I’m spending July in Cádiz, Spain, with my family and a bunch of students from Davidson College. The other weekend we visited Granada, home of the Alhambra. Built by the last Arabic dynasty on the Iberian peninsula in the 13th century, the Alhambra is a stunning palace overlooking the city below. The city of Granada itself—like several other cities in Spain—is a palimpsest of Islamic, Jewish, and Christian art, culture, and architecture.
Take the streets of Granada. In the Albayzín neighborhood the cobblestone streets are winding, narrow alleys, branching off from each other at odd angles. Even though I’ve wandered Granada several times over the past decade, it’s easy to get lost in these serpentine streets. The photograph above (Flickr source) of the Albayzín, shot from the Alhambra, can barely reveal the maze that these medieval Muslim streets form. The Albayzín is a marked contrast to the layout of historically Christian cities in Spain. Influenced by Roman design, a typical Spanish city features a central square—the Plaza Mayor—from which streets extend out at right angles toward the cardinal points of the compass. Whereas the Muslim streets are winding and organic, the Christian streets are neat and angular. It’s the difference between a labyrinth and a grid.
It just so happened that on our long bus ride to Granada I finished playing Anchorhead, Michael Gentry’s monumental work of interactive fiction (IF) from 1998. Even if you’ve never played IF, you likely recognize it when you see it, thanks to the ongoing hybridization of geek culture with pop culture. Entirely text-based, these story-games present puzzles and narrative situations that you traverse through typed commands, like GO NORTH, GET LAMP, OPEN JEWELED BOX, etc. As for Anchorhead, it’s a Lovecraftian horror with cosmic entities, incestual families, and the requisite insane asylum. Anchorhead also includes a mainstay of early interactive fiction: a maze.
Two of them in fact.
It’s difficult to overstate the role of mazes in interactive fiction. Will Crowther and Don Woods’ Adventure (or Colossal Cave) was the first work of IF in the mid-seventies. It also had the first maze, a “maze of twisty little passages, all alike.” Later on Zork would have a maze, and so would many other games, including Anchorhead. Mazes are so emblematic of interactive fiction that the first scholarly book on the subject references Adventure‘s maze in its title: Nick Montfort’s Twisty Little Passages: An Approach to Interactive Fiction (MIT Press, 2003). Mazes are also singled out in the manual for Inform 7, a high level programming language used to create many contemporary works of interactive fiction. As the official Inform 7 “recipe book” puts it, “Many old-school IF puzzles involve journeys through the map which are confused, randomised or otherwise frustrated.” Mazes are now considered passé in contemporary IF, but only because they were used for years to convey a sense of disorientation and anxiety.
And so, there I was in Granada having just played one of the most acclaimed works of interactive fiction ever. It occurred to me then, among the twisty little passages of Granada, that a relationship exists between the labyrinthine alleys of the Albayzín and the way interactive fiction has used mazes.
See, the usual way of navigating interactive fiction is to use cardinal directions. GO WEST. SOUTHEAST. OPEN THE NORTH DOOR. The eight points of the compass rose is an IF convention that, like mazes, goes all the way back to Colossal Cave. The Inform 7 manual briefly acknowledges this convention in its section on rooms:
In real life, people are seldom conscious of their compass bearing when walking around buildings, but it makes a concise and unconfusing way for the player to say where to go next, so is generally accepted as a convention of the genre.
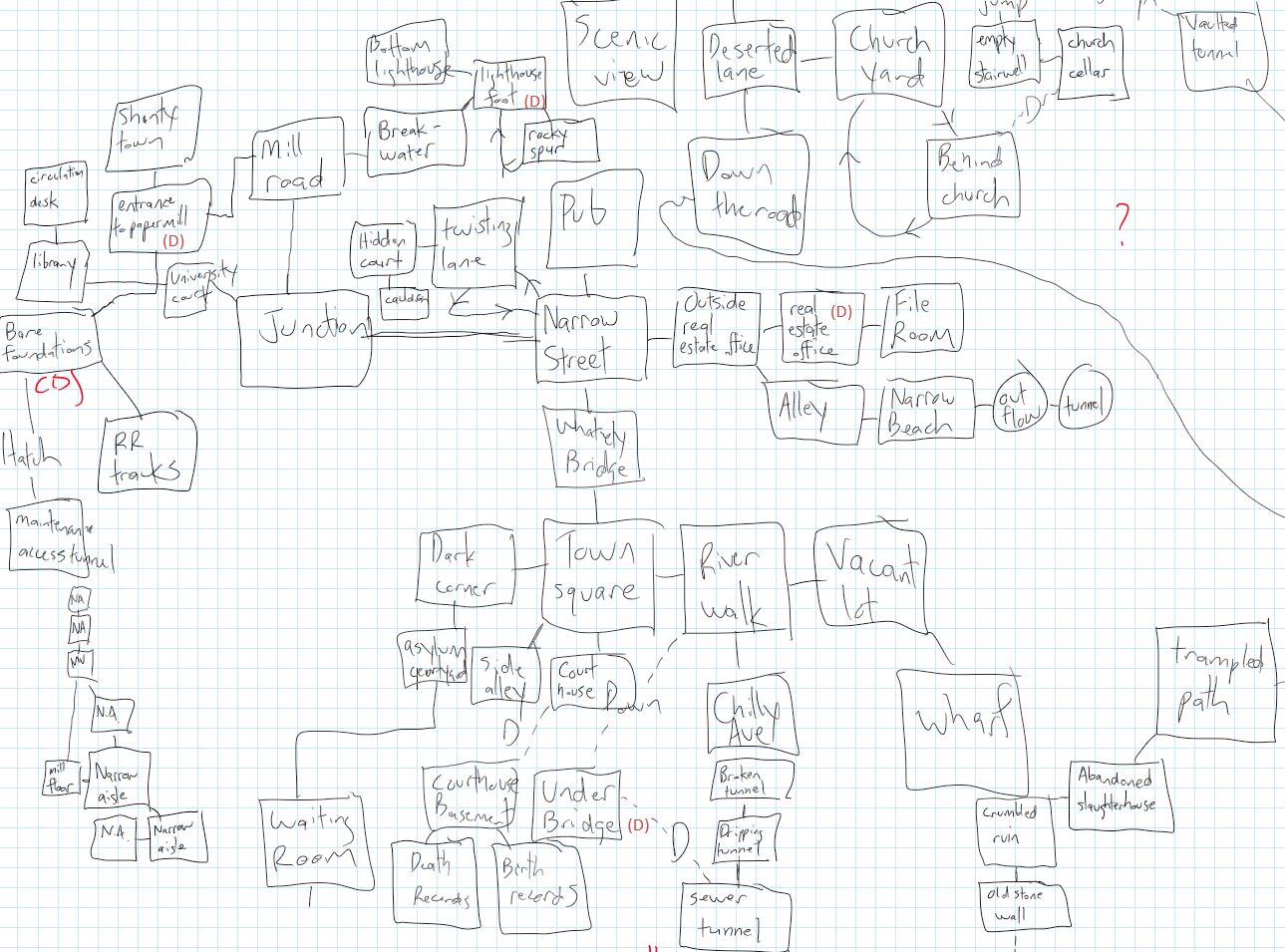
Let’s dig into this convention a bit. Occasionally, it’s been challenged (Aaron Reed’s BlueLacuna comes to mind), but for the most part, navigating interactive fiction with cardinal directions is simply what you expect to do. It’s essentially a grid system that helps players mentally map the game’s narrative spaces. Witness my own map of Anchorhead, literally drawn on graph paper as I played the game (okay, I drew it on OneNote on an iPad, but you get the idea):
My partial map of Anchorhead, drawn by hand
And when IF wants to confuse, frustrate, or disorient players, along comes the maze. Labyrinths, the kind evoked by the streets of the Albayzín, defy the grid system of Western logic. Mazes in interactive fiction are defined by the very breakdown of the compass. Direction don’t work anymore. The maze evokes otherness by defying rationality.
When the grid/maze dichotomy of interactive fiction is mapped onto actual history—say the city of Granada—something interesting happens. You start to see the the narrative trope of the maze as an essentially Orientalist move. I’m using “Orientalist” here in the way Edward Said uses it, a name for discourse about the Middle East that mysticizes yet disempowers the culture and its people. As Said describes it, Orientalism is part of a larger project of dominating that culture and its people. Orientalist tropes of the Middle East include ahistorical images that present an exotic, irrational counterpart to the supposed logic of European modernity. In an article in the European Journal of Cultural Studies about the representation of Arabs in videogames, Vít Ŝisler provides a quick list of such tropes. They include “motifs such as headscarves, turbans, scimitars, tiles and camels, character concepts such as caliphs, Bedouins, djinns, belly dancers and Oriental topoi such as deserts, minarets, bazaars and harems.” In nearly every case, for white American and European audiences these tropes provide a shorthand for an alien other.
My argument is this:
Interactive fiction relies on a Christian-influenced, Western European-centric sense of space. Grid-like, organized, navigable. Mappable. In a word, knowable.
Occasionally, to evoke the irrational, the unmappable, the unknowable, interactive fiction employs mazes. The connection of these textual mazes to the labyrinthine Middle Eastern bazaar that appears in, say Raiders of the Lost Ark, is unacknowledged and usually unintentional.
We cannot truly understand the role that mazes play vis-à-vis the usual Cartesian grid in interactive fiction unless we also understand the interplay between these dissimilar ways of organizing spaces in real life, which are bound up in social, cultural, and historical conflict. In particular, the West has valorized the rigid grid while looking with disdain upon organic irregularity.
Notwithstanding exceptions like Lisa Nakamura and Zeynep Tufekci, scholars of digital media in the U.S. and Europe have done a poor job looking beyond their own doorsteps for understanding digital culture. Case in point: the “Maze” chapter of 10 PRINT CHR$(205.5+RND(1)); : GOTO 10 (MIT Press, 2012), where my co-authors and I address the significance of mazes, both in and outside of computing, with nary a mention of non-Western or non-Christian labyrinths. In hindsight, I see the Western-centric perspective of this chapter (and others) as a real flaw of the book.
I don’t know why I didn’t know at the time about Laura Marks’ Enfoldment and Infinity: An Islamic Genealogy of New Media Art (MIT Press, 2010). Marks doesn’t talk about mazes per se, but you can imagine the labyrinths of Albayzín or the endless maze design generated by the 10 PRINT program as living enactments of what Marks calls “enfoldment.” Marks sees enfoldment as a dominant feature of Islamic art and describes it as the way image, information, and the infinite “enfold each other and unfold from one another.” Essentially, image gives way to information which in turn is an index (an impossible one though) to infinity itself. Marks argues that this dynamic of enfoldment is alive and well in algorithmic digital art.
With Marks, Granada, and interactive fiction on my mind, I have a series of questions. What happens when we shift our understanding of mazes from non-Cartesian spaces meant to confound players to transcendental expressions of infinity? What happens when we break the convention in interactive fiction by which grids are privileged over mazes? What happens when we recognize that even with something as non-essential to political power as a text-based game, the underlying procedural system reinscribes a model that values one valid way of seeing the world over another, equally valid way of seeing the world?
Header Image: Anh Dinh, “Albayzin from Alhambra” on Flickr (August 10, 2013). Creative Commons BY-NC license.
I am revamping “Introduction to Digital Studies,” my program’s overview of digital culture, creativity, and methodology. One approach is to partially organize the class around file types, the idea being that a close reading of certain file types can help us better understand contemporary culture, both online and off.
It’s a bit like Raymond William’s Keywords, except with file types. A few of the file types that seem especially generative to consider:
MP3 (Jonathan Sterne’s work on MP3s is the gold standard to follow)
GIF (especially the rise and fall and rise of the animated GIF)
HTML (a gateway to understanding the early history and ethos of the web)
JSON (as a way to talk about data and APIs)
This list is just an initial start, of course. What other culturally significant file types would you have students consider? And what undergrad-friendly readings about those file types would you recommend?
Digging through some old files I came across notes from a roundtable discussion I contributed to in 2009. The occasion was an “Unthinking Television” symposium held at my then-institution, George Mason University. If I remember correctly, the symposium was organized by Mason’s Cultural Studies and Art and Visual Technology programs. Amazingly, the site for the symposium is still around.
The roundtable was called “Screen Life”—all about the changing nature of screens in our lives. I’m sharing my old notes here, if for nothing else than the historical perspective they provide. What was I, as a new media scholar, thinking about screens in 2009, which was like two epochs ago in Internet time? YouTube was less than five years old. The iPhone was two years old. Avatar was the year’s highest grossing film. Maybe that was even three epochs ago.
Do my “four trends” still hold up? What would you add to this list, or take away? And how embarrassing are my dated references?
Four Trends of Screen Life
Coming from a literary studies perspective, I suppose everyone expects me to talk about the way screens are changing the stories we tell or the way we imagine ourselves. But I’m actually more interested in what we might call the infrastructure of screens. I see four trends with our screens:
(1) A proliferation of screens
I can watch episodes of “The Office” on my PDA, my cell phone, my mp3 player, my laptop, and even on occasion, my television.
(2) Bigger is better and so is smaller
We encounter a much greater range in screen sizes on a daily basis. My new high definition videocamera has a 2” screen and I can hook that up directly via HDMI cable to my 36” flat screen, and there are screen sizes everywhere in between and beyond.
(3) Screens aren’t just to look at
We now touch our screens. Tactile response is just as important as video resolution.
(4) Our screens now look at us
Distribution networks like Tivo and Dish and Comcast have long had unobtrusive ways to track what we’re watching, or at least what our televisions were tuned to. But now screens can actually look at us. I’m referring to screens that aware of us, of our movements. The most obvious is the Wii and its use IR emitters in its sensor bar to triangulate the position of the Wiimote, and hence, the player. GE’s website has been showcasing an interactive “hologram” that uses a webcam. In both cases, the screen sees us. This is potentially the biggest shift in what it means to have a “screen life.” In both this case and my previous trend concerning the new haptic nature of screens, we are completing a circuit that runs between human and machine, machine and human.
I’m at the Electronic Literature Organization’s annual conference in Bergen, Norway, where I hope to capture some “think aloud” readings of electronic literature (e-lit) by artists, writers, and scholars. I’ve mentioned this little project elsewhere, but it bears more explanation.
The think aloud protocol is an important pedagogical tool, famously used by Sam Wineburg to uncover the differences in interpretative strategies between novice historians and professional historians reading historical documents (see Historical Thinking and Other Unnatural Acts, Temple University Press, 2001).
The essence of a think aloud is this: the reader articulates (“thinks aloud”) every stray, tangential, and possibly central thought that goes through their head as they encounter a new text for the first time. The idea is to capture the complicated thinking that goes on when we interpret an unfamiliar cultural artifact—to make visible (or audible) the usually invisible processes of interpretation and analysis.
Once the think aloud is recorded, it can itself be analyzed, so that others can see the interpretive moves people make as they negotiate understanding (or misunderstanding). The real pedagogical treasure of the think aloud is not any individual reading of a new text, but rather the recurring meaning-making strategies that become apparent across all of the think alouds.
By capturing these think alouds at the ELO conference, I’m building a set of models for engaging in electronic literature. This will be invaluable to undergraduate students, whose first reaction to experimental literature is most frequently befuddlement.
If you are attending ELO 2015 and wish to participate, please contact me (samplereality at gmail, @samplereality on Twitter, or just grab me at the conference). We’ll duck into a quiet space, and I’ll video you reading an unfamiliar piece of e-lit, maybe from either volume one or volume two of the Electronic Literature Collection, or possibly an iPad work of e-lit. It won’t take long: 5-7 minutes tops. I’ll be around through Saturday, and I hope to capture a half dozen or so of these think alouds. The more, the better.
“Non-consumptive research” is the term digital humanities scholars use to describe the large-scale analysis of a texts—say topic modeling millions of books or data-mining tens of thousands of court cases. In non-consumptive research, a text is not read by a scholar so much as it is processed by a machine. The phrase frequently appears in the context of the long-running legal debate between various book digitization efforts (e.g. Google Books and HathiTrust) and publishers and copyright holders (e.g. the Authors Guild). For example, in one of the preliminary Google Books settlements, non-consumptive research is defined as “computational analysis” of one or more books “but not research in which a researcher reads or displays substantial portions of a Book to understand the intellectual content presented within.” Non-consumptive reading is not reading in any traditional way, and it certainly isn’t close reading. Examples of non-consumptive research that appear in the legal proceedings (the implications of which are explored by John Unsworth) include image analysis, text extraction, concordance development, citation extraction, linguistic analysis, automated translation, and indexing. Continue reading “The Poetics of Non-Consumptive Reading”→
I recently proposed a sequence of lightning talks for the next Modern Language Association convention in Chicago (January 2014). The participants are tackling a literary issue that is not at all theoretical: the future of electronic literature. I’ve also built in a substantial amount of time for an open discussion between the audience and my participants—who are all key figures in the world of new media studies. And I’m thrilled that two of them—Dene Grigar and Stuart Moulthrop—just received an NEH grant dedicated to a similar question, which is documenting the experience of early electronic literature.
Electronic literature can be broadly conceived as literary works created for digital media that in some way take advantage of the unique affordances of those technological forms. Hallmarks of electronic literature (e-lit) include interactivity, immersiveness, fluidly kinetic text and images, and a reliance on the procedural and algorithmic capabilities of computers. Unlike the avant garde art and experimental poetry that is its direct forebear, e-lit has been dominated for much of its existence by a single, proprietary technology: Adobe’s Flash. For fifteen years, many e-lit authors have relied on Flash—and its earlier iteration, Macromedia Shockwave—to develop their multimedia works. And for fifteen years, readers of e-lit have relied on Flash running in their web browsers to engage with these works.
Flash is dying though. Apple does not allow Flash in its wildly popular iPhones and iPads. Android no longer supports Flash on its smartphones and tablets. Even Adobe itself has stopped throwing its weight behind Flash. Flash is dying. And with it, potentially an entire generation of e-lit work that cannot be accessed without Flash. The slow death of Flash also leaves a host of authors who can no longer create in their chosen medium. It’s as if a novelist were told that she could no longer use a word processor—indeed, no longer even use words. Continue reading “Electronic Literature after Flash (MLA14 Proposal)”→
Not so long ago a video of a flock of starlings swooping and swirling as one body in the sky went viral. Only two minutes long, the video shows thousands of birds over the River Shannon in Ireland, pouring themselves across the clouds, each bird following the one next to it. The birds flew not so much in formation as they flew in the biological equivalent of phase transition. This phenomenon of synchronized bird flight is called a murmuration. What makes the murmuration hypnotic is the starlings’ seemingly uncoordinated coordination, a thousand birds in flight, like fluid flowing across the skies. But there’s something else as well. Something else about the murmuration that appeals to us at this particular moment, that helps to explain this video’s virality.
The murmuration defies our modern understanding of crowds. Whether the crazed seagulls of Hitchcock’s The Birds, the shambling hordes of zombies that seem to have infected every strain of popular culture, or the thousands upon thousands of protestors of the Arab Spring, we are used to chaotic, disorganized crowds, what Elias Canetti calls the “open” crowd (Canetti 1984). Open crowds are dense and bound to grow denser, a crowd that itself attracts more crowds. Open crowds cannot be contained. They erupt. Continue reading “From a Murmur to a Drone”→
Attention artists, creators, theorists, teachers, curators, and archivists of electronic literature!
I’m putting together an e-lit roundtable for the Modern Language Association Convention in Chicago next January. The panel will be “Electronic Literature after Flash” and I’m hoping to have a wide range of voices represented. See the full CFP for more details. Abstracts due March 15, 2013.
Here (finally) is the talk I gave at the 2012 MLA Convention in Seattle. I was on Lori Emerson’s Reading Writing Interfaces: E-Literature’s Past and Present panel, along with Dene Grigar, Stephanie Strickland, and Marjorie Luesebrink. Lori’s talk on e-lit’s stand against the interface-free aesthetic worked particularly well with my own talk, which focused on Erik Loyer’s Strange Rain. I don’t offer a reading of Strange Rain so much as I use the piece as an entry point to think about interfaces—and my larger goal of reframing our concept of interfaces.
Today I want to talk about Strange Rain, an experiment in digital storytelling by the new media artist Erik Loyer.
Strange Rain came out in 2010 and runs on Apple iOS devices—the iPhone, iPod Touch, and iPad. As Loyer describes the work, Strange Rain turns your iPad into a “skylight on a rainy day.” You can play Strange Rain in four different modes. In the wordless mode, dark storm clouds shroud the screen, and the player can touch and tap its surface, causing columns of rain to pitter patter down upon the player’s first-person perspective. The raindrops appear to splatter on the screen, streaking it for a moment, and then slowly fade away. Each tap also plays a note or two of a bell-like celesta.
The other modes build upon this core mechanic. In the “whispers” mode, each tap causes words as well as raindrops to fall from the sky.
The “story” mode is the heart of Strange Rain. Here the player triggers the thoughts of Alphonse, a man standing in the rain, pondering a family tragedy.
And finally, with the most recent update of the app, there’s a fourth mode, the“feeds” mode. This allows players to replace the text of the story with tweets from a Twitter search, say the #MLA12 hashtag.
Note that any authorial information—Twitter user name, time or date—is stripped from the tweet when it appears,as if the tweet were the player’s own thoughts, making the feed mode more intimate than you might expect.
Like many of the best works of electronic literature, there are a number of ways to talk about Strange Rain, a number of ways to frame it. Especially in the wordless mode, Strange Rain fits alongside the growing genre of meditation apps for mobile devices, apps meant to calm the mind and sooth the spirit—like Pocket Pond:
In Pocket Pond, every touch of the screen creates a rippling effect.
The digital equivalent of a miniature zen garden, these apps allow us to contemplate minimalistic nature scenes on devices built by women workers in a FoxConn factory in Chengdu, China.
It’s appropriate that it’s the “wordless mode” that provides the seemingly most unmediated or direct experience of Strange Rain, when those workers who built the device upon which it runs are all but silent or silenced.
The “whispers” mode, meanwhile, with its words falling from the sky, recalls the trope in new media of falling letters—words that descend on the screen or even in large-scale multimedia installation pieces such as Camille Utterback and Romy Achituv’s Text Rain (1999).
And of course, the story mode even more directly situates Strange Rain as a work of electronic literature, allowing the reader to tap through “Convertible,” a short story by Loyer, which, not coincidentally I think, involvesa car crash, another long-standing trope of electronic literature.
As early as 1994, in fact, Stuart Moulthrop asked the question, “Why are there so many car wrecks in hypertext fiction?” (Moulthrop, “Crash” 5). Moulthrop speculated that it’s because hypertext and car crashes share the same kind of “hyperkinetic hurtle” and “disintegrating sensory whirl” (8). Perhaps Moulthrop’s characterization of hypertext held up in 1994…
…(though I’m not sure it did), but certainly today there are many more metaphors one can use to describe electronic literature than a car crash. And in fact I’d suggest that Strange Rain is intentionally playing with the car crash metaphor and even overturning it with its slow, meditative pace.
At the same time as this reflective component of Strange Rain, there are elements that make the work very much a game, featuring what any player of modern console or PC games would find familiar: achievements, unlocked by triggering particular moments in the story. Strange Rain even shows up on the iOS’s “Game Center.”
The way users can tap through Alphonse’s thoughts in Strange Rain recalls one of Moulthrop’s own works, the post-9/11 Pax, which Moulthrop calls, using a term from John Cayley, a “textual instrument”—as if the piece were a musical instrument that produces text rather than music.
We could think of Strange Rain as a textual instrument, then, or to use Noah Wardrip-Fruin’s reformulation of Cayley’s idea, as “playable media.” Wardrip-Fruin suggests that thinking of electronic literature in terms of playable media replaces a rather uninteresting question—“Is this a game?”—with a more productive inquiry, “How is this played?”
There’s plenty to say about all of these framing elements of Strange Rain—as an artwork, a story, a game, an instrument—but I want to follow Wardrip-Fuin’s advice and think about the question, how is Strange Rain played? More specifically, what is its interface? What happens when we think about Strange Rain in terms of the poetics of motion and touch?
Let me show you a quick video of Erik Loyer demonstrating the interface of Strange Rain, because there are a few characteristics of the piece that are lost in my description of it.
A key element that I hope you can see from this video is that the dominant visual element of Strange Rain—the background photograph—is never entirely visible on the screen. The photograph was taken during a tornado watch in Paulding County in northwest Ohio in 2007 and posted as a Creative Commons image on the photo-sharing site Flickr. But we never see this entire image at once on the iPad or iPhone screen. The boundaries of the photograph exceed the dimensions of the screen, and Strange Rain uses the hardware accelerometer to detect your motion, your movements. So that when you tilt the iPad even slightly, the image tilts slightly in the opposite direction. It’s as if there’s a larger world inside the screen, or rather, behind the screen. And this world is broader and deeper than what’s seen on the surface. Loyer described it to me this way: it’s “like augmented reality, but without the annoying distraction of trying to actually see the real world through the display” (Loyer 1).
This kinetic screen is one of the most compelling features of Strange Rain. As soon as you pick up the iPad or iPhone with Strange Rain running, it reacts to you. The work interacts with you before you even realize you’re interacting with it. Strange Rain taps into a kind of “camcorder subjectivity”—the entirely naturalized practice we now have of viewing the world through devices that have cameras on one end and screens on the other. Think about older videocameras, which you held up to your eye, and you saw the world straight through the camera. And then think of Flip cams or smartphone cameras we hold out in front of us. We looked through older videocameras as we filmed. We look at smartphone cameras as we film.
So when we pick up Strange Rain we have already been trained to accept this camcorder model, but we’re momentarily taken aback, I think, to discover that it doesn’t work quite the way we think it should. That is, it’s as if we are shooting a handheld camcorder onto a scene we cannot really control.
This aspect of the interface plays out in interesting ways. Loyer has an illustrative story about the first public test of Strange Rain. As people began to play the piece, many of them held it up over their heads so that “it looked like the rain was falling on them from above—many people thought that was the intended way to play the piece” (Loyer 1).
That is, people wanted it to work like a camcorder, and when it didn’t, they themselves tried to match their exterior actions to the interior environment of the piece.
There’s more to say about the poetics of motion with Strange Rain but I want to move on to the idea of touch. We’ve seen how touch propels the narrative of Strange Rain. Originally Loyer had planned on having each tap generate a single word, though he found that to be too tedious, requiring too many taps to telegraph a single thought (Loyer 1). It was, oddly enough in a work of playable media that was meant to be intimate and contemplative, too slow. Or rather, it required too much action—too much tapping—on the part of reader. So much tapping destroyed the slow, recursive feeling of the piece. It becomes frantic instead of serene.
Loyer tweaked the mechanic then, making each tap produce a distinct thought. Nonetheless, from my own experience and from watching other readers, I know that there’s an urge to tap quickly. In the story mode of Strange Rain you sometimes get caught in narrative loops—which again is Loyer playing with the idea of recursivity found in early hypertext fiction rather than merely reproducing it. Given the repetitive nature of Strange Rain, I’ve seen people want to fight against the system and tap fast. You see the same thought five times in a row, and you start tapping faster, even drumming using multiple fingers. And the piece paradoxically encourages this, as the only way to bring about a conclusion is to provoke an intense moment of anxiety for Alphonse, which you do by tapping more frantically.
I’m fascinated by with this tension between slow tapping and fast tapping—what I call haptic density—because it reveals the outer edges of the interface of the system. Quite literally.
Move from three fingers to four—easy to do when you want to bring Alphonse to a crisis moment—and the iPad translates your gestures differently. Four fingers tells the iPad you want to swipe to another application, the Windows equivalent of ALT-TAB. The multi-touch interface of the iPad trumps the touch interface of Strange Rain. There’s a slipperiness of the screen. The text is precipitously and perilously fragile and inadvertently escapable. The immersive nature of new media that years ago Janet Murray highlighted as an essential element of the form is entirely an illusion.
I want to conclude then by asking a question: what happen when we begin to think differently about interfaces? We usually think of an interface as a shared contact point between two distinct objects. The focus is on what is common. But what if we begin thinking—and I think Strange Rain encourages this—what if we begin thinking about interfaces in terms of difference. Instead of interfaces, what about thresholds, liminal spaces between two distinct elements. How does Strange Rain or any piece of digital expressive culture have both an interface, and a threshold, or thresholds? What are the edges of the work? And what do we discover when we transgress them?
Every scholarly community has its disagreements, its tensions, its divides. One tension in the digital humanities that has received considerable attention is between those who build digital tools and media and those who study traditional humanities questions using digital tools and media. Variously framed as do vs. think, practice vs. theory, or hack vs. yack, this divide has been most strongly (and provocatively) formulated by Stephen Ramsay. At the 2011 annual Modern Language Association convention in Los Angeles, Ramsay declared, “If you are not making anything, you are not…a digital humanist.”
I’m going to step around Ramsay’s argument here (though I recommend reading the thoughtful discussion that ensued on Ramsay’s blog). I mention Ramsay simply as an illustrative example of the various tensions within the digital humanities. There are others too: teaching vs. research, universities vs. liberal arts colleges, centers vs. networks, and so on. I see the presence of so many divides—which are better labeled as perspectives—as a sign that there are many stakeholders in the digital humanities, which is a good thing. We’re all in this together, even when we’re not.
I’ve always believed that these various divides, which often arise from institutional contexts and professional demands generally beyond our control, are a distracting sideshow to the true power of the digital humanities, which has nothing to do with production of either tools or research. The heart of the digital humanities is not the production of knowledge; it’s the reproduction of knowledge. I’ve stated this belief many ways, but perhaps most concisely on Twitter: [blackbirdpie url=”http://twitter.com/samplereality/statuses/26563304351″]The promise of the digital is not in the way it allows us to ask new questions because of digital tools or because of new methodologies made possible by those tools. The promise is in the way the digital reshapes the representation, sharing, and discussion of knowledge. We are no longer bound by the physical demands of printed books and paper journals, no longer constrained by production costs and distribution friction, no longer hampered by a top-down and unsustainable business model. And we should no longer be content to make our work public achingly slowly along ingrained routes, authors and readers alike delayed by innumerable gateways limiting knowledge production and sharing.
I was riffing on these ideas yesterday on Twitter, asking, for example, what’s to stop a handful of of scholars from starting their own academic press? It would publish epub books and, when backwards compatibility is required, print-on-demand books. Or what about, I wondered, using Amazon Kindle Singles as a model for academic publishing. Imagine stand-alone journal articles, without the clunky apparatus of the journal surrounding it. If you’re insistent that any new publishing venture be backed by an imprimatur more substantial than my “handful of scholars,” then how about a digital humanities center creating its own publishing unit?
It’s with all these possibilities swirling in my mind that I’ve been thinking about the MLA’s creation of an Office of Scholarly Communication, led by Kathleen Fitzpatrick. I want to suggest that this move may in the future stand out as a pivotal moment in the history of the digital humanities. It’s not simply that the MLA is embracing the digital humanities and seriously considering how to leverage technology to advance scholarship. It’s that Kathleen Fitzpatrick is heading this office. One of the founders of MediaCommons and a strong advocate for open review and experimental publishing, Fitzpatrick will bring vision, daring, and experience to the MLA’s Office of Scholarly Communication.
I have no idea what to expect from the MLA, but I don’t think high expectations are unwarranted. I can imagine greater support of peer-to-peer review as a replacement of blind review. I can imagine greater emphasis placed upon digital projects as tenurable scholarship. I can imagine the breadth of fields published by the MLA expanding. These are all fairly predictable outcomes, which might have eventually happened whether or not there was a new Office of Scholarly Communication at the MLA.
But I can also imagine less predictable outcomes. More experimental, more peculiar. Equally as valuable though—even more so—than typical monographs or essays. I can imagine scholarly wikis produced as companion pieces to printed books. I can imagine digital-only MLA books taking advantage of the native capabilities of e-readers, incorporating videos, songs, dynamic maps. I can image MLA Singles, one-off pieces of downloadable scholarship following the Kindle Singles model. I can imagine mobile publishing, using smartphones and GPS. I can imagine a 5,000-tweet conference backchannel edited into the official proceedings of the conference backchannel.
There are no limits. And to every person who objects, But, wait, what about legitimacy/tenure/cost/labor/& etc, I say, you are missing the point. Now is not the time to hem in our own possibilities. Now is not the time to base the future on the past. Now is not the time to be complacent, hesitant, or entrenched in the present.
William Gibson has famously said that “the future is already here, it’s just not very evenly distributed.” With the digital humanities we have the opportunity to distribute that future more evenly. We have the opportunity to distribute knowledge more fairly, and in greater forms. The “builders” will build and the “thinkers” will think, but all of us, no matter where we fall on this false divide, we all need to share. Because we can.
(Radiohead Crowd photograph courtesy of Flickr user Samuel Stroube / Creative Commons Licensed]
I recently received word that my proposal for a roundtable on videogame studies was accepted for the annual Modern Language Association Convention, to be held next January in Seattle, Washington. I’m very excited for myself and my fellow participants: Ed Chang, Steve Jones, Jason Rhody, Anastasia Salter, Tim Welsh, and Zach Whalen. (Updated with links to talks below)
This roundtable is particularly noteworthy in two ways. First, it’s a departure from the typical conference model in the humanities, namely three speakers each reading twenty-minute essays at an audience, followed by ten minutes of posturing and self-aggrandizement thinly disguised as Q&A. Instead, each speaker on the “Close Playing” roundtable will briefly (no more than six minutes each) lay out opening remarks or provocations, and then we’ll invite the audience to a long open discussion. Last year’s Open Professoriate roundtable followed a similar model, and the level of collegial dialogue between the panelists and the audience was inspiring (and even newsworthy)—and I hope the “Close Playing” roundtable can emulate that success.
The second noteworthy feature of the roundtable is the topic itself. Videogames—an incredibly rich form of cultural expression—have been historically unrepresented, if not entirely absent from the MLA. I noted this silence in the midst of the 2011 convention in Los Angeles:
How is it possible that I am the only person talking about videogames at #MLA11?
This is not to say there isn’t an interest in videogames at the MLA; indeed, I am convinced from the conversations I’ve had at the conference that there’s a real hunger to discuss games and other media forms that draw from the same cultural well as storytelling. Partly in the interest of promoting the critical study of videogames, and partly to serve as a successful model for future roundtable proposals (which I can assure you, the MLA Program Committee wants to see more of), I’m posting the “Close Playing” session proposal here (see also the original CFP).
We hope to see you in Seattle in January!
CLOSE PLAYING: LITERARY METHODS AND VIDEOGAME STUDIES
(As submitted to the MLA Program Committee
for the 2012 conference in Seattle, Washington)
Nearly fifteen years ago a contentious debate erupted in the emerging field of videogame studies between self-proclaimed ludologists and the more loosely-defined narratologists. At stake—or so it seemed at the time—was the very soul of videogame studies. Would the field treat games as a distinct cultural form, which demanded its own theory and methodology? Or were videogames to be considered “texts,” which could be analyzed using the same approaches literary scholars took to poetry, drama, and fiction? Were games mainly about rules, structure, and play? Or did games tell stories and channel allegories? Ludologists argued for the former, while many others defended the latter. The debate played out in conferences, blogs, and the early issues of scholarly e-journals such as Game Studies and Electronic Book Review.
In the ensuing years the debate has dissipated, as both sides have come to recognize that no single approach can adequately explore the rich and diverse world of videogames. The best scholarship in the field is equally attune to both the formal and thematic elements of games, as well as to the complex interplay between them. Furthermore, it’s become clear that ludologists mischaracterized literary studies as a strictly New Critical endeavor, a view that woefully overlooks the many insights contemporary literary scholarship can offer to this interdisciplinary field.
In the past few years scholars have begun exploring the whole range of possible literary approaches to games. Methodologies adopted from reception studies, reader-response theory, narrative theory, critical race and gender theory, queer studies, disability studies, rhetoric and composition, and textual studies have all contributed in substantive ways to videogames studies. This roundtable will focus on these contributions, demonstrating how various methods of literary studies can help us understand narrative-based games as well as abstract, non-narrative games (for example, Tetris). And as Jameson’s famous mantra “always historicize” reminds us, the roundtable will also address the wider social and historical context that surrounds games.
This topic is ideally suited for a roundtable format (rather than a panel of three papers) precisely because of the diversity of approaches, which are well-represented by the roundtable participants. Moreover, each presenter will limit his or her opening remarks to a nonnegotiable six minutes, focusing on the possibilities of one or two specific methodologies for close-reading videogames, rather than a comprehensive close reading of a single game. With six presenters, this means the bulk of the session time (roughly thirty-five minutes) will be devoted to an open discussion, involving both the panel and the audience.
“Close Playing: Literary Methods and Videogame Studies” will appeal to a broad swath of the MLA community. While many will find subject of videogames studies compelling enough by itself, the discussion will be relevant to those working in textual studies, media studies, and more broadly, the digital humanities. The need for this roundtable is clear: as we move toward the second decade of videogames studies, the field can no longer claim to be an emerging discipline; the distinguished participants on this panel—with the help of the audience—will survey the current lay of the land in videogame studies, but more importantly, point the way forward.
In a recent post on the group blog Play the Past, I wrote about the way torture-interrogation is often described by its proponents as a kind of game. I wrestled for a long time with the title of that post: “The Gamification of Interrogation.” Why? Because I oppose the general trend toward “gamifying” real world activities—mapping game-like trappings such as badges, points, and achievements onto otherwise routine or necessary activities.
A better term for such “gamification” is, as Margaret Robertson argues, pointsification. And I oppose it. I oppose pointsification and the gamification of life. Instead of “gamifying” activities in our daily life, we need to meanify them—imbue them with meaning. The things that we do to live, breathe, eat, laugh, love, and die, we need to see as worth doing in order to live, breathe, eat, laugh, love, and die. A leaderboard is not the path toward discovering this worthwhileness.
So, back to my title and what troubled me about it: “The Gamification of Interrogation.” I didn’t want this title to appear to be an endorsement of gamification. Perhaps the most cogent argument against both the practice of gamification and the rhetoric of the word itself comes from Ian Bogost, who observes that the contorted noun “gamification” acts as a kind of magic word, making “something seem easy to accomplish, even if it is in fact difficult.”
Ian proposes that we begin calling gamification what it really is. Because gamification seeks to “replace real incentives with fictional ones,” he argues that we call it “exploitationware”—a malevolent practice that exploits a user’s loyalty with fake rewards.
I’m skeptical that “exploitationware” will catch on, even among the detractor’s of gamification. It doesn’t exactly roll off the tongue. Its five syllables are so confrontational that even those who despise gamification might not be sympathetic to the word. Yet Ian himself suggests the way forward:
[quote]the best move is to distance games from the concept [of gamification] entirely, by showing its connection to the more insidious activities that really comprise it.[/quote]
And this is where my title comes in. I’ve connected gamification to an insidious activity, interrogation. I’m not trying to substitute a more accurate word for gamification. Rather, I’m using “gamification,” but in conjunction with human activities that absolutely should not be turned into a game. Activities that most people would recoil to conceive as a game.
The gamification of torture.
The gamification of radiation poisoning.
The gamification of child pornography.
This is how we disabuse the public of the ideology of gamification. Not by inventing another ungainly word, but by making the word itself ungainly. Making it ungamely.
Prison Tower Barb photo courtesy of Flickr user Dana Gonzales / Creative Commons License]
[This is the text, more or less, of the talk I delivered at the 2011 biennial meeting of the Society for Textual Scholarship, which took place March 16-18 at Penn State University. I originally planned on talking about the role of metadata in two digital media projects—a topic that would have fit nicely with STS’s official mandate of investigating print and digital textual culture. But at the last minute (i.e. the night before), I changed the focus of my talk, turning it into a thinly-veiled call for digital textual scholarship (primarily the creation of digital editions of print works) to rethink everything it does. (Okay, that’s an exaggeration. But I do argue that there’s a lot the creators of digital editions of texts should learn from born-digital creative projects.)
Also, it was the day after St. Patrick’s Day. And the fire alarm went off several times during my talk.
None of these events are related.]
The Poetics of Metadata and the Potential of Paradata
in We Feel Fine and The Whale Hunt
I once made fun of the tendency of academics to begin their papers by apologizing in advance for the very same papers they were about to begin. I’m not exactly going to apologize for this paper. But I do want to begin by saying that this is not the paper I came to give. I had that paper, it was written, and it was a good paper. It was the kind of paper I wouldn’t have to apologize for.
But, last night, I trashed it.
I trashed that paper. Call it the Danny Boy effect, I don’t know. But it wasn’t the paper I felt I needed to deliver, here, today.
Throughout the past two days I’ve detected a low level background hum in the conference rooms, a kind of anxiety about digital texts and how we interact with them. And I wanted to acknowledge that anxiety, and perhaps even gesture toward a way forward in my paper. So, I rewrote it. Last night, in my hotel room. And, well, it’s not exactly finished. So I want to apologize in advance, not for what I say in the paper, but for all the things I don’t say.
My original talk had positioned two online works by the new media artist Jonathan Harris as two complementary expressions of metadata. I had a nice title for that paper. I even coined a new word in my title.
But this title doesn’t work anymore.
I have a new title. It’s a bit more ambitious.
But at least I’ve still got that word I coined.
Paradata.
It’s a lovely word. And truth be told, just between you and me, I didn’t coin it. In the social sciences, paradata refers to data about the data collection process itself—say the date or time of a survey, or other information about how a survey was conducted. But there are other senses of the prefix “para” I’m trying to evoke. In textual studies, of course, para-, as in paratext, is what Genette calls the threshold of the text. I’m guessing I don’t have to say anything more about paratext to this audience.
But there’s a third notion of “para” that I want to play with. It comes from the idea of paracinema, which Jeffrey Sconce first described in 1996. Paracinema is a kind of “reading protocol” that valorizes what most audiences would otherwise consider to be cinematic trash. The paracinematic aesthetic redeems films that are so bad that they actually become worth watching—worth enjoying—and it does so in a confrontational way that seeks to establish a counter-cinema.
Following Sconce’s work, the videogame theorist Jesper Juul has wondered if there can be such a thing as paragames—illogical, improbable, and unreasonably bad games. Such games, Juul suggests, might teach us about our tastes and playing habits, and what the limits of those tastes are. And even more, such paragames might actually revel in their badness, becoming fun to play in the process.
Trying to tap into these three different senses of “para,” I’ve been thinking about paradata. And I’ve got to tell you, so far, it’s a mess. (And this part of my paper was actually a mess in the original version of my paper as well). My concept of paradata is a big mess and it may not mean anything at all.
This is what I have so far: paradata is metadata at a threshold, or paraphrasing Genette, data that exists in a zone between metadata and not metadata. At the same time, in many cases it’s data that’s so flawed, so imperfect that it actually tells us more than compliant, well-structured metadata does.
So let me turn now to We Feel Fine, a massive, ongoing digital databased storytelling project rich with metadata—and possibly, paradata.
We Feel Fine is an astonishing collection of tens of thousands of sentences extracted from tens of thousands of blog posts, all containing the phrase “I feel” or “I am feeling.” It was designed by new media artist Jonathan Harris and the computer scientist Sep Kamvar and launched in May 2006.
The project is essentially an automated script that visits thousands of blogs every minute, and whenever the script detects the words “I feel” or “I am feeling,” it captures that sentence and sends it to a database. As of early this year, the project has harvested 14 million expressions of emotions from 2.5 million people. And the site has done this at a rate of 10,000 to 15,000 “feelings” a day.
Let me repeat that: every day approximately 10,000 new entries are added to We Feel Fine.
The heart of the project appears to be the multifaceted interface that has six so-called “movements”—six ways of visualizing the data collected by We Feel Fine’s crawler.
The default movement is Madness, a swarm of fifteen-hundred colored circles and squares, each one representing a single sentence from a blog post, a single “feeling.” The circles contain text only, while the squares include images associated with the respective blog post.
The colors of the particles signify emotional valence, with shades of yellow representing more positive emotions, red signaling anger. Blue is associated with sad feelings, and so on. This graphic, by the way, comes from the book version of We Feel Fine.
The book came out in 2009. In it, Harris and Kamvar curate hundreds of the most compelling additions to We Feel Fine, as well as analyze the millions of blog posts they’ve collected with with extensive data visualizations—graphs, and charts, and diagrams.
The book is an amazing project in and of itself and deserves its own separate talk. It raises important questions about archives, authorship, editorial practices, the material differences between a dynamic online project and a static printed work, and so on. I’ll leaves aside these questions right now; instead, I want to turn to the site itself. Let’s look at the Madness movement in action.
(And here I went online and interacted with the site. Why don’t you do that too, and come back later?)
(Also, right about here a fire alarm went off. Which, semantically, makes no sense. The alarm turned on, but I said it went off.)
(I can’t reproduce the sound of that particular fire alarm going off. I bet you have some sort of alarm on your phone or something you could make go off, right?)
(No? You don’t? Or you’re just as confused about on and off as I am? Then enjoy this short video intermission, which interrupts my talk, which I’m writing and which you’re reading, about as intrusively as the alarms interrupted my panel.)
(Okay. Back to my talk, which I’m writing, and which you’re reading.)
In the Madness movement you can click on any single circle, and the “feeling” will appear at the top of the screen. Another click on that feeling will drill down to the original blog post in its original context. So what’s important here is that a single click transitions from the general to the particular, from the crowd to the individual. You can also click on the squares to show “feelings” that have an image associated with them. And you have the option to “save” these images, which sends them to a gallery, just about the only way you can be sure to ever find any given image in We Feel Fine again.
At the top of the screen are are six filters you can use to narrow down what appears in the Madness movement. Working right to left, you can search by date, by location, the weather at that location at the time of the original blog post, the age of the blogger, the gender of the blogger, and finally, the feeling itself that is named in the blog post. While every item in the We Feel Fine database will have the feeling and date information attached to it, the age, gender, location, and weather fields are populated only for those items in which that information is publicly available—say a LiveJournal or Blogger profile that lists that information, or a Flickr photo that’s been geotagged.
What I want to call your attention to before I run through the other five movements of We Feel Fine is that these filters depend upon metadata. By metadata, I mean the descriptive information the database associates with the original blog post. This metadata not only makes We Feel Fine browsable, it makes it possible. The metadata is the data. The story—if there is one to be found in We Feel Fine—emerges only through the metadata.
You can manipulate the other five movements using these filters. At first, for example, the Murmurs movement displays a reverse chronological streaming, like movie credits, of the most recent emotions. The text appears letter-by-letter, as if it were being typed. This visual trick heightens the voyeuristic sensibility of We Feel Fine and makes it seem less like a database and more like a narrative, or even more to the point, like a confessional.
The Montage movement, meanwhile, organizes the emotions into browsable photo galleries:
By clicking on a photo and selecting save, you can add photos to a permanent “gallery.” Because the database grows so incredibly fast, this is the only way to ensure that you’ll be able to find any given photograph again in the future. There’s a strong ethos of ephemerality in We Feel Fine. To use one of Marie-Laure Ryan’s metaphors for a certain kind of new media, We Feel Fine is a kaleidoscope, an assemblage of fragments always in motion, never the same reading or viewing experience twice. We have little control over the experience. It’s only through manipulating the filters that we can hope to bring even a little coherency to what we read.
The next of the five movements is the Mobs movement. Mobs provides five separate data visualization of the most recent fifteen-hundred feelings. One of the most interesting aspects of the Mobs movement is that it highlights those moments when the filters don’t work, or at least not very well, because of missing metadata.
For instance, clicking the Age visualizations tells us that 1,223 (of the most recent 1,500) feelings have no age information attached to them. Similarly, the Location visualization draws attention to the large number of blog posts that lack any metadata regarding their location.
Unlike many other massive datamining projects, say, Google’s Ngram Viewer, We Feel Fine turns its missing metadata into a new source of information. In a kind of playful return of the repressed, the missing metadata is colorfully highlighted—it becomes paradata. The null set finds representation in We Feel Fine.
The Metrics movement is the fourth movement. And it shows what Kamvar and Harris call the “most salient” feelings, by which they mean “the ways in which a given population differs from the global average.”
Right now, for example, we see that “Crazy” is trending 3.8 times more than normal, while people are feeling “alive” 3.1 times more than usual. (Good for them!). Here again we see an ability to map the local against the global. It addresses what I see as one of the problems of large-scale data visualization projects, like the ones that Lev Manovich calls “cultural analytics.”
Ngram and the like are not forms of distant reading. There’s distant reading, and then there’s simply distance, which is all they offer. We Feel Fine mediates that distance, both visually, and practically.
(And here I was going to also say the following, but I was already in hot water at the conference for my provocations, so I didn’t say it, but I’ll write it here: Cultural analytics echo a totalitarian impulse for precise vision and control over broad swaths of populations.)
And finally, the Mounds movement, which simply shows big piles of emotion, beginning with whatever feeling is the most common at the moment, and moving on down the line towards less common emotions. The Mounds movement is at once the least useful visualization but also the most playful, with its globs that jiggle as you move your cursor over them.
(Obviously you can’t see it above, in the static image but…) The mounds convey what game designers call “juiciness.” As Jesper Juul characterizes juiciness, it’s “excessive positive feedback in response to the player’s actions.” Or, as one game designer puts it, a juicy game “will bounce and wiggle and squirt…it feels alive and responds to everything that you do.”
Harris’s work abounds with juicy, playful elements, and they’re not just eye candy. They are part of the interface, part of the design, and they make We Feel Fine welcoming, inviting. You want to spend time with it. Those aren’t characteristics you’d normally associate with a database. And make no mistake about it. We Feel Fine is a database. All of these movements are simply its frontend—a GUI Java applet written in Processing that obscures a very deliberate and structured data flow.
The true heart of We Feel Fine is not the responsive interface, but the 26,000 lines of code running on 5 different servers, and the MySQL database that stores the 10,000 new feelings collected each and every day. In their book, Kamvar and Harris provide an overview of the dozen or so main components that make up We Feel Fine’s backend.
It begins with a URL server that maintains the list of URLs to be crawled and the crawler itself, which runs on a single dedicated server.
Pages retrieved by the crawler are sent to the “Feeling Indexer,” which locates the words “feel” or “feeling” in the blog post. The adjective following “feel” or “feeling” is matched against the “emotional lexicon”—a list of 2,178 feelings that are indexed by We Feel Fine. If the emotion is not in the lexicon, it won’t be saved. That emotion is dead to We Feel Fine. But if the emotion does match the index, the script extracts the sentence with that feeling and any other information available (this is where the gender, location, and date data are parsed).
Next there’s the actual MySQL database, which stores the following fields for each data item: the extracted sentence, the feeling, the date, time, post URL, weather, and gender, age, and location information.
Then there’s an open API server and several other client applications. And finally, we reach the front end.
Now, why have I just taken this detour into the backend of We Feel Fine?
Because, if we pay attention to the hardware and software of We Feel Fine, we’ll notice important details that might otherwise escape us. For example, I don’t know if you noticed from the examples I showed earlier, but all of the sentences in We Feel Fine are stripped of their formatting. This is because the Perl code in the backend converts all of the text to lowercase, removes any HTML tags, and eliminates any non-alphanumeric characters:
The algorithm tampers with the data. The code mediates the raw information. In doing so, We Feel Fine makes both an editorial and aesthetic statement.
In fact, once we understand some of the procedural logic of We Feel Fine, we can discover all sorts of ways that the database proves itself to be unreliable.
I’ve already mentioned that if you express a feeling that is not among the 2,178 emotions tabulated, then your feeling doesn’t count. But there’s also the tricky language misdirection the algorithm pulls off, in which the same “feeling” is interpreted by the machine to be the same, no matter how it is used in the sentence. In this way, the machine exhibits the same kind of “naïve empiricism” (using Johanna Drucker’s dismissive phrase) that some humanists do interpreting quantitative data.
And finally, consider many of the images in the Montage movement. When there are multiple images on a blog page, the crawler only grabs the biggest one—and not biggest in dimensions, but biggest in file size, because that’s easier for the algorithm to detect—and this image often ends up being the header image for the blog, rather than connected to the actual feeling itself, as in this example.
The star pattern happens to be a sidebar image, rather than anything associated with the actual blog post that states the feeling:
So We Feel Fine forces associations. In experimental poetry or electronic literature communities, these kinds of random associations are celebrated. The procedural creation of art, literature, or music has a long tradition.
But in a database that seeks to be a representative “almanac of human emotions”? We’re in new territory there.
But in fact, it is representative, in the sense that human emotions are fungible, ephemeral, disjunctive, and, let’s face, sometimes random.
Let me bring this full circle, by returning to the revised title of my talk. I mentioned at the beginning that I felt this low-grade but pervasive concern about digital work these past few days at STS. I’ve heard questions like Are we doing everything we can to make digital editions accessible, legible, readable, and teachable? Where are we failing, some people have wondered. Why are we failing? Or at least, Why have we not yet reached the level of success that many of the very same people at this conference were predicting ten or fifteen or, dare I say it, twenty years ago?
Maybe because we’re doing it wrong.
I want to propose that we can learn a lot from We Feel Fine as we exit out the far end of what some media scholars have called the Gutenberg Parenthesis.
What can we learn from We Feel Fine?
Four things:
It’s inviting
It’s paradata
It’s open
It’s juicy
Imagine if textual scholars built their digital editions and archives using these four principles.
Think about We Feel Fine and what makes work. Most importantly, We Feel Fine is a compelling reading experience. It’s not daunting. There’s a playful balance between interactivity and narrative coherence.
Secondly, and this goes back to my idea of paradata. Harris and Kamvar are not afraid to corrupt the source data, or to create metadata that blurs the line between metadata and not-metadata. They are not afraid to play with their sources, and for the most part, they are up front about how they’re playing with them.
This relates to the third feature of We Feel Fine that we should learn from. It’s open. Some of the source code is available. The list of emotions is available. There’s an open API, which anyone can use to build their own application on top of We Feel Fine, or more generally extract data from.
And finally, it’s juicy. I admit, this is probably not a term many textual scholars use in their research, but it’s essential for the success of We Feel Fine. The text responds to you. It’s alive in your hands, and I don’t think there’s much more we could ever ask from a text.
Bibliography
Drucker, Johanna. 2010. “Humanistic Approaches to the Graphical Expression of Interpretation” presented at the Hyperstudio: Digital Humanities at MIT, May 20, Cambridge, MA. http://mitworld.mit.edu/video/796.
Genette, Gerard. 1997. Paratexts: Thresholds of Interpretation. Cambridge: Cambridge University Press.
Juul, Jesper. 2010. A Casual Revolution: Reinventing Video Games and Their Players. Cambridge, MA: MIT Press.
Ryan, Marie-Laure. 2001. Narrative as Virtual Reality: Immersion and Interactivity in Literature and Electronic Media. Baltimore: Johns Hopkins University Press.
Sconce, Jeffrey. 1995. “‘Trashing’ the academy: taste, excess, and an emerging politics of cinematic style.” Screen 36 (4) (December 1): 371-393.
A roundtable discussion of specific approaches and close playings that explore the methodological contribution of literary studies toward videogame studies. 300-word abstract and 1-page bio to Mark Sample (samplereality@gmail.com) by March 15.
All participants must be MLA members by April 7. Also note that this is a proposed special session; the MLA Program Committee will have the final say on the roundtable’s acceptance.
[Controllers photo courtesy of Flickr user Kimli / Creative Commons License]
This special issue of DHQ invites essays that consider the study of literature and the category of the literary to be an essential part of the digital humanities. We welcome essays that consider how digital technologies affect our understanding of the literary— its aesthetics, its history, its production and dissemination processes, and also the traditional practices we use to critically analyze it. We also seek critical reflections on the relationships between traditional literary hermeneutics and larger-scale humanities computing projects. What is the relationship between literary study and the digital humanities, and what should it be? We welcome essays that approach this topic from a wide range of critical perspectives and that focus on diverse objects of study from antiquity to the present as well as born-digital forms.
Please submit an abstract of no more than 1,000 words and a short CV to Jessica Pressman and Lisa Swanstrom at <DHQliterary@gmail.com> by Feb. 15, 2011. We will reply by March 15, 2011 and request that full-length papers of no more than 9,000 words be submitted by *July 15, 2011*.


")









































