I’m spending July in Cádiz, Spain, with my family and a bunch of students from Davidson College. The other weekend we visited Granada, home of the Alhambra. Built by the last Arabic dynasty on the Iberian peninsula in the 13th century, the Alhambra is a stunning palace overlooking the city below. The city of Granada itself—like several other cities in Spain—is a palimpsest of Islamic, Jewish, and Christian art, culture, and architecture.
Take the streets of Granada. In the Albayzín neighborhood the cobblestone streets are winding, narrow alleys, branching off from each other at odd angles. Even though I’ve wandered Granada several times over the past decade, it’s easy to get lost in these serpentine streets. The photograph above (Flickr source) of the Albayzín, shot from the Alhambra, can barely reveal the maze that these medieval Muslim streets form. The Albayzín is a marked contrast to the layout of historically Christian cities in Spain. Influenced by Roman design, a typical Spanish city features a central square—the Plaza Mayor—from which streets extend out at right angles toward the cardinal points of the compass. Whereas the Muslim streets are winding and organic, the Christian streets are neat and angular. It’s the difference between a labyrinth and a grid.
It just so happened that on our long bus ride to Granada I finished playing Anchorhead, Michael Gentry’s monumental work of interactive fiction (IF) from 1998. Even if you’ve never played IF, you likely recognize it when you see it, thanks to the ongoing hybridization of geek culture with pop culture. Entirely text-based, these story-games present puzzles and narrative situations that you traverse through typed commands, like GO NORTH, GET LAMP, OPEN JEWELED BOX, etc. As for Anchorhead, it’s a Lovecraftian horror with cosmic entities, incestual families, and the requisite insane asylum. Anchorhead also includes a mainstay of early interactive fiction: a maze.
Two of them in fact.
It’s difficult to overstate the role of mazes in interactive fiction. Will Crowther and Don Woods’ Adventure (or Colossal Cave) was the first work of IF in the mid-seventies. It also had the first maze, a “maze of twisty little passages, all alike.” Later on Zork would have a maze, and so would many other games, including Anchorhead. Mazes are so emblematic of interactive fiction that the first scholarly book on the subject references Adventure‘s maze in its title: Nick Montfort’s Twisty Little Passages: An Approach to Interactive Fiction (MIT Press, 2003). Mazes are also singled out in the manual for Inform 7, a high level programming language used to create many contemporary works of interactive fiction. As the official Inform 7 “recipe book” puts it, “Many old-school IF puzzles involve journeys through the map which are confused, randomised or otherwise frustrated.” Mazes are now considered passé in contemporary IF, but only because they were used for years to convey a sense of disorientation and anxiety.
And so, there I was in Granada having just played one of the most acclaimed works of interactive fiction ever. It occurred to me then, among the twisty little passages of Granada, that a relationship exists between the labyrinthine alleys of the Albayzín and the way interactive fiction has used mazes.
See, the usual way of navigating interactive fiction is to use cardinal directions. GO WEST. SOUTHEAST. OPEN THE NORTH DOOR. The eight points of the compass rose is an IF convention that, like mazes, goes all the way back to Colossal Cave. The Inform 7 manual briefly acknowledges this convention in its section on rooms:
In real life, people are seldom conscious of their compass bearing when walking around buildings, but it makes a concise and unconfusing way for the player to say where to go next, so is generally accepted as a convention of the genre.
Let’s dig into this convention a bit. Occasionally, it’s been challenged (Aaron Reed’s BlueLacuna comes to mind), but for the most part, navigating interactive fiction with cardinal directions is simply what you expect to do. It’s essentially a grid system that helps players mentally map the game’s narrative spaces. Witness my own map of Anchorhead, literally drawn on graph paper as I played the game (okay, I drew it on OneNote on an iPad, but you get the idea):
My partial map of Anchorhead, drawn by hand
And when IF wants to confuse, frustrate, or disorient players, along comes the maze. Labyrinths, the kind evoked by the streets of the Albayzín, defy the grid system of Western logic. Mazes in interactive fiction are defined by the very breakdown of the compass. Direction don’t work anymore. The maze evokes otherness by defying rationality.
When the grid/maze dichotomy of interactive fiction is mapped onto actual history—say the city of Granada—something interesting happens. You start to see the the narrative trope of the maze as an essentially Orientalist move. I’m using “Orientalist” here in the way Edward Said uses it, a name for discourse about the Middle East that mysticizes yet disempowers the culture and its people. As Said describes it, Orientalism is part of a larger project of dominating that culture and its people. Orientalist tropes of the Middle East include ahistorical images that present an exotic, irrational counterpart to the supposed logic of European modernity. In an article in the European Journal of Cultural Studies about the representation of Arabs in videogames, Vít Ŝisler provides a quick list of such tropes. They include “motifs such as headscarves, turbans, scimitars, tiles and camels, character concepts such as caliphs, Bedouins, djinns, belly dancers and Oriental topoi such as deserts, minarets, bazaars and harems.” In nearly every case, for white American and European audiences these tropes provide a shorthand for an alien other.
My argument is this:
Interactive fiction relies on a Christian-influenced, Western European-centric sense of space. Grid-like, organized, navigable. Mappable. In a word, knowable.
Occasionally, to evoke the irrational, the unmappable, the unknowable, interactive fiction employs mazes. The connection of these textual mazes to the labyrinthine Middle Eastern bazaar that appears in, say Raiders of the Lost Ark, is unacknowledged and usually unintentional.
We cannot truly understand the role that mazes play vis-à-vis the usual Cartesian grid in interactive fiction unless we also understand the interplay between these dissimilar ways of organizing spaces in real life, which are bound up in social, cultural, and historical conflict. In particular, the West has valorized the rigid grid while looking with disdain upon organic irregularity.
Notwithstanding exceptions like Lisa Nakamura and Zeynep Tufekci, scholars of digital media in the U.S. and Europe have done a poor job looking beyond their own doorsteps for understanding digital culture. Case in point: the “Maze” chapter of 10 PRINT CHR$(205.5+RND(1)); : GOTO 10 (MIT Press, 2012), where my co-authors and I address the significance of mazes, both in and outside of computing, with nary a mention of non-Western or non-Christian labyrinths. In hindsight, I see the Western-centric perspective of this chapter (and others) as a real flaw of the book.
I don’t know why I didn’t know at the time about Laura Marks’ Enfoldment and Infinity: An Islamic Genealogy of New Media Art (MIT Press, 2010). Marks doesn’t talk about mazes per se, but you can imagine the labyrinths of Albayzín or the endless maze design generated by the 10 PRINT program as living enactments of what Marks calls “enfoldment.” Marks sees enfoldment as a dominant feature of Islamic art and describes it as the way image, information, and the infinite “enfold each other and unfold from one another.” Essentially, image gives way to information which in turn is an index (an impossible one though) to infinity itself. Marks argues that this dynamic of enfoldment is alive and well in algorithmic digital art.
With Marks, Granada, and interactive fiction on my mind, I have a series of questions. What happens when we shift our understanding of mazes from non-Cartesian spaces meant to confound players to transcendental expressions of infinity? What happens when we break the convention in interactive fiction by which grids are privileged over mazes? What happens when we recognize that even with something as non-essential to political power as a text-based game, the underlying procedural system reinscribes a model that values one valid way of seeing the world over another, equally valid way of seeing the world?
Header Image: Anh Dinh, “Albayzin from Alhambra” on Flickr (August 10, 2013). Creative Commons BY-NC license.
In 1965 the singer-songwriter Phil Ochs told an audience that “a protest song is a song that’s so specific you can’t mistake it for bullshit.” Ochs was introducing his anti-war anthem “I Ain’t Marching Anymore”—but also taking a jab at his occasional rival Bob Dylan, whose expressionistic lyrics by this time resembled Rimbaud more than Guthrie. The problem with Dylan, as far as Ochs was concerned, wasn’t that he had gone electric. It was that he wasn’t specific. You never really knew what the hell he was singing about. Meanwhile Ochs’ debut album in 1964 was an enthusiastic dash through fourteen very specific songs. The worst submarine disaster in U.S. history. The Cuban Missile Crisis. The murder of Emmett Till, the assassination of Medgar Evers. The sparsely produced album was called All the News That’s Fit to Sing, a play on the New York Times slogan “All the News That’s Fit to Print.” But more than mere parody, the title signals Ochs’ intention to best the newspaper at its own game, pronouncing and denouncing, clarifying and explaining, demanding and indicting the events of the day.
Ochs and the sixties protest movement are far removed from today’s world. There’s the sheer passage of time, of course. But there’s also been a half century of profound social and technological change, the greatest being the rise of computational culture. Networks, databases, videogames, social media. What, in this landscape, is the 21st century equivalent of a protest song? What is the modern version of a song so specific in its details, its condemnation, its anger, that it could not possibly be mistaken for bullshit?
One answer is the protest bot. A computer program that reveals the injustice and inequality of the world and imagines alternatives. A computer program that says who’s to praise and who’s to blame. A computer program that questions how, when, who and why. A computer program whose indictments are so specific you can’t mistake them for bullshit. A computer program that does all this automatically.
Bots are small automated programs that index websites, edit Wikipedia entries, spam users, scrape data from pages, launch denial of service attacks, and other assorted activities, both mundane and nefarious. On Twitter bots are mostly spam, but occasionally, they’re creative endeavors.
The bots in this small creative tribe that get the most attention—the @Horse_ebooks of the world (though @horse_ebooks would of course turn out later not to be a bot)—are surreal, absurd, purposeless for the sake of purposelessness. There is a bot canon forming, and it includes bots like @tofu_product, @TwoHeadlines, @everycolorbot, and @PowerVocabTweet. This emerging bot canon reminds me of the literary canon, because it values a certain kind of bot that generates a certain kind of tweet.
To build on this analogy to literature, I think of Repression and Recovery, Cary Nelson’s 1989 effort to reclaim a strain of American poetry excluded from traditional literary histories of the 20th century. The crux of Nelson’s argument is that there were dozens of progressive writers in the early to mid-20th century whose poems provided inconvenient counter-examples to what was considered “poetic” by mainstream culture. These poems have been left out of the canon because they were not “literary” enough. Nelson accuses literary critics of privileging poems that display ambivalence, inner anguish, and political indecision over ones that are openly polemical. Poems that draw clear distinctions between right and wrong, good and bad, justice and injustice are considered naïve by the academic establishment and deemed not worthy of analysis or teaching, and certainly not worthy of canonization. It’s Dylan over Ochs all over again.
A similar generalization might be made about what is valued in bots. But rather than ambivalence and anguish being the key markers of canon-worthy bots, it’s absurdism, comical juxtaposition, and an exhaustive sensibility (the idea that while a human cannot tweet every word or every unicode character, a machine can). Bots that don’t share these traits—say, a bot that tweets the names of toxic chemicals found in contaminated drinking water or tweets civilian deaths from drone attacks—are likely to be left out of the bot canon.
I don’t care much about the canon, except as a means to clue us in to what stands outside the canon. We should create and pay attention to bots that don’t fit the canon. And protest bots should be among these bots. We need bots that are not (or not merely) funny, random, or comprehensive. We need bots that are the algorithmic equivalent of the Wobblies’ Little Red Songbook, bots that fan the flames of discontent. We need bots of conviction.
Bots of Conviction
In his classic account of the public sphere, that realm of social life in which individuals discuss and shape public opinion, the German sociologist Jürgen Habermas describes a brief historical moment in the early 19th century in which the “journalism of conviction” thrived. The journalism of conviction did not simply compile notices as earlier newspapers had done; nor did the journalism of conviction seek to succeed purely commercially, serving the private interests of its owners or shareholders. Rather, the journalism of conviction was polemical, political, fervently debating the needs of society and the role of the state.
We may have lost the journalism of conviction, but it’s not too late to cultivate bots of conviction. I want to sketch out five characteristics of bots of conviction. I’ll name them here and describe each in more details. Bots of conviction are topical, data-based, cumulative, oppositional, and uncanny.
Topical. Asked where the ideas for his song came from, Ochs once pulled out a Newsweek and smiled, “From out of here.” Though probably apocryphal, the anecdote highlights the topical nature of protest songs, and by extension, protest bots. They are not about lost love or existential anguish. They are about the morning news—and the daily horrors that fail to make it into the news.
Data-based. Bots of conviction are based in data, which is another way of saying they don’t make this shit up. They draw from research, statistics, spreadsheets, databases. Bots have no subconscious, so any imagery they use should be taken literally. Protest bots give witness to the world we inhabit.
Cumulative. It is the nature of bots to do the same thing over and over again, with only slight variation. Repetition with a difference. Any single iteration may be interesting, but it is in the aggregate that a protest bot’s tweets attain power. The repetition builds on itself, the bot relentlessly riffing on its theme, unyielding and overwhelming, a pile-up of wreckage on our screens.
Oppositional. This is where the conviction comes in. Whereas the bot pantheon is populated by l’bot pour l’bot, protest bots take a stand. Society being what it is, this stance will likely be unpopular, perhaps even unnerving. Just as the most affecting protest songs made their audiences feel uncomfortable, bots of conviction challenge us to consider our own complicity in the wrongs of the world.
Uncanny. I’m using uncanny in the Freudian sense here, but without the psychodrama. The uncanny is the return of the repressed. The appearance of that which we had sought to keep hidden. I have to thank Zach Whalen for highlighting this last characteristic, which he frames in terms of visibility. Protests bots often reveal something that was hidden; or conversely, they might purposefully obscure something that had been in plain sight.
It’s one thing to talk about bots of conviction in theory. It’s quite another to talk about them in practice. What does a bot of conviction actually look like?
Consider master botmaker Darius Kazemi’s @TwoHeadlines. On one hand, the bot is most assuredly topical, as it functions by yoking two distinct news headlines into a single, usually comical headline. The bot is obviously data-driven too; the bot scrapes the headline data directly from Google News. On the other hand, @TwoHeadlines is neither cumulative nor oppositional. The bot posts at a moderate pace of once per hour, but while the individual tweets accumulate they do not build up to something. There is no theme the algorithm compulsively revisits. Each tweet is a one-off one-liner. Most critically, though, the bot takes no stance. @TwoHeadlines reflects the news, but it does not reflect on the news. It may very well be Darius’ best bot, but it lacks all conviction.
What about another recent bot, Chuck Rybak’s @TheHigherDead? [Update: @TheHigherDead account has disappeared.] Chuck lampoons utopian ed-tech talk in higher education, putting jargon such as “disrupt” and “innovate” in the mouths of zombies. Chuck uses the affordances of the Twitter bio to sneak in a link to the Clayton Christensen Institute. Christensen is the Harvard Business School professor who popularized terms like “disruptive innovation” and “hybrid innovation”—ideas that when applied to K12 or higher ed appear to be little more than neo-liberal efforts to pare down labor costs and disempower faculty. When these ideas are actually put into action, we get the current crisis in the University of Wisconsin system, where Chuck teaches. @TheHigherDead is oppositional and uncanny, in the way that anything having to do with zombies is uncanny. It’s even topical, but is it a protest bot? It’s parody, but its data is too eclectic to be considered data-based. If @TheHigherDead mined actual news accounts and ed-tech blogs for more jargon and these phrases showed up in the tweets, the bot would rise beyond parody to protest.
@TwoHeadlines and @TheHigherDead are not protest bots, but then, they’re not supposed to be. I am unfairly applying my own criteria to it, but only to illustrate what I mean by the terms topical, data-based, cumulative, oppositional, and uncanny. It’s worth testing this criteria against another bot: Zach Whalen’s @ClearCongress. This bot retweets members of Congress after redacting a portion of the original tweet. The length of the redaction corresponds to the current congressional approval rate; the lower the approval rating, the more characters are blocked.
MT █ SENJOHNTHUNE: ▓▓▓▓▒ ▒▓▓▓▓▓▓▒ ▓▓▒▓ ▓▓▓▓ ▓▓▓▓▓CKET WITH NEW ▒▓▓▓▓▒ ▓▓▓▓▓▒▓▓▓▒▓ @▒▓▒▓▓▒▒ ▓▒▓▓▓▓▒▓▓▓▓▓▓▒▒▓▒▓▓▓▓▒
Assuming our senators and representatives post about current news and policies, the bot is topical. It is also data-driven, doubly-so, since it pulls from congressional accounts and up-to-date polling data from the Huffington Post. The bot is cumulative as well. Scrolling through the timeline you face an indecipherable wall of ▒▒▒▒ and ▓▓▓▓, a visual effect intensified by Twitter’s infinite scrolling. By obscuring text, the bot plays in the register of the visible and invisible—the uncanny. And despite not saying anything legible, @ClearCongress has something to say. It’s an oppositional bot, thematizing the disconnect between the will of the people and the rulers of the land. At the same time, the bot suggests that Congress has replaced substance with white noise, that all senators and representatives end up sounding the same, regardless of their politics, and that, most damning of all, Congress is ineffectual, all but useless.
Another illustrative protest bot likewise uses Congress as its target. Ed Summers’ @congressedits tweets whenever anonymous edits are made to Wikipedia from IP addresses associated with the U.S. Congress. [Update: Ed has removed @congressedits from Twitter, but the bot now posts intermittently on Mastodon.] In other words, whenever anyone in Congress—likely Congressional staffers, but conceivably representatives and senators themselves—attempts to edit a Wikipedia article anonymously, the bot flags that edit and calls attention to it. This is the uncanny hallmark of @congressedits: making visible that which others seek to hide, bringing transparency to a key source of information online, and in the process highlighting the subjective nature of knowledge production in online spaces. @congressedits operates in near real-time; these are not historical revisions to Wikipedia, they are edits that are happening right now. The bot is obviously data-driven too. Summers’ bot responds to data from Wikipedia’s API, but it also send us, the readers, directly to the diff page of that edit, where we can clearly see the specific changes made to the page. It turns out that many of the revisions are copyedits—fixing punctuation, spelling, or grammar. This revelation undercuts our initial cynical assumption that every anonymous Wikipedia edit from Congress is ideologically-driven. Yet it also supports the message of @ClearCongress. Congress is so useless that they have nothing better to do than fix comma splices on Wikipedia? Finally, there’s one more layer of @congressedits to mention, which speaks again to the issue of transparency. Summers has shared the code on Github, making it possible for others to programmatically develop customized clones, and there are dozens of such bots now, tracking changes to Wikipedia.
There are not many bots of conviction, but they are possible, as @ClearCongress and @congress-edits demonstrate. I’ve attempted to make several agit-bots myself, though when I started, I hadn’t thought through the five characteristics I describe above. In a very real sense, my theory about bots as a form of civic engagement grew out of my own creative practice.
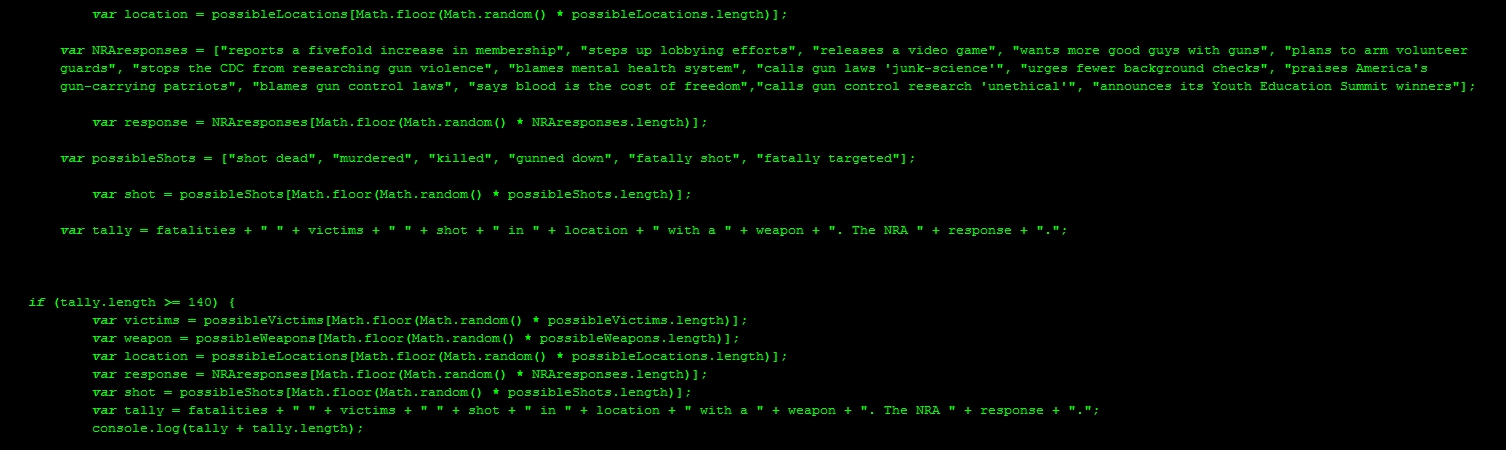
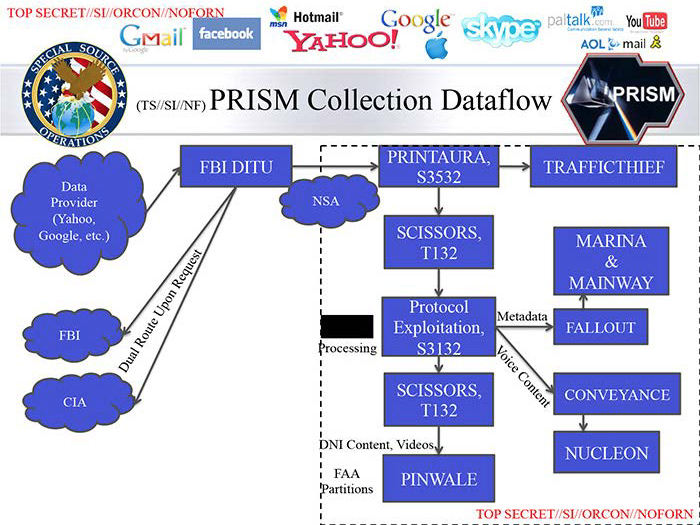
I made my first protest bot in the wake of the Snowden revelations about PRISM, the NSA’s downstream surveillance program. I created @NSA_PRISMbot. The bot is an experiment in speculative surveillance, imagining the kind of useless information the NSA might distill from its invasive data-gathering:
@NSA_PRISMbot is topical, of course, rooted in specificity. The Internet companies the bot names are the same services identified on the infamous NSA PowerPoint slide. When Microsoft later changed the name of SkyDrive to OneDrive, the bot even reflected that change. Similarly, @NSA_PRISMbot will occasionally flag (fake) social media activity using the list of keywords and search terms the Department of Homeland Security tracks on social media.
Any single tweet of NSA_PRISMbot may be clever, with humorous juxtapositions at work. But the real power of the bot is the way the individual invasions of privacy accumulate. The bot is like a devotional exercise, in which repetition is an attempt at deeper understanding.
I followed up @NSA_PRISMbot with @NSA_AllStars, whose satirical profile notes that it “honors the heroes behind @NSA_PRISMbot, who keep us safe from the bad guys.” This bot builds on the revelations that NSA workers and subcontractors had spied on their own friends and family.
The code of @nsa_allstars
The bot names names, including the various divisions of the NSA and the companies that are documented subcontractors for the NSA.
A Bot Canon of Anger
While motivated by conviction, neither of these NSA bots are explicit in their outrage. So here’s an angry protest bot, one I made out of raw emotion, a bitter compound of fury and despair. On May 23, 2014, Elliot Rodger killed six people and injured fourteen more near the campus of UC-Santa Barbara. In addition to my own anger I was moved by the grief of my friends, several of whom teach at UC Santa Barbara. It was Alan Liu’s heartfelt act of public bereavement that most clearly articulated what I sought in this protest bot:
What is the literary canon of anger that must back up that of consolation to give full-throated voice to #NotOneMore? →
Whereas Alan turns toward literature for a full-throated cry of anger, I turned toward algorithmic culture, to the margins of the computational world. I created a bot of consolation and conviction that—to paraphrase Phil Ochs in “When I’m Gone”—tweets louder than the guns.
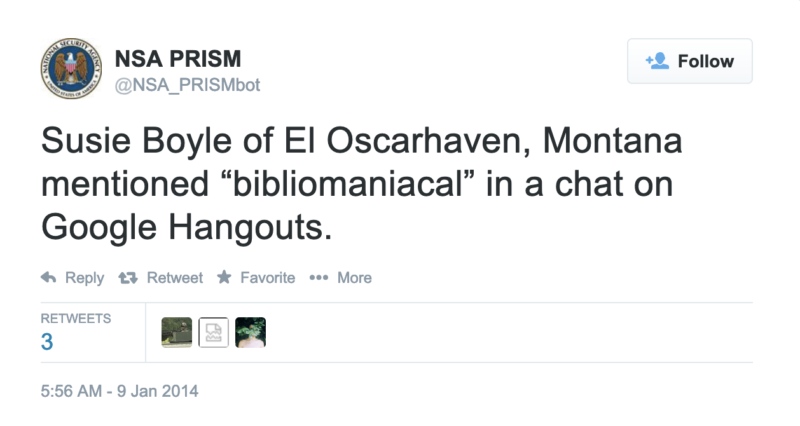
The bot I made is @NRA_Tally. It posts imagined headlines about mass shootings, followed by a fictionalized but believable response from the NRA:
@NRA_Tally
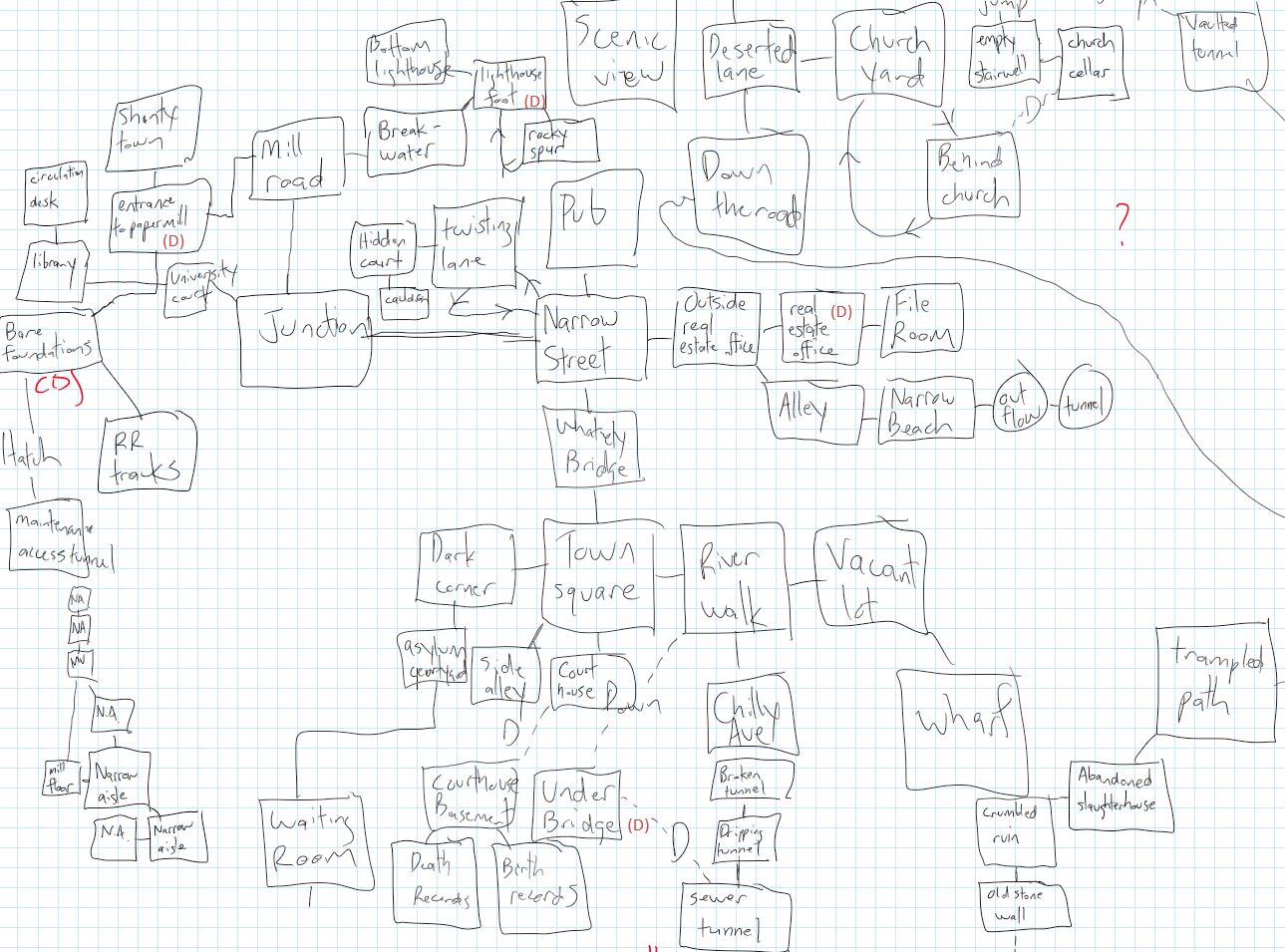
The bot is topical, grievously so. More critically, you cannot mistake it for bullshit. The bot is data-driven, populated with statistics from a database of over thirty years of mass shootings in the U.S. Here are the individual elements that make up the template of every @NRA_Tally tweet:
A number. The bot selects a random number between 4 (the threshold for what the FBI defines as mass murder) and 35 (just above the Virginia Tech massacre, the worst mass shooting in American history).
The victims. The victims are generalizations drawn from the historical record. Sadly this means teachers, college students, elementary school children.
Location. The city and state names have all been sites of mass shootings. I had considered either seeding the location with a huge list of cities or simply generating fake city names (which is what @NSA_PRISMbot does). I decided against these approaches, however, because I was determined to have @NRA_Tally act as a witness to real crimes.
Firearm. The bot randomly selects the deadly weapon from an array of 64 items, all handguns or rifles that have been used in a mass shooting in the United States. An incredible 75% of the weapons fired in mass shootings have been purchased legally, the killers abiding by existing gun regulations. Many of the guns were equipped with high-capacity magazines, again, purchased legally. The 140-character constraint of Twitter means some weapon names have been shortened, dropping, for example the words “semiautomatic” or “sawed-off.”
Response. This is a statement from the NRA in the form of a press release. Every possible response mirrors actual rhetorical moves the NRA has made after previous mass shootings. There are currently 14 stock responses, but the NRA has undoubtedly issued other statements of scapegoating and misdirection. @NRA_Tally is participatory in the sense that you can contribute to its database of responses. Simply submit a generalized yet documented response and I will incorporate it into the code.
@NRA_Tally is terrifying and unsettling, posing scenarios that go beyond the plausible into the realm of the super-real. It is an oppositional bot on several levels. It is obviously antagonistic toward the NRA. It is oppositional toward false claims that “guns don’t kill people,” purposefully foregrounding weapons over killers. It is even oppositional to social media itself, challenging the logic of following and retweeting. Who would be comfortable seeing such tragedies in their timeline on an hourly basis? Who would dare to retweet something that could be taken as legitimate news, thereby spreading unnecessary rumors and lies?
Protest Bots as Tactical Media
A friend who saw an early version of @NRA_Tally expressed unease about it, wondering whether or not the bot would be gratuitous. The bot canon is full of playful bots that are nonsensical and superfluous. @NRA_Tally is neither playful nor nonsensical, but is it superfluous?
No, it is not. @NRA_Tally, like all protest bots, is an example of tactical media. Rita Raley, another friend at UCSB, literally wrote the book on tactical media, a form of media activism that engages in a “micropolitics of disruption, intervention, and education.” Tactical media targets “the next five minutes” rather than some far off revolutionary goal. As tactical media, protest bots do not offer solutions. Instead they create messy moments that destabilize narratives, perspectives, and events.
How might such destabilization work in the case of @NRA_Tally?
As Salon points out, it is the NRA’s strategy—this is a long term policy rather than a tactical maneuver—to shut down debate by accusing anyone who talks about gun control as politicizing the victims’ death. A bot of conviction, however, cannot be shut down by such ironic accusations. A protest bot cannot be accused of dishonoring the victims when there are no actual victims. As the bot inexorably piles on headline after headline, it becomes clear that the center of gravity of each tweet is the name of the weapon itself. The bot is not about victims. It is about guns and the organization that makes such preventable crimes possible.
The public debate about gun violence is severely limited. This bot attempts to unsettle it, just for a minute. And, because this is a bot that doesn’t back down and cannot cower and will tweet for as long as I let it, it has many of these minutes to make use of. Bots of conviction are also bots of persistence.
Adorno once said that it is the role of the cultural critic to present society a bill it cannot pay. Adorno would not have good things to say about computational culture, let alone social media. But even he might appreciate that not only can protest bots present society a bill it cannot pay, they can do so at the rate of once every two minutes. They do not bullshit around.
An earlier version of this essay on Protest Bots can be found on Medium.
This summer I attended the first annual Institute for Liberal Arts Digital Scholarship (ILiADS) at Hamilton College. It was an inspiring conference, highlighting the importance of collaborative faculty/student digital work at small liberal arts colleges. My own school, Davidson College, had a team at ILiADS (Professor Suzanne Churchill, Instructional Technologist Kristen Eshleman, and undergraduate Andrew Rikard, working on a digital project about the modernist poet Mina Loy). Meanwhile I was at the institute to deliver the keynote address on the final day. Here is the text of my keynote, called “Your Mistake was a Vital Connection: Oblique Strategies for the Digital Humanities.”
Forty years ago, the musician Brian Eno and painter Peter Schmidt published the first edition of what they called Oblique Strategies.Oblique Strategies resembled a deck of playing cards, each card black on one side, and white on the other, with a short aphoristic suggestion on the white side.
Doctorow, Cory. Oblique Strategies Deck, PO Box, The Barbican, London, UK. Photography, June 14, 2013. https://www.flickr.com/photos/doctorow/9041086636/.
These suggestions were the strategies—the oblique strategies—for overcoming creative blocks or artistic challenges. The instructions that came with the cards described their use: “They can be used as a pack…or by drawing a single card from the shuffled pack when a dilemma occurs in a working situation. In this case, the card is trusted even if its appropriateness is quite unclear.”
When we look at some of the strategies from the original deck of 55 cards, we can see why their appropriateness might appear unclear:
From Broackes, Victoria, and Geoffrey Marsh, eds. David Bowie Is… Special edition. London : New York: Victoria & Albert Museum, 2013.
And other strategies:
Make sure nobody wants it.
Cut a vital connection
Make a blank valuable by putting it in an exquisite frame
Do something boring
Honor thy error as a hidden intention
And one of my favorites:
Repetition is a form of change.
Brian Eno explained the origins of the cards in an interview on KPFA radio in San Francisco in 1980: The cards were a system designed to, as Eno put it, “foil the critic” in himself and to “encourage the child.” They were strategies for catching our internal critics off-guard. Eno elaborated:
The Oblique Strategies evolved from me being in a number of working situations when the panic of the situation—particularly in studios—tended to make me quickly forget that there were others ways of working and that there were tangential ways of attacking problems that were in many senses more interesting than the direct head-on approach.
If you’re in a panic, you tend to take the head-on approach because it seems to be the one that’s going to yield the best results. Of course, that often isn’t the case—it’s just the most obvious and—apparently—reliable method. The function of the Oblique Strategies was, initially, to serve as a series of prompts which said, “Don’t forget that you could adopt *this* attitude,” or “Don’t forget you could adopt *that* attitude.”
Other ways of working. There are other ways of working. That’s what the Oblique Strategies remind us. Eno and Schmidt released a second edition in 1978 and a third edition in 1979, the year before Schmidt suddenly died. Each edition varied slightly. New strategies appeared, others were removed or revised.
For example, the 2nd edition saw the addition of “Go outside. Shut the door.” A 5th edition in 2001 added the strategy “Make something implied more definite (reinforce, duplicate).” For a complete history of the various editions, check out Gregory Taylor’s indispensable Obliquely Stratigraphic Record. The cards—though issued in limited, numbered, editions—were legendary, and even more to the point, they were actually used.
David Bowie famously kept a deck of the cards on hand when he recorded his Berlin albums of the late seventies. His producer for these experimental albums was none other than Brian Eno. I’m embarrassed to say that I didn’t know about Bowie’s use of the Oblique Strategies
I knew about Tristan Tzara’s suggestion in the 1920s to write poetry by pulling words out of a bag. I knew about Brion Gysin’s cut-up method, which profoundly influenced William Burroughs. I knew about John Cage’s experimental compositions, such as his Motor Vehicle Sundown, a piece orchestrated by “any number of vehicles arranged outdoors.” Or Cage’s use of chance operations, in which lists of random numbers from Bell Labs determined musical elements like pitch, amplitude, and duration. I knew how Jackson Mac Low similarly used random numbers to generate his poetry, in particular relying on a book called A Million Random Digits with 100,000 Normal Deviates to supply him with the random numbers (Zweig 85).
RAND Corporation. A Million Random Digits with 100,000 Normal Deviates, 1955. http://www.rand.org/pubs/monograph_reports/MR1418/index2.html.
I knew about the poet Alison Knowles’ “The House of Dust,” which is a kind of computer-generated cut-up written in Fortran in 1967. I even knew that Thom Yorke composed many of the lyrics of Radiohead’s Kid A using Tristan Tzara’s method, substituting a top hat for a bag.
But I hadn’t heard encountered Eno and Schmidt’s Oblique Strategies. Which just goes to show, however much history you think you know—about art, about DH, about pedagogy, about literature, about whatever—you don’t know the half of it. And I suppose the ahistorical methodology of chance operations is part of their appeal. Every roll of the dice, every shuffle of the cards, every random number starts anew. In his magisterial—and quite frankly, seemingly random—Arcades Project, Benjamin devotes an entire section to gambling, where his collection of extracts circles around the essence of gambling. “The basic principle…of gambling…consists in this,” says Alain in one of Benjamin’s extracts, “…each round is independent of the one preceding…. Gambling strenuously denies all acquired conditions, all antecedents…pointing to previous actions…. Gambling rejects the weighty past” (Benjamin 512). Every game is cordoned off from the next. Every game begins from the beginning. Every game requires that history disappear.
That’s the goal of the Oblique Strategies—to clear a space where your own creative history doesn’t stand in the way of you moving forward in new directions. Now in art, chance operations may be all well and good, even revered. But what does something like the Oblique Strategies have to do with the reason we’re here this week: research, scholarship, the production of knowledge? After all, isn’t rejecting “the weighty past” an anathema to the liberal arts?
Well, I think one answer goes back to Eno’s characterization of the Oblique Strategies: there are other ways of working. We can approach the research questions that animate us indirectly, at an angle. Forget the head-on approach for a while.
One way of working that I’ve increasingly become convinced is a legitimate—and much-needed form of scholarship—is deformance. Lisa Samuels and Jerry McGann coined this word, a portmanteau of deform and performance. It’s an interpretative concept premised upon deliberately misreading a text. For example, reading a poem backwards line-by-line. As Samuels and McGann put it, reading backwards “short circuits” our usual way of reading a text and “reinstalls the text—any text, prose or verse—as a performative event, a made thing” (Samuels & McGann 30). Reading backwards revitalizes a text, revealing its constructedness, its seams, edges, and working parts.
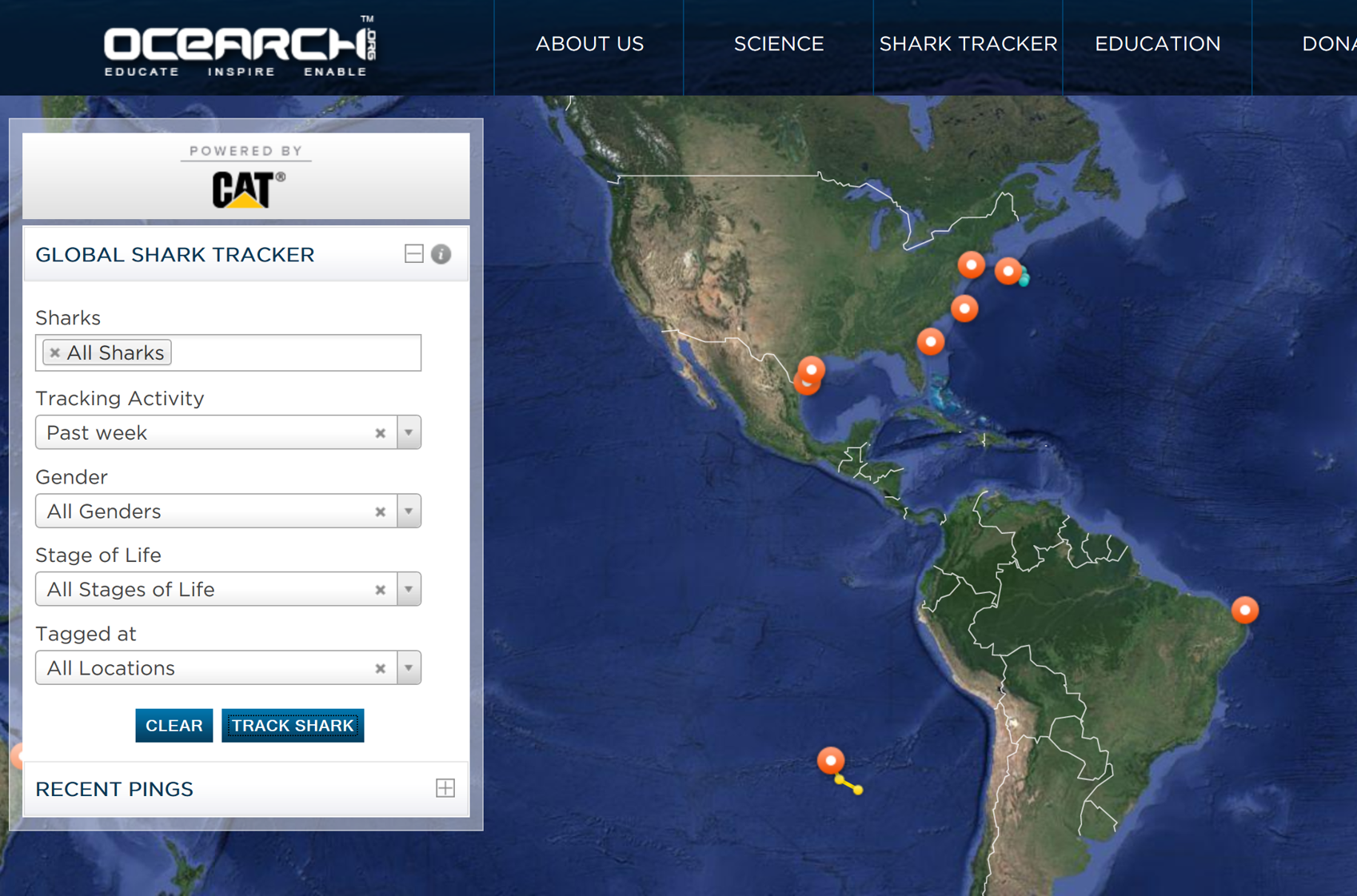
Let me give you an example of deformance. Mary Lee and Katharine are two social media stars, with tens of thousands of followers on Twitter each. They’re also great white sharks in the Atlantic Ocean, tagged with geotrackers by the non-profit research group OCEARCH. Whenever either of the sharks—or any of the dozens of other sharks that OCEARCH has tagged—surfaces longer than 90 seconds, the tags ping geo-orbiting satellites three times in order to triangulate a position. That data is then shared in real-time on OCEARCH’s site or app.
OCEARCH Tracking Map (screenshot)
The sharks’ Twitter accounts, I should say, are operated by humans. They’ll interact with followers, post updates about the sharks, tweet shark facts, and so on. But these official Mary Lee and Katharine accounts don’t automatically tweet the sharks’ location updates.
Sometime this summer—well, actually, it was during shark week—I thought wouldn’t it be cool to create a little bot, a little autonomous program, that automatically tweeted Mary Lee and Katharine’s location updates. But first I needed to get the data itself. I was able to reverse engineer OCEARCH’s website to find an undocumented API, a kind of programming interface that allows computer programs to talk to each other and share data with each other. OCEARCH’s database gives you raw JSON datathat looks like this to a human reader:
But to a computer reader, it looks like this:
Structured data is a thing of beauty.
Reverse engineering the OCEARCH API is not the deformance I’m talking about here. What I found when the bot started tweeting location updates of these two famous sharks was, it was kind of boring. Every few days one of the sharks would surface long enough to get a position, it would post to Twitter, and that was that.
21 July 2015 11:09:39 AM: Katharine pinged satellites at 33.76481, -75.01413. pic.twitter.com/nlGqhhpANG
Something was missing. I wanted to give this Twitter account texture, a sense of personality. I decided to make Mary Lee and Katharine writers. And they would share their writing with the world on this Twitter account. The only problem is, I don’t have time to be a ghost writer for two great white sharks.
So I’ll let a computer do that.
I asked some friends for ideas of source material to use as deformance pieces for the sharks. These would be texts that I could mangle or remix in order to come up with original work that I would attribute to the sharks. A friend suggested American Psycho—an intriguing choice for a pair of sharks, but not quite the vibe I was after. Mary Lee and Katharine are female sharks. I wanted to use women writers. Then Amanda French suggested Virginia Woolf’s novel Night and Day, which just happens to feature two characters named Katharine and Mary. It was perfect, and the results are magical.
Now, Katharine tweets odd mashed-up fragments from Night and Day, each one paired with historical location data from OCEARCH’s database. On December 9, 2014, Katharine was very close to the shore near Rhode Island, and she “wrote” this:
Katharine: Down all luxuriance and plenty to the verge of decency; and in the night, bereft of life (09-Dec-2014) pic.twitter.com/SEEsv3FBKm
In every case, the journal part of the tweet—the writing—is extracted randomly from complete text of Night and Day and then mangled by a Python program. These fragments, paired with the location and the character of a shark, stand on their own, and become new literary material. But they also expose the seams of the original source.
Whereas Katharine writes in prose fragments, I wanted Mary Lee to write poetry:
The line of heroes stands, godlike: Though we wander about, the tangled thread falls slack.
How does Mary Lee writer this? Her source material comes from the works of H.D.—Hilda Doolittle, whose avant-garde Imagist poems are perfect for the cut-up method.
I send you this, a single house of the hundred to freighted ships, baffled in wind and blast.
Mary Lee follows the cut-up method described by Brion Gysin decades ago. I’ve made a database of 1,288 lines of H.D.’s most anthologized poetry. Every tweet from Mary Lee is some combination of three of those 1,288 lines, along with slight typographic formatting. All in all, there are potentially 2 billion, 136 million and 719 thousand original poems that Mary Lee could write.
The snow is melted, we have always known you wanted us. My mind is reft.
What kind of project is @shark_girls? Is it a public humanities project—sharing actual data—dates, locations, maps—that helps people to think differently about wildlife, about the environment, about the interactions between humans and nature? Is it an art project, generating new, standalone postmodern poetry and prose? Is it a literary project, that lets us see Virginia Woolf and H.D. in a new light? Is it all three?
I’ll let other people decide. We can’t get too hung up on labels. What’s important to me is that whatever @shark_girls is about, it’s also about something else. As Susan Sontag wrote about literature: “whatever is happening, something else is always going on.” And the oblique nature of deformance will often point toward that something else. Deformance is a kind of oblique strategy for reading a poem. If the Oblique Strategies deck had a card for deformance it might read:
Work backwards.
Or maybe, simply,
Shuffle.
Another kind of deformance—another oblique strategy for reading—are Markov Chains. Markov chains are statistical models of texts or numbers, based on probability. Let’s say we have the text of Moby Dick.
Just eyeballing the first page we can see that certain words are more likely to be followed by some words than other words. For example, the pronoun “I” is likely to be followed by the verb “find” but not the word “the.” A two-gram Markov Chain looks at the way one pair of words is likely to be followed by a second pair of words. So the pair “I find” is likely to be followed by “myself growing” but not the pair of words “me Ishmael.” A three-gram Markov parses the source text into word triplets. The chain part of a Markov Chain happens when one of these triplets is followed by another triplet, but not necessarily the same triplet that appears in the source text. And then another triplet. And another. It’s a deterministic way to create texts, with each new block of the chain independent of the preceding blocks. Talk about rejecting the weighty past. If you work with a big enough source text, the algorithm generates sentences that are grammatically correct but often nonsensical.
Let’s generate some Markov chains of Moby Dick on the spot. Here’s a little script I made. If it takes a few seconds to load, that’s because every time it runs, it’s reading the entire text of Moby Dick and calculating all the statistical models on the fly. Then spitting out a 3-, 4-, or 5-gram Markov chain. The script tells you what kind of Markov n-gram it is. The script is fun to play around with, and I’ve used it to teach what I call deep textual hacks. When I show literature folks this deformance and teach them how to replace Moby Dick with a text from their own field or time period, they’re invariably delighted. When I show history folks this deformance and teach them how to replace Moby Dick with a primary source from their own field or time period, they’re invariably horrified. History stresses attentiveness to the nuances of a primary source document, not the way you can mangle that very same primary source. Yet, also invariably, my history colleagues realize what Samuels and McGann write about literary deformance is true of historical deformance as well: deformance revitalizes the original text and lets us see it fresh.
All of this suggests what ought to be another one of Brian Eno and Peter Schmidt’s Oblique Strategies:
Misreading is a form of reading.
And to go further, misreading can be a form of critical reading.
Now, let me get to the heart of the matter. I’ve been talking chance operations, deterministic algorithms, and other oblique strategies as a way to explore cultural texts and artifacts. But how do these oblique strategies fit in with the digital humanities? How might oblique strategies not only be another way to work in general, but specifically, another way to work with the digital scholarship and pedagogy we might otherwise more comfortably approach head-on, as Brian Eno put it.
Think about how we value—or say we value—serendipity in higher education. We often praise serendipity as a tool for discovery. When faculty hear that books are going into off-site storage, their first reaction is, how are we going to stumble upon new books when browsing the shelves?
A recent piece by the digital humanities Victorianist Paul Fyfe argues that serendipity has been operationalized, built right into the tools we use to discover new works and new connections between works (Fyfe 262). Serendipomatic, for example, is an online tool that came out of the Roy Rosenzweig Center for History and New Media. You can dump in your entire Zotero library, or even just a selection of text, and Serendipomatic will find sources from the Digital Public Library of America or Europeana that are connected—even if obliquely—to your citations. Let your sources surprise you, the tagline goes.
Tim Sherratt has created a number of bots that tweet out random finds from the National Library of Australia. I’ve done the same with the Digital Public Library of America, creating a bot that posts random items from the DPLA.Similarly, there’s @BookImages, which tweets random cat-pics images from the 3.3 million public domain images from pre-1922 books that the Internet Archive uploaded to Flickr.
Fyfe suggests that “these machines of serendipity sometimes offer simple shifts of perspective” (263)—and he’s totally right. And simple shifts of perspective are powerful experiences, highlighting the contingency and plurality of subjectivity.
But in all these cases, serendipity is a tool for discovery, not a mode of work itself. We think of serendipity as a way to discover knowledge, but not as a way to generate knowledge. This is where the oblique strategies come into play. They’re not strategies for discovery, they’re practices for creativity.
Let me state it simply: what if we did the exact opposite of what many of you have spent the entire week doing. Many of you have been here a whole week, thinking hard and working hard—which are not necessarily the same thing—trying to fulfill a vision, or at the very least, sketch out a vision. That is good. That is fine, necessary work. But what if we surrendered our vision and approached our digital work obliquely—even, blindly.
I’m imagining a kind of dada DH. A gonzo DH. Weird DH. Which is in fact the name of a panel I put together for the 2016 MLA in Austin in January. As I wrote in the CFP, “What would an avant-garde digital humanities look like? What might weird DH reveal that mainstream DH leaves out? Is DH weird enough already? Can we weird it more?”
My own answer to that last question is, yes. Yes, we can. Weird it more. The folks on the panel: Micki Kaufman, Shane Denson, Kim Knight, Jeremy Justus will all be sharing work that challenges our expectations about the research process, about the final product of scholarship, and even what counts as knowledge itself, as opposed to simply data, or information.
So many of the methodologies we use in the digital humanities come from the social sciences—network analysis, data visualization, GIS and mapping, computational linguistics. And that’s all good and I am 100 percent supportive of borrowing methodological approaches. But why do we only borrow from the sciences? What if—and this is maybe my broader point today—what if we look for inspiration and even answers from art? From artists. From musicians and poets, sculptors and quilters.
And this takes me back to my earlier question: what might a set of oblique strategies—originally formulated by a musician and an artist—look like for the digital humanities?
Well, we could simply take the existing oblique strategies and apply them to our own work.
Do something boring.
Maybe that’s something we already do. But I think we need a set of DH-specific oblique strategies. My first thought was to subject the original Oblique Strategies to the same kind of deterministic algorithm that I showed you with Moby-Dick, that is, Markov chains.
Here are a few of the Markov Chained Oblique Strategies my algorithm generated:
Breathe more human. Where is the you do?
Make what’s perfect more than nothing for as ‘safe’ and continue consistently.
Your mistake was a vital connection.
I love the koan-like feeling of these statements. The last one made so much sense that I worked it into the title of my talk: your mistake was a vital connection. And I truly believe this: our mistakes, in our teaching, in our research, are in fact vital connections. Connections binding us to each other, connections between domains of knowledge, connections between different iterations of our own work.
But however much I like these mangled oblique strategies, they don’t really speak specifically about our work in the digital humanities. So in the past few weeks, I’ve been trying to create DH-specific oblique strategies, programmatically.
The great thing about Markov chains is that you can combine multiple source texts, and the algorithm will treat them equally. My Moby Dick Markov Chains came from the entire text of the novel, but there’s no reason I couldn’t also dump in the text of Sense and Sensibility, creating a procedurally-generated mashup that combines n-grams from both novels into something we might call Moby Sense.
So I’m going to try something for my conclusion. And I have no idea if this is going to work. This could be a complete and utter failure. Altogether, taking into account the different editions of the Oblique Strategies, there are 155 different strategies. I’m going to combine those lines with texts that have circulated through the digital humanities community in the past few years. This source material includes Digital_Humanities, The Digital Humanities Manifesto, and a new project on Critical DH and Social Justice, among other texts. (All the sources are linked below.) I’ve thrown all these texts together in order to algorithmically generate my new DH-focused oblique strategies.
[At this point in my keynote I started playing around with the Oblique DH Generator. The version I debuted is on a stand-alone site, but I’ve also embedded it below. My talk concluded—tapered off?—as I kept generating new strategies and riffing on them. We then moved to a lively Q&A period, where I elaborated on some of the more, um, oblique themes of my talk. As nicely as this format worked at ILiADS, it doesn’t make for a very satisfying conclusion here. So I’ll wrap up with a new, equally unsatisfying conclusion, and then you can play with the generator below. And draw your own conclusions.]
My conclusion is this, then. A series a oblique strategies for the digital humanities that are themselves obliquely generated. The generator below is what I call a webtoy. But I’ve also been thinking about it as what Ted Nelson calls a “thinkertoy”—a toy that helps you think and “envision complex alternatives” (Dream Machines 52). In this case, the thinkertoy suggests alternative approaches to the digital humanities, both as a practice and as a construct (See Kirschenbaum on the DH construct). And it’s also just plain fun. For, as one of the generated oblique strategies for DH says, Build bridges between the doom and the scholarship. And what better way to do that than playing around?
Benjamin, Walter. The Arcades Project. Edited by Rolf Tiedemann. Translated by Howard Eiland and Kevin McLaughlin. Cambridge, Massachusetts: Belknap-Harvard UP, 1999.
Kirschenbaum, Matthew. “What Is ‘Digital Humanities,’ and Why Are They Saying Such Terrible Things about It?” Differences 25, no. 1 (2014): 46–63. doi:10.1215/10407391-2419997.
Nelson, Theodor H. Computer Lib/Dream Machines. 1st ed. Chicago: Hugo’s Book Service, 1974.
Samuels, Lisa, and Jerome McGann. “Deformance and Interpretation.” New Literary History 30, no. 1 (January 1, 1999): 25–56.
Sontag, Susan. “In Jerusalem.” The New York Review of Books, June 21, 2001. http://www.nybooks.com/articles/archives/2001/jun/21/in-jerusalem/.
Zweig, Ellen. “Jackson Mac Low: The Limits of Formalism.” Poetics Today 3, no. 3 (July 1, 1982): 79–86. doi:10.2307/1772391.
The Electronic Literature Organization’s annual conference was last week in Milwaukee. I hated to miss it, but I hated even more the idea of missing my kids’ last days of school here in Madrid, where we’ve been since January.
If I had been at the ELO conference, I’d have no doubt talked about bots. I thought I already said everything I had to say about these small autonomous programs that generate text and images on social media, but like a bot, I just can’t stop.
Here, then, is one more modest attempt to theorize bots—and by extension other forms of computational media. The tl;dr version is that there are two archetypes of bots: closed bots and green bots. And each of these archetypes comes with an array of associated characteristics that deepen our understanding of digital media. Continue reading “Closed Bots and Green Bots Two Archetypes of Computational Media“→
Mark Z. Danielewski’s House of Leaves is a massive novel about, among other things, a house that is bigger on the inside than the outside. Walt Whitman’s Leaves of Grass is a collection of poems about, among other things, the expansiveness of America itself.
What happens when these two works are remixed with each other? It’s not such an odd question. Though separated by nearly a century, they share many of the same concerns. Multitudes. Contradictions. Obsession. Physical impossibilities. Even an awareness of their own lives as textual objects.
To explore these connections between House of Leaves and Leaves of Grass I have created House of Leaves of Grass, a poem (like Leaves of Grass) that is for all practical purposes boundless (like the house on Ash Tree Lane in House of Leaves). Or rather, it is bounded on an order of magnitude that makes it untraversable in its entirety. The number of stanzas (from stanza, the Italian word for “room”) approximates the number of cells in the human body, around 100 trillion. And yet the container for this text is a mere 24K. Continue reading “no life no life no life no life: the 100,000,000,000,000 stanzas of House of Leaves of Grass”→
Seeking to have a rich discussion period—which we did indeed have—we limited our talks to about 12 minutes each. My presentation was therefore more evocative than comprehensive, more open-ended than conclusive. There are primary sources I’m still searching for and technical details I’m still sorting out. I welcome feedback, criticism, and leads.
An Account of Randomness in Literary Computing
Mark Sample
MLA 2013, Boston
There’s a very simple question I want to ask this evening:
Where does randomness come from?
Randomness has a rich history in arts and literature, which I don’t need to go into today. Suffice it to say that long before Tristan Tzara suggested writing a poem by pulling words out of a hat, artists, composers, and writers have used so-called “chance operations” to create unpredictable, provocative, and occasionally nonsensical work. John Cage famously used chance operations in his experimental compositions, relying on lists of random numbers from Bell Labs to determine elements like pitch, amplitude, and duration (Holmes 107–108). Jackson Mac Low similarly used random numbers to generate his poetry, in particular relying on a book called A Million Random Digits with 100,000 Normal Deviates to supply him with the random numbers (Zweig 85).
Million Random Digits with 100,000 Normal Deviates
Published by the RAND Corporation in 1955 to supply Cold War scientists with random numbers to use in statistical modeling (Bennett 135), the book is still in print—and you should check out the parody reviews on Amazon.com. “With so many terrific random digits,” one reviewer jokes, “it’s a shame they didn’t sort them, to make it easier to find the one you’re looking for.”
This joke actually speaks to a key aspect of randomness: the need to reuse random numbers, so that, say you’re running a simulation of nuclear fission, you can repeat the simulation with the same random numbers—that is, the same probability—while testing some other variable. In fact, most of the early work on random number generation in the United States was funded by either the U.S. Atomic Commission or the U.S. Military (Montfort et al. 128). The RAND Corporation itself began as a research and development arm of the U.S. Air Force.
Now the thing with going down a list of random numbers in a book, or pulling words out of hat—a composition method, by the way, Thom Yorke used for Kid A after a frustrating bout of writer’s block—is that the process is visible. Randomness in these cases produces surprises, but the source itself of randomness is not a surprise. You can see how it’s done.
What I want to ask here today is, where does randomness come from when it’s invisible? What’s the digital equivalent of pulling words out of a hat? And what are the implications of chance operations performed by a machine?
To begin to answer these questions I am going to look at two early works of electronic literature that rely on chance operations. And when I say early works of electronic literature, I mean early, from fifty and sixty years ago. One of these works has been well studied and the other has been all but forgotten.
My first case study is the Strachey Love Letter Generator. Programmed by Christopher Strachey, a close friend of Alan Turing, the Love Letter Generator is likely—as Noah Wardrip-Fruin argues—the first work of electronic literature, which is to say a digital work that somehow makes us more aware of language and meaning-making. Strachey’s program “wrote” a series of purplish prose love letters on the Ferranti Mark I Computer—the first commercially available computer—at Manchester University in 1952 (Wardrip-Fruin “Digital Media” 302):
DARLING SWEETHEART
YOU ARE MY AVID FELLOW FEELING. MY AFFECTION CURIOUSLY CLINGS TO YOUR PASSIONATE WISH. MY LIKING YEARNS FOR YOUR HEART. YOU ARE MY WISTFUL SYMPATHY: MY TENDER LIKING.
YOURS BEAUTIFULLY
M. U. C.
Affectionately known as M.U.C., the Manchester University Computer could produce these love letters at a pace of one per minute, for hours on end, without producing a duplicate.
The “trick,” as Strachey put it in a 1954 essay about the program (29-30), is its two template sentences (Myadjectivenounadverbverb your adjectivenoun and You are my adjectivenoun) in which the nouns, adjectives, and adverbs are randomly selected from a list of words Strachey had culled from a Roget’s thesaurus. Adverbs and adjectives randomly drop out of the sentence as well, and the computer randomly alternates the two sentences.
The Love Letter Generator has attracted—for a work of electronic literature—a great deal of scholarly attention. Using Strachey’s original notes and source code (see figure to the left), which are archived at the Bodleian Library at the University of Oxford, David Link has built an emulator that runs Strachey’s program, and Noah Wardrip-Fruin has written a masterful study of both the generator and its historical context.
As Wardrip-Fruin calculates, given that there are 31 possible adjectives after the first sentence’s opening possessive pronoun “My” and then 20 possible nouns that could that could occupy the following slot, the first three words of this sentence alone have 899 possibilities. And the entire sentence has over 424 million combinations (424,305,525 to be precise) (“Digital Media” 311).
A partial list of word combinations for a single sentence from the Strachey Love Letter Generator
On the whole, Strachey was publicly dismissive of his foray into the literary use of computers. In his 1954 essay, which appeared in the prestigious trans-Atlantic arts and culture journal Encounter (a journal, it would be revealed in the late 1960s, that was primarily funded by the CIA—see Berry, 1993), Strachey used the example of the love letters to illustrate his point that simple rules can generate diverse and unexpected results (Strachey 29-30). And indeed, the Love Letter Generator qualifies as an early example of what Wardrip-Fruin calls, referring to a different work entirely, the Tale-Spin effect: a surface illusion of simplicity which hides a much more complicated—and often more interesting—series of internal processes (Expressive Processing 122).
Wardrip-Fruin coined this term—the Tale-Spin effect—from Tale-Spin, an early story generation system designed by James Mehann at Yale University in 1976. Tale-Spin tended to produce flat, plodding narratives, though there was the occasional existential story:
Henry Ant was thirsty. He walked over to the river bank where his good friend Bill Bird was sitting. Henry slipped and fell in the river. He was unable to call for help. He drowned.
But even in these suggestive cases, the narratives give no sense of the process-intensive—to borrow from Chris Crawford—calculations and assumptions occurring behind the interface of Tale-Spin.
In a similar fashion, no single love letter reveals the combinatory procedures at work by the Mark I computer.
JEWEL MOPPET
MY AFFECTION LUSTS FOR YOUR TENDERNESS. YOU ARE MY PASSIONATE DEVOTION: MY WISTFUL TENDERNESS. MY LIKING WOOS YOUR DEVOTION. MY APPETITE ARDENTLY TREASURES YOUR FERVENT HUNGER.
YOURS WINNINGLY
M. U. C.
This Tale-Spin effect—the underlying processes obscured by the seemingly simplistic, even comical surface text—are what draw Wardrip-Fruin to the work. But I want to go deeper than the algorithmic process that can produce hundreds of millions of possible love letters. I want to know, what is the source of randomness in the algorithm? We know Strachey’s program employs randomness, but where does that randomness come from? This is something the program—the source code itself—cannot tell us, because randomness operates at a different level, not at the level of code or software, but in the machine itself, at the level of hardware.
In the case of Strachey’s Love Letter Generator, we must consider the computer it was designed for, the Mark I. One of the remarkable features of this computer was that it had a hardware-based random number generator. The random number generator pulled a string of random numbers from what Turing called “resistance noise”—that is, electrical signals produced by the physical functioning of the machine itself—and put the twenty least significant digits of this number into the Mark I’s accumulator—its primary mathematical engine (Turing). Alan Turing himself specifically requested this feature, having theorized with his earlier Turing Machine that a purely logical machine could not produce randomness (Shiner). And Turing knew—like his Cold War counterparts in the United States—that random numbers were crucial for any kind of statistical modeling of nuclear fission.
I have more to say about randomness in the Strachey Love Letter Generator, but before I do, I want to move to my second case study. This is an early, largely unheralded work called SAGA. SAGA was a script-writing program on the TX-0 computer. The TX-0 was the first computer to replace vacuum tubes with transistors and also the first to use interactive graphics—it even had a light pen.
The TX-0 was built at Lincoln Laboratory in 1956—a classified MIT facility in Bedford, Massachusetts chartered with the mission of designing the nation’s first air defense detection system. After TX-0 proved that transistors could out-perform and outlast vacuum tubes, the computer was transferred to MIT’s Research Laboratory of Electronics in 1958 (McKenzie), where it became a kind of playground for the first generation of hackers (Levy 29-30).
In 1960, CBS broadcast an hour-long special about computers called “The Thinking Machine.” For the show MIT engineers Douglas Ross and Harrison Morse wrote a 13,000 line program in six weeks that generated a climactic shoot-out scene from a Western.
Several computer-generated variations of the script were performed on the CBS program. As Ross told the story years later, “The CBS director said, ‘Gee, Westerns are so cut and dried couldn’t you write a program for one?’ And I was talked into it.”
The TX-0’s large—for the time period—magnetic core memory was used “to keep track of everything down to the actors’ hands.” As Ross explained it, “The logic choreographed the movement of each object, hands, guns, glasses, doors, etc.” (“Highlights from the Computer Museum Report”).
And here, is the actual output from the TX-0, printed on the lab’s Flexowriter printer, where you can get a sense of the way SAGA generated the play:
In the CBS broadcast, Ross explained the narrative sequence as a series of forking paths.
Each “run” of SAGA was defined by sixteen initial state variables, with each state having several weighted branches (Ross 2). For example, one of the initial settings is who sees whom first. Does the sheriff see the robber first or is it the other way around? This variable will influence who shoots first as well.
There’s also a variable the programmers called the “inebriation factor,” which increases a bit with every shot of whiskey, and doubles for every swig straight from the bottle. The more the robber drinks, the less logical he will be. In short, every possibility has its own likely consequence, measured in terms of probability.
The MIT engineers had a mathematical formula for this probability (Ross 2):
But more revealing to us is the procedure itself of writing one of these Western playlets.
First, a random number was set; this number determined the probability of the various weighted branches. The programmers did this simply by typing a number following the RUN command when they launched SAGA; you can see this in the second slide above, where the random number is 51455. Next a timing number established how long the robber is alone before the sheriff arrives (the longer the robber is alone, the more likely he’ll drink). Finally each state variable is read, and the outcome—or branch—of each step is determined.
What I want to call your attention to is how the random number is not generated by the machine. It is entered in “by hand” when one “runs” the program. In fact, launching SAGA with the same random number and the same switch settings will reproduce a play exactly (Ross 2).
In a foundational work in 1996 called The Virtual Muse Charles Hartman observed that randomness “has always been the main contribution that computers have made to the writing of poetry”—and one might be tempted to add, to electronic literature in general (Hartman 30). Yet the two case studies I have presented today complicate this notion. The Strachey Love Letter Generator would appear to exemplify the use of randomness in electronic literature. But—and I didn’t say this earlier—the random numbers generated by the Mark I’s method tended not to be reliably random enough; remember, random numbers often need to be reused, so that the programs that run them can be repeated. This is called pseudo-randomness. This is why books like the RAND Corporation’s A Million Random Digits is so valuable.
But the Mark I’s random numbers were so unreliable that they made debugging programs difficult, because errors never occurred the same way twice. The random number instruction eventually fell out of use on the machine (Campbell-Kelly 136). Skip ahead 8 years to the TX-0 and we find a computer that doesn’t even have a random number generator. The random numbers must be entered manually.
The examples of the Love Letters and SAGA suggest at least two things about the source of randomness in literary computing. One, there is a social-historical source; wherever you look at randomness in early computing, the Cold War is there. The impact of the Cold War upon computing and videogames has been well-documented (see, for example Edwards, 1996 and Crogan, 2011), but few have studied how deeply embedded the Cold War is in the software algorithms and hardware processes themselves of modern computing.
Second, randomness does not have a progressive timeline. The story of randomness in computing—and especially in literary computing—is neither straightforward nor self-evident. Its history is uneven, contested, and mostly invisible. So that even when we understand the concept of randomness in electronic literature—and new media in general—we often misapprehend its source.
WORKS CITED
Bennett, Deborah. Randomness. Cambridge, MA: Harvard University Press, 1998. Print.
Turing, A.M. “Programmers’ Handbook for the Manchester Electronic Computer Mark II.” Oct. 1952. Web. 23 Dec. 2012.
Wardrip-Fruin, Noah. “Digital Media Archaeology: Interpreting Computational Processes.” Media Archaeology: Approaches, Applications, and Implications. Ed by. Erkki Huhtamo & Jussi Parikka. Berkeley, California: University of California Press, 2011. Print.
—. Expressive Processing: Digital Fictions, Computer Games, and Software Sudies. MIT Press, 2009. Print.
Zweig, Ellen. “Jackson Mac Low: The Limits of Formalism.” Poetics Today 3.3 (1982): 79–86. Web. 1 Jan. 2013.
A Million Random Digits with 100,000 Normal Deviates. Courtesy of Casey Reas and10 PRINT CHR$(205.5+RND(1));: GOTO 10. Cambridge, Mass.: MIT Press, 2013. 129.
One cannot help but observe the predominance of cupcakes in modern America. Why the cupcake, and why now, at this particular historical moment?
What the fuck is up with all the cupcakes?
Within five minutes of my home there are two bakeries specializing in cupcakes. Two bakeries two hundred yards from each other. They sell cupcakes, and that’s about it. Cupcakes.
Go to a kid’s birthday party and if you survive the bowling or the bouncy castle or the laser tag with the mewling mess of Other People’s Children shouting and screaming, you and your kid will be rewarded with a cupcake. No cake, maybe not even any candles. Cupcakes, that’s it.
Theoretically they come frosted or plain, but plain is such an outright disappointment to everyone, it’s almost embarrassing, so frosted it is. Topped with swirling piles of sugar and fat, the cupcakes come bearing equally saccharine names like Red Velvet Elvis and Cloud 9 and, no shitting you, Blueberry Bikini Buster.
My friends, my very smart friends in academia who study the latest trends in culture and technology, I have a question. You can talk about the spatial turn and the computational turn all you want, but can someone fucking explain the cupcake turn to me?
I have my own theory, and it goes like this: cupcakes match—and attempt to assuage—our cultural anxieties of the moment.
Cupcakes are models of…
AUSTERITY
It’s not a whole cake. It’s a miniature cake. A cake in a fucking cup. A cupcake is a model of modesty. And it’s the best kind of modesty, because it paradoxically suggests extravagance. Cupcakes are rich. And expensive. You could buy two dozen Twinkies for the price of a single caramel apple spice gourmet cupcake.
SERIALITY
By the very nature of their production, cupcakes are made in multiples. A 3×3 tray of 9 cupcakes or 4×4 tray of 16 cupcakes, it doesn’t matter. Cupcakes are serial cakes. Mass produced but conveying a sense of homestyle goodness. Cupcakes are the perfect homeopathic antidote for the industrially-produced food we mostly consume. Fordism never tasted so sickly sweet.
ARTISTRY
On the surface, gourmet cupcakes are artisanal desserts. For all their seriality, cupcakes still contain minute variations in flavor and toppings. Yet underneath, the base model remains the same. Cupcakes embody the postmodern ideal of the manufactured good that has been injected with artificial difference, in order to conjure a sense of individuality. Cupcakes are indie desserts. And like hipsters, cupcakes are pretty much all the same. Cupcake sprinkles and hipster scarves serve the same purpose, turning the plainly ordinary into the veiled ordinary.
HYBRIDITY
Ontologically speaking, just what the hell are cupcakes anyway? A cupcake’s not really a cake. A distant cousin to the muffin, maybe. Is it a pastry for the 21st century United States, a kind of American croissant, full of gooey American exceptionalism? The cupcake itself doesn’t even know what it is. It’s a hybrid form, a Frankencaken. But in a culture frightened by change, blurred borders, and boundary crossings, the cupcake makes all those scary things palatable. As long as it comes in little accordion-pleated paper cup.
Austerity, seriality, artistry, hybridity, that’s what cupcakes are all about. The perfect food for our post-industrial, indie vibe Great Recession. Enjoy them while they last.
Crimson Velveteen photograph courtesy of Flickr user Gina Guillotine / Creative Commons Licensed




















{kind=link}
{kind=link}