressive use of digitized works.” — @samplereality http://t.co/KTryACEOzy
“Without a poetics of machine reading, there is nothing.” http://t.co/32NDpUOsCp
Instead of blogging about cat-beards (What do they mean? Why now?), I wrote about expressive empiricism in DH: http://t.co/7R1BpZQVLJ
= Hey @samplereality: great piece. But why “non-consumptive reading” rather than “non-hermeneutic?” http://t.co/1Ky8hDw64D
By @samplereality: ‘Let’s turn our non-consumptive use of digitized works into expressive use of digitized works.’ http://t.co/RN0cgpNh4n
“A computer model surrounded by a wall of explanatory words is not enough.” – @samplereality http://t.co/4re3T7EOLw
as I just read Macroanlysis&have convo w/publisher re dig sources fnd this v int RT @samplereality nonconsumpt rdng
http://t.co/sOLCwRStR7
.@samplereality on “The Poetics of Non-Consumptive Reading” — DH, machine reading, copyright http://t.co/TcCblRmYJq #dhdebates
THIS. “@ckunzelman: “A computer model surrounded by a wall of explanatory words is not enough.” – @samplereality http://t.co/tnjL0zqyUe”
Great post from @samplereality ‘Nonexpressive use of texts is a dead-end for the humanities.’ http://t.co/3JJNIXzxBT
Editors’ Choice: The Poetics of Non-Consumptive Reading http://t.co/KCPAiznWoE
Cleverly left out link to @samplereality “Expressive use of digitized works” bit “Poetics of Non-Consumptive Reading” http://t.co/f99l2iaw0D
» The Poetics of Non-Consumptive Reading http://t.co/yYkaBxdnBI
I see @samplereality’s call here similar to a #PublicHistorian’s challenge to use Big Data in publicly engaging ways. http://t.co/hHVjz2AVs0
A poetics of machine reading. http://t.co/74ivxVepEB
Editors’ Choice: The Poetics of Non-Consumptive Reading: { http://t.co/IYQvoDMwc6 }
Enjoying catching up on @samplereality’s “The Poetics of Non-Consumptive Reading,” and thinking @manglin91 might too: http://t.co/oaUBpqlf41
@samplesreality’s “aesthetic empiricism” http://t.co/RrDvinbpn8 & @williamjturkel et al’s experimental humanities http://t.co/14boNrj01L [-]
@samplereality’s “aesthetic empiricism” http://t.co/RrDvinbpn8 & @williamjturkel et al’s experimental humanities http://t.co/14boNrj01L [-]
.@jenterysayers cites @samplereality’s Poetics of Non-Consumptive Reading http://t.co/EBTK6N618e #dhforum2013
[…] myself siding with Matthew Jockers however that as he argues that something must be done or “digital humanists will be stuck studying books in the public domain“. In his 2013 book Macroanalysis he claims that “today’s digital-minded literary […]
[…] Mark Sample, Associate Professor in the Department of English at George Mason University, is an advocate of non-consumptive reading. Yet he argues that we must be clever in the way we use it for fear we fall foul to a “lack of intellectual insights” that some feel is characteristic of distant reading. He believes that we must create something that could not be possible any other way and that truly makes the data different. He continues to say that “non-expressive use of texts is a dead-end for the humanities. A computer model surrounded by a wall of explanatory words is not enough” and instead to strive to ”turn your data into a story, into a game, into art”. (Sample) […]
The Poetics of Non-Consumptive Reading http://t.co/4yvx2hlw31
[…] your data into a story, into a game, into art. – Mark Sample, “The Poetics of Non-Consumptive Reading” I initially encountered Walter Benjamin’s essay, “Unpacking My Library,” […]
[…] digital humanities scholars make scholarly artifacts, when any scholars make scholarly artifacts that don’t conform to aesthetic expectations baked into the law, they are potentially engaging in a kind of resistance. Such artifacts present […]
[…] are being read by humans as they would be if sitting on the shelves of a library or bookstore” (Sample). In fact, “unless the law recognizes the value of nonexpressive use of copyrighted works, […]
[…] am thinking of Thomas Aquinas—we have at our disposal the entire corpus online. A sort of “non-consumptive reading” or “topic modelling” may be of help, I believe, in finding within Aquinas’ corpus the […]
or more examples of what @samplereality calls the “poetics of non-consumptive reading” http://t.co/7KeqZPne2a
@IDAH_IU’s 10/20 Moretti Reading Group is on Distant Reading. Want a lively intro? See @Ted_Underwood https://t.co/mvX8OxRgIN