I’ve broken up the crazy end-of-the-semester season by sneaking in episodes of The Magicians, the SyFy series based on Lev Grossman’s novels. The premise of the novels and TV adaptation blends Harry Potter, The Chronicles of Narnia, The Paper Chase, and a host of generic 90s shows about good-looking 20-somethings to imagine a grad school for magicians. It took a few episodes for the show to click for me (I can pinpoint the exact moment in the fourth episode of the first season), and now I’m enjoying it immensely. It’s the closest thing to Buffy in tone that I’ve seen in years.
But it’s also a critique of Buffy’s optimism (or was it Joss Whedon’s optimism?). Things in The Magicians keep breaking. Every solution to the show’s major crises spawns further crises. There is never any resolution, a vivid illustration of what philosophers call a “wicked problem”—a problem so complex and intractable that there’s no way to test for solutions or even know when you’ve stumbled upon the least bad solution of the many bad solutions.
“Why can’t anything just be fixed,” wonders Kady in the season 2 finale. And that’s pretty much the overarching theme of The Magicians: nothing can ever just be fixed.
I’ve been thinking lately about one narrative invention in The Magicians magical universe, the idea of the shade. A shade is that part of a person that imbues them with emotions and empathy. In secular terms it’s a bit like a conscience. In religious terms, a soul might be the analog. Shades can be removed—either by force or by choice—and the result is a human who resembles what we might commonly call a sociopath.
The Big Bad in season one of The Magicians removed his shade by choice, rendering him unswayable by pity, untouched by regret, and immune to shame or guilt. In season two Julia is another character who loses her shade. It’s accidental, a metaphysical mishap that occurs during the magical equivalent of an abortion after she’s been brutally raped by a god. Losing her shade makes it impossible for Julia to empathize with others on anything but an intellectual level. Unlike the Big Bad, Julia is a fundamentally good person. She knows she’s supposed to empathize with others, so she tries, without much success, to fake it. Losing her shade also makes it possible for Julia to deal with—ignore is probably a better word—her own post-traumatic stress. She can’t even empathize with herself, in other words.
Julia is about to use her best friend, Quentin, as bait in a trap for the evil god Reynard (The Magicians, “Lesser Evils,” Season 2, Episode 9)
I was struck by how the shadeless Julia recklessly put her friends in harms’ way as she pursues revenge on the god who raped her. She saw her friends as a means to an end and acted on that. Julia’s narrative arc in season two is an uncanny display of objectification, fitting several criteria that the philosopher Martha Nussbaum famously laid out in an 1995 essay. In “Objectification” (Philosophy & Public Affairs, 24.4, pp. 249-291). Nussbaum diagnoses “Seven Ways to Treat a Person as a Thing,” which I’ll quote at length here:
Instrumentality: The objectifier treats the object as a tool of his or her purposes.
Denial of autonomy: The objectifier treats the object as lacking in autonomy and self-determination.
Inertness: The objectifier treats the object as lacking in agency, and perhaps also in activity.
Fungibility: The objectifier treats the object as interchangeable (a) with other objects of the same type, and/or (b) with objects of other types.
Violability: The objectifier treats the object as lacking in boundary integrity, as something that it is permissible to break up, smash, break into.
Ownership: The objectifier treats the object as something that is owned by another, can be bought or sold, etc.
Denial of subjectivity: The objectifier treats the object as something whose experience and feelings (if any) need not be taken into account. (257)
Julia primarily exercises #1, #2, and #7. So, not a total sweep of the objectification criteria, but close to what the gods themselves exercise in The Magicians. (The gods add fungibility, violability, and ownership, at the very least.)
At some point Julia asks her frenemy Kady to act as a kind of external shade, a moral compass to tell Julia when she’s going too far. It’s an interest objectification twist, as Julia instrumentalizes Kady but in a way that acknowledges Kady possesses a subjectivity that surpasses Julia’s own experiences and feelings.
Why does all this matter?
For me at least, it matters because I’ve begun to pay close attention to the way American society—whose economic and cultural might was made by possible by enslaved people who were literally and legally considered objects—I’ve begun to pay close attention to the way American society objectifies others. Objectification—treating people like things that have no autonomy, no interiority, no subjectivity—is happening, at all levels of our government and national discourse, right now.
The Magicians offers a metaphysical explanation for why objectification happens. The objectifier has lost their shade, that “tiny beating heart” at the center of one’s being, as the Big Bad explains to Julia. A shade—or lack thereof—is the fantasy equivalent of what we often see in science fiction, where technology is the reason for someone’s increasing emotional disconnection to others. In Richard K. Morgan’s Altered Carbon (2002), for example, there are some humans who have lived so long through cloning and the digital transfer of their consciousness into new bodies that they become “Meths”—or Methuselahs, centuries-old humans who view mortal humans as their playthings.
Looking to fantasy and science fiction for explanations of objectification might, might, give us some insight for understanding how objectification happens in the real world. I’m not saying Donald Trump lost his shade, but I’m not not saying that.
Seriously, though, fantasy and science fiction can also expand our imaginative possibilities for overcoming objectification. Call it speculative humanization. Returning the humanity of objectified people. Julie turns to her support network to help her. Science fiction offers examples too, like Lauren Olamina’s hyperempathy in Octavia Butler’s The Parable of the Sower (1993). Lauren is born with hyperempathy, a neurological side-effect of her mother’s drug addiction, which causes Lauren to experience the pain (and pleasure) of others. Hyperempathy makes it nearly impossible for Lauren to cause suffering in others, unless she wants to suffer herself.
What other theories of objectification do fantasy and science fiction offer? And what other paths toward reinstating empathy do fantasy and science fiction offer? How do we lose our humanity, how do we regain it, and how do we stop treating people as things? These are the essential questions for our times.
The novelist Colson Whitehead just wrapped up a visit to Davidson College as our 2019 Reynolds speaker. The annual Reynolds Lecture was established in 1959 through a gift from the Z. Smith Reynolds Foundation. Every year this endowed lecture brings a distinguished guest from the humanities, arts, or sciences to campus. Former Reynolds speakers have included Alison Bechdel, Ta-Nehisi Coates, Nicholas Kristof, Maya Angelou, Junot Díaz, Zadie Smith, Gloria Steinem, and many others.
I’m the chair of the Reynolds Lecture Committee this year, which means I had the honor of introducing Colson to a packed house in our main performing arts hall. After Colson’s talk (performance, really), a few people asked me about my introduction. I’m sharing it here, in hope that it does some good in this world beyond the 500 or so people who heard it tonight.
It’s tempting to say that whatever Colson Whitehead’s novels are about, they’re always about something else.
His debut novel The Intuitionist wasn’t really about a divide between two factions of elevator inspectors in an alternate reality New York City. It was about race, about passing, about postmodern blackness.
Likewise, Colson’s 2011 novel Zone One wasn’t about a zombie apocalypse in present-day Manhattan. Not really. It was about identity, the loss of identity, about the monstrous other, and the question of, as the poet Gil Scott-Heron posed it in 1970, the question of who will survive in America.
Colson is here tonight to talk about his latest novel, The Underground Railroad, which won both the Pulitzer Prize for Literature and the National Book Award. Unlike his other novels, The Underground Railroad is resolutely about what it appears to be about. It’s about slavery. The long, brutal legacy of slavery.
In the novel the underground railroad—that death-defying perilous journey out of the slave-owning South—it’s an actual railroad, an actual railroad that runs underground. It seems fantastical and it is, but it lays bare the comforting lies America has told itself about its past. Oh, the underground railroad, you just hop aboard and you’re on your way to freedom. No. The truth, as Colson insists by paradoxically using fiction, the truth was much harder to bear.
Colson’s visit couldn’t come at a better time. In The Underground Railroad each state finds its own way to deal with the problem of slavery, a parody of the patently false notion that the Civil War was about state’s rights. In North Carolina slavery is replaced with a kind of indentured servitude just as dehumanizing as chattel slavery. Meanwhile today in North Carolina the General Assembly wages a war on democratic values with racially based gerrymandering and open attacks on the state judiciary, motivated by a goal that goes all the way back to the end of Reconstruction, which is the goal of disempowering black voters.
Colson’s visit couldn’t come at a better time. Just last week at Davidson signs cropped up all across campus, overnight. The signs read simply, “It’s okay to be white.” If you don’t know, this superficially benign affirmation originated on 4chan, an anonymous Internet message board and the spiritual home of the alt-right. The signs were essentially the materialization of white supremacist Internet trolls into our physical world. Like Colson Whitehead’s novels, the signs say one thing, but they also mean something else.
In times like these, times marked by hate, vulnerability, precariousness, we turn to literature. Cora, the fugitive slave at the heart of The Underground Railroad, faces, as Colson puts it, “travesties so routine and familiar that they were a kind of weather.” Such travesties continue apace today. And Colson Whitehead, by looking to horrors of the past, gives us light for the present. And for that, we are grateful. His visit—his novel—could not come at a better time.
Everyone, please join me in welcoming Colson Whitehead.
In September 2017, a Davidson College alumna alerted the college via a tweet that the Davidson College Alumni Association was advertising on the alt-right website Breitbart.
A September 2017 ad for the Davidson College Alumni Association on Breitbart.com
The display of promotional material for Davidson College next to the ultra conservative and nativist rhetoric of Breitbart was not only a jarring juxtaposition, it was also completely inadvertent, an algorithmic outcome of Facebook’s advertising platform.
Journalists have recently exposed other disturbing elements of Facebook and Google’s ad networks, such as the explosive ProPublica report that advertisers on Facebook could deliberately reach anti-Semitic audiences using targeted keywords and demographic information from Facebook’s vast data mining operations. Buzzfeed similarly showed how racist advertisers could exploit Google’s ad network.
Clearly, online advertising intersects in compelling—but usually hidden—ways with concerns about justice, equality, and community. Justice, equality, and community (JEC)—these are concepts that define a new JEC graduation requirement at Davidson College. To satisfy this requirement, students must take at least one course that addresses “the manifestations of justice and equality in various communities, locales, nations or regions, and focus on methods and theories used to analyze, spotlight, or remedy instances of injustice and inequality.”
In Spring 2018 I am teaching one such JEC-designated course, Gender and Technology (DIG 340). This course counts toward both Digital Studies and Gender and Sexuality Studies major and minor requirements. Thanks to funding from Davidson’s momentous Justice, Equality, and Community grant from the Mellon Foundation, I am developing an assignment for DIG 340 that allows students to explore, critique, and undermine social media ad platforms.
Quite simply, the assignment is to subvert social media advertising by placing justice, equality, and community-oriented materials in timelines and websites whose users would normally not encounter that material. Imagine, for example, a sponsored ad about Colson Whitehead, Davidson’s 2018 Reynolds speaker, appearing on a white supremacist website. Or #metoo promoted posts showing up on the timelines of so-called Men’s Rights activists.
Working in groups of 3-4, students will manage a JEC-focused ad campaign of their own design on either Facebook, Twitter, or Google’s ad platforms. As students explore the contours, possibilities, and limits of social media advertising, each group will manage a series of campaigns with progressively larger budgets as they fine-tune their message and promotional strategy. Groups will have a budget of only $5 for their first campaigns. But as their campaigns grow more sophisticated, budgets will increase. Groups will have $100 for their final campaigns. All the while students will critically examine the advertising apparatuses themselves, analyzing overt and implicit ideological assumptions built into the platforms. Students will be aided in this process by Sara Wachter-Boettcher’s important new book, Technically Wrong: Sexist Apps, Biased Algorithms, and Other Threats of Toxic Tech (2017).
Our implementation of the assignment is a few months away, and I am eager to hear your ideas about it. Thoughts, comments, suggestions?
[This is a duplicate post of an assignment for my Introduction to Digital Studies class at Davidson. My course site was temporarily down, so I made a back-up copy of the assignment here!]
The phrase cultural analytics generally refers to analyzing vast amounts of image, text, or other media through computational methods. Think of it as data science aimed towards arts and culture. But unlike data science, cultural analytics isn’t necessarily asking political-social-economic questions. Rather, cultural analytics seeks to help us see the world in a new way, generating more questions than answers.
In this lab we’ll attempt a special kind of cultural analytics. Instead of looking at a vast number of texts (say, the way Ben Schmidt analyzes State of the Union addresses, or how Lev Manovich analyzes Instagram selfies), we’ll break apart a single text—a film—into a vast number of discrete parts, and analyze those parts in the aggregate. Some researchers call this technique “image summation.”
Procedure
Elements of this procedure have been adapted from Dr. Brian Croxall’s similar exercise at Brigham Young University. Thanks, Brian! We’ll also be using an online image analysis tool developed by Dr. Zach Whalen at the University of Mary Washington. Thanks, Zach!
Extracting Stills
First, you’ll need to extract still images from the film that you’ve ripped or otherwise acquired.
Extract frames from your movie at the rate of one frame for every two seconds. You can do this most easily with the free VLC Media Player. Once you have downloaded VLC, you will need to make a few changes to its settings to get the images out. Set up these preferences before you open your movie in VLC.
Go to preferences.
Click “show all”
Click on “video”
Click on “filters”
Find “scene video filter” and tick that box
Scroll down under “filters” to find “scene video filter.” Select it to edit its preferences.
Paste in a directory path for where you want the screenshots to be collected.
Set the “recording ratio” to be how often you want a still to be grabbed. For our purposes, you should set this to “60,” which will provide one frame for every two seconds.
Click save.
Open a movie file in VLC and let it play.
Watch the screenshots roll in. (Check to make sure that they’re appearing.)
This method extracts frames in real time, which means it will take several hours (as long as the film) to extract all the images. Obviously, we don’t have enough time in class to complete this process. You’ll work on your own film outside of class. For the purposes of class, I’ve extracted frames from three different works: “The Entire History of You” from Black Mirror, The Fast and the Furious, and the first episode of Game of Thrones. You can select one of these three videos to use during class.
Analysis
For analysis of our images, we’re going to use Imj, a web-based image analysis tool. As the tool’s creator, Zach Whalen says, this technique isn’t all that powerful compared to other desktop-based tools, but it does “enable some low-level visualizations that might help researchers or students determine whether an investigation with more robust tools is warranted.”
In particular, Imj supports three types of visualizations: barcodes, montages, and scatterplots. Basically, you upload your folder of extracted frames (up to 9999 frames), and let Imj do the work.
Use Imj! Subject your movie to all three visualization types. For details on how each visualization works, read Zach Whalen’s guide to Imj.
Lab Report
For the purposes of writing your lab report, you’ll use Imj on a film of your own. Follow the instructions above for using VLC to extract frames. Then subject your video to all three visualization types. Download the results (the barcode, montage, and plot) in order to include these images in your lab report.
In a 300-500 word lab report, reflect on some of the following questions:
What does each resulting image type tell us about the film?
What elements of the video stand out through these visualizations? What elements disappear?
If you compare the resulting image summations with each other, which one is most useful? Define what you mean by useful.
What did you learn from these visualizations that you couldn’t have learned by watching the film alone?
Many times the power of these image summations comes not from the analysis of an individual film, but from a more longitudinal of multiple videos. For instance, Dr. Kevin Ferguson has analyzed every Disney animated film with these techniques. Or imagine comparing every episode of a television series to see if the series’ visual signature changes over time. Or comparing barcodes of 30 years of horror movies. What kind of comparative analysis would you like to do if you had the time and resources? What would you hope to learn through such a comparative analysis?
Share the report with masample@davidson.edu as a Google Doc by end of the day, Monday, November 20. (Remember there is no class on Monday, November 20).
A few weeks ago I wrote about studying digital culture through the lens of specific file types. In the fall I’m teaching DIG 101 (Introduction to Digital Studies)—an amorphous course that is part new media studies, part digital humanities, part science and technology studies. I was imagining spending a week on, say, something like GIFs as way to understand Internet culture. My question is, what other file types could be similarly productive to explore?
That short post generated great ideas in the comments, on Facebook, and on Twitter. To make things easier to find again (for me and others), here are just some of the file type ideas that bubbled to the surface:
PDF
As commentator Sam Popowich put it, “love it or hate it” PDFs are everywhere. Ryan Cordell pointed out that Lisa Gitelman has a chapter devoted to PDFs in Paper Knowledge. Gitelman is exactly the kind of scholar I want undergraduates to read. Clear, perceptive, uncovering seemingly archaic history and showing why it matters.
WAD
Quite a few people suggested WADs, composite files made up sounds, sprites, graphics, level information, and other digital assets for PC games. Doom popularized WADs, but PC games continue to use similar composite files. You can use tools like GCFScape to unpack these files, and they lend themselves to digital forensic lab work in the classroom. Every time I teach Gone Home, for example, students explore unpacked sound and graphic files. It’s an alternative way of experiencing the game. My own research digging to WADS to find misogynistic game developer comments could come into play here too.
JPG
At first I thought studying JPGs would be redundant if GIFs are already on the table. Allison Parrish and Jeff Thompson make a strong case for JPGs though: they organize information differently, compress differently, and of course, are glitchable. Like PDFs, their very ubiquity renders them invisible as file types, especially to students who have grown up carrying a camera with them at all times.
EXIF
Vika Zafrin and Tim Owens recommended EXIF, one of the few file types I hadn’t already considered as a possibility. Technically I guess EXIF is a metadata standard, not a file type per se, but the relationship between metadata and data is crucial to understand, and EXIF can get us there. Plus, we can talk about privacy, tracking, and my colleague Owen Mundy’s fantastic I Know Where Your Cat Lives project.
Stigmatized File Types
@TopLeftBrick mentioned NFO files and Finn Arne Jørgensen brought up .torrent files, both of which belong to the world of pirated games, software, and media. Jason Mittell similarly suggested another what I call stigmatized file type:
.FLV , a hidden file type that allows you to study YouTube.
Before the rise of HTML5, YouTube videos were Flash files (FLV = Flash Video), and there were (and are) tricks to downloading these videos to watch offline. But it was a format you weren’t supposed to encounter; YouTube strove to make streaming seamless, hiding the actual video file. I would love to spend some time in DIG 101 studying all of these stigmatized file types, not so much to understand the technical features of the file formats themselves, but to better understand the cultural rules that influence the circulation of knowledge.
The Big Picture
The above list is certainly incomplete. And leaves off the file types that originally inspired this idea (MP3s, GIFs, HTML, and JSON). But it’s a great start. It’s also important to zoom out and see the big picture. To this end, Amelia Acker pointed me toward this surprisingly philosophical technical report from Microsoft Research: “What is a File?”
Indeed, what is a file and what do they mean is something we’ll be asking in DIG 101.
I am revamping “Introduction to Digital Studies,” my program’s overview of digital culture, creativity, and methodology. One approach is to partially organize the class around file types, the idea being that a close reading of certain file types can help us better understand contemporary culture, both online and off.
It’s a bit like Raymond William’s Keywords, except with file types. A few of the file types that seem especially generative to consider:
MP3 (Jonathan Sterne’s work on MP3s is the gold standard to follow)
GIF (especially the rise and fall and rise of the animated GIF)
HTML (a gateway to understanding the early history and ethos of the web)
JSON (as a way to talk about data and APIs)
This list is just an initial start, of course. What other culturally significant file types would you have students consider? And what undergrad-friendly readings about those file types would you recommend?
Are you sick of parallax scrolling yet? You know, the way the foreground and background on a web page, iPhone screen, or Super Mario Brothers move at different speeds, giving the illusion of depth? Parallax scrolling is a gimmick. Take it away and not much changes. Your videogame might be a tad less immersive, but come on, how immersive was it in the first place? Turn off parallax scrolling on your phone and your battery life might actually improve. Parallax scrolling is ornamental, a hallmark of what will eventually be known as the Baroque Digital Age.
So it’s with hesitation that I’m attempting to recuperate the word parallax here. In my defense I’m using the word metaphorically, to describe a certain kind of hermeneutical approach to textual material.
Here it is: parallax reading, an interpretive maneuver that keeps both close and distant reading in focus at the same time.
If you’re just tuning in to the digital humanities, there’s a pretty much bogus IMHO tension between close and distant reading. Close reading is that thing we were all taught to do in high school English, paying attention to individual words and the subtle nuances of a text. Distant reading zooms out to look at a text—or even better, a massive body of texts—from a distance. In Franco Moretti’s memorable words, distance is “not an obstacle, but a specific form of knowledge: fewer elements, hence a sharper sense of their overall interconnection. Shapes, relations, structures. Patterns.”1
Cool, patterns.
“Parallax reading” is a fancy way of saying why not combine close and distant reading. And to be clear, no one is saying you can’t. Again, it’s a bogus tension, a straw man. I’m not proposing anything new here. I’m just giving it a name. And in a bit, a demo.
A parallax reading is the opposite of the “lenticular logic” that, as Tara McPherson explains, separates the two images on a 3D postcard, making it impossible to see them simultaneously. Whereas lenticular vision flips between two distinct representations, parallax reading holds multiple distances in view at once. Like its visual counterpart, parallax reading conveys a sense of depth. Unlike parallax scrolling, though, this is depth that actually matters, a depth that complicates our understanding of texts.
What would a parallax reading look like?
As a case study let’s look at Theodore Roethke’s poem “My Papa’s Waltz.” Written from the perspective of a young boy, the sixteen line poem captures a possibly tender, possibly terrifying moment, as his boozy father mock waltzes him “off to bed.” The whiskey on his father’s breath makes the boy “dizzy.” His mother looks on, barely tolerating the nonsense. The boy is so small he only comes up to his father’s waist; his dad’s belt buckle scrapes his ear with “every step.” As the boy goes to bed “still clinging” to his father’s shirt it’s not clear whether he’s clinging out of fear or love, or maybe both.
“My Papa’s Waltz” was published in 1942 and by the mid-50s was already widely anthologized. It’s a great poem, and I love teaching it. And so do other people. There’s a lot going on under its deceptively simple surface. In The Literature Workshop (a book every teacher of literature should study), Sheridan Blau uses “My Papa’s Waltz” to confront two questions that often arise in literature classes: where does meaning come from, and how the hell do we know which meaning is the right one?
Blau observes that for twenty years or so he taught “My Papa’s Waltz” and students overwhelmingly read it as nostalgic, the fond recollection of a grown man of his gruff but loving father. Then, sometime in mid-80s, Blau’s students began to read the poem more darkly, a vivid childhood memory about abuse and a dysfunctional family.
What happened? How can the poem mean both things? At this point you might be thinking, ah, so a parallax reading is simply holding two opposing meanings of the poem in place at the same time. This is what sophisticated readers and writers do all the time. For example, Sherman Alexie describes “My Papa’s Waltz” as
incredibly sad and violent, and its sadness and violence is underscored by its gentle rhymes and rhythms. It’s Mother Goose on acid, maybe. I think that its gentle music is a form of denial about the terror contained in the poem, or maybe it’s the way kids think, huh?
A love poem about, as Alexie says later on, “the unpredictability of the alcoholic father.” Two seemingly incompatible interpretations—incompatible, that is, to a naive reader. Is this what I mean by parallax reading? Are two competing perspectives we keep in simultaneous focus what parallax reading is all about?
No!
Embracing ambivalent or contradictory interpretations is nothing new. Hopefully, literary scholars practice this—and teach it—all the time. (If anything, we celebrate ambiguity a little too much, when what the world needs now is some rock solid truth, right?) Anyway, a parallax reading is not about the interpretative outcomes, it’s about the methodological process. It’s about simultaneously negotiating close and distant readings.
Think about “My Papa’s Waltz” from a close reading perspective (the foreground of the parallax). An array of historical evidence might suggest which interpretation of his poem Roethke himself preferred. For example, we could look at drafts of the poem, which indicate several significant revisions. In one draft, the small boy is a girl and the “right ear” scraping a buckle is the less particular “forehead.”
Roethke’s draft of “My Papa’s Waltz.” Courtesy of the Theodore Roethke Manuscripts Collection at the University of Washington in Seattle
Changing the gender of the speaker recasts the the father-son relationship as a father-daughter relationship. We might be less likely to read biographical details of Roethke’s own life into the poem: his father ran a gigantic greenhouse, worked with his hands, and died of cancer when Roethke was 14-years-old. Would any of that matter if the speaker is a girl? Would any of it matter either way?
We could also listen to Roethke’s own delivery of the poem. At least two recordings are available online. One features Roethke reading in a sing-song voice that bears no trace of fear or resentment. Another Roethke reading is somber, the accent on the words “you” in the third stanza and “beat” in the fourth stanza possibly ominous, possibly not.
Or—and this is novel—we could actually read the poem. Here’s what I did last time I taught “My Papa’s Waltz.” (I wasn’t teaching Roethke’s poem per se, I was teaching Blau’s book, in a grad class on the pedagogy of teaching literature.) I’m a fan of reading aloud in class, and that’s what we did. As we read, I asked students to point—literally, point with their index finger—to the words that were most freighted with abuse. “Scraped” and “beat” drew some attention from the students, but invariably the word with the strongest connotation of abuse for the students was “battered.” Roethke uses “battered” to describe the father’s hand—it was “battered on one knuckle”—but students couldn’t help displacing the word onto the small boy himself. It’s as if by metonymical extension the boy too was battered and bruised.
With “battered” coming into focus during our close reading as a key marker of abuse, let’s shift to a distant reading of “My Papa’s Waltz”—the background of the parallax. But how can we zoom out from a single poem? From a distance, what’s there to look at? If one poem is a drop of water, what’s the ocean of words that contains it?
One possible ocean is Google Books. Google ngrams offers a snazzy interface for tracking word frequency over time, based on Google Books’ dataset, a staggering 155 billion words in American English. Since my students found “battered” to be the center of traumatic gravity of “My Papa’s Waltz” I plugged that word into Google ngrams:
Which is honestly not that useful. Ngrams can show the rise and fall of certain terms, but they’re inadequate for more nuanced inquires. There are at least three reasons the Google ngram viewer fails here: (1) Google ngrams limits searches by collocates, that is, immediately preceding and succeeding words; (2) Google ngrams can’t search for parts of speech; and most significantly (3) Google ngrams provides no context for the words—no sentence context, no source context, nothing.
This is where the Corpus of Historical American English (COHA) comes in. COHA is a dataset of 400 million words from 1810 through 2009. Established by Mark Davies at Brigham Young University, COHA includes fiction (including texts from Project Gutenberg, scanned books, and scanned movie scripts) and nonfiction (including scanned newspapers and magazines). COHA is a smaller dataset than Google Books, but it holds several critical advantages over Google Books. You can search for phrases that aren’t necessarily collocated right next to each other. You can specify what part of speech you want to search for. That’s really important if you’re looking for a word like, oh, I don’t know, “trump,” which can be a verb, noun, proper noun, and a few other things. Finally, COHA provides context for its searches.
For the time period of the 1950s, when “My Papa’s Waltz” had already been widely anthologized, COHA includes nearly 12 million words from fiction sources, 5.7 millions words from popular magazines, 3.5 million words from newspapers, and just over 3 million words from nonfiction books. That’s a total of 24 million words from the 1950s, which gives us a representative view of how language was being used across a number of domains at the time. This is the ocean of words that surrounds “My Papa’s Waltz.”
Let’s check out “battered” in COHA, to see how the word was being used during Roethke’s time and afterward.
Here are our search parameters, which tell COHA to find any occurrence of “battered” followed within five words by a noun (that’s the [nn*] in the Collocates box). This search acknowledges that the frequency of “battered” isn’t as important as its context.
Search Window for COHA
The results are immediately striking. We have the kind of patterns Moretti seeks in distant reading.
“battered” with nn* 0/5
The second most common noun following “battered” is women, as in “battered women.” This frequency would appear to support the idea that “battered” in “My Papa’s Waltz” is an indicator of abuse. At the very least, its appearance is ominous.
Yet dig deeper and notice that the variants of “battered…women” do not become prevalent until 1980 (with 16 occurrences) and peak in the 1990s with 46 occurrences. Prior to 1970, “battered” is rarely used in the context of physical abuse against women.
So what does “battered” typically describe when Roethke published the poem in 1942 and in the years immediately afterward? In the 1940s the most common collocate was “hat”: “a battered black stovepipe hat,” “a battered greasy hat,” “his battered hat,” “a disreputable, battered hat”—all uses that suggest a knocked-about, down-on-one’s-luck man. Here’s the KWIC (Keyword In Context) display for “battered…hat” in the 1950s:
“battered…hat” Keyword in Context
And look at the third most common noun associated with “battered.” It’s “face,” peaking in the 1950s. This detail might appear to support the negative interpretation of “My Papa’s Waltz.” But again, look at the keyword in context.
“battered…face” in the 1950s KWIC
The battered face here is predominantly a male face, battered by wind, hard living, and frequently, war. This is likely the kind of “battered” Roethke had in mind when he described the rough hands of the boy’s father in the poem.
Contrast this with how battered appears in the 1990s, when it is associated most frequently with “women”:
“battered…women” in the 1990s Keyword in Context
Here we find “battered” being used the way today’s students would understand the word, associated with the physical abuse of women by men. (Grammar fun: “battered” is technically a participial adjective. It’s an adjective that started out as a participial phrase, but was shortened. Like “there were no shelters for battered women in Michigan” (the first example from the KWIC above) really means “there were no shelters for women who were battered by men in Michigan.” The agent—the men inflicting the battering—drops out of the sentence and we’re left with inexplicably battered women, and no party to take responsibility. Basically it’s passive voice in disguise, a way for abusive men to get off scott-free, linguistically speaking.)
So, a theory: “battered” is what I would call a cusp word—a word teetering on the cusp between two opposing meanings. On one side, the word suggests strength and resilience. It’s gendered masculine in this context. On the other side it suggests helplessness and victimization. It’s gendered female in this case. In other words, once associated with men at the mercy of the elements or men who have endured hardship, “battered” is now associated with women who have suffered—though this part is kept hidden by the participial adjective—at the hands of men.
We still occasionally encounter the older meaning of the word. A line from Leonard Cohen’s “Democracy” (1992) comes to mind:
From the brave, the bold, the battered heart of Chevrolet Democracy is coming to the USA
Here “the battered heart of Chevrolet” is a stand-in for Rust Belt America, the industrial wasteland that left blue collar working men out of work. Or “stiffed,” as Susan Faludi put it in her eponymous diagnosis of 20th century masculinity.2 I’m no sociologist, but it’s not difficult to imagine that “the battered heart of Chevrolet” contributed to a sense of helplessness in men that found expression in violence against women. Emasculated men beating their way to empowerment. Thus battered souls lead to battered bodies.
We can’t know for certain, of course, but it makes sense that Roethke’s description of the father’s hands as “battered” is a kind of tribute to the man. An acknowledgment of hard work and sacrifice. Roethke’s vocabulary was shaped by the Great Depression and World Wars, an era of stoic endurance (even if that stoicism was a myth). People reading the poem today, however, see in “battered” the ugly side of human nature. Desperation, rage, brutality.
In his explanation of his students’ changing interpretation of “My Papa’s Waltz”: Blau suggests that “a change in the culture made a particular reading available that had not been culturally available before.”3 Blau’s exactly right. That shift in meaning began in the 1980s, concomitant with growing social awareness of domestic abuse. What Blau doesn’t say—because the tools weren’t culturally available to him at the time—is that thanks to a distant reading, we can find evidence of that shift within a single word of Roethke’s poem.
What’s important for a parallax reading is that neither foreground nor background disappear entirely. In fact, they only make sense when considered together. That’s where the sense of depth comes from. Armed with knowledge gleaned from distant reading we can go back to the poem and read it again. And maybe, recursively, find other words to track across time, or to contextualize historically. But we always return to the poem.
Will a parallax reading definitively answer the question, what’s “My Papa’s Waltz” about? No. The beauty of literature and language more generally is its ambiguity (argh, though again, maybe we tolerate a little too much ambiguity). But, I have discovered evidence that complicates our interpretation of the poem. At the very least, it should shock us out of our presentist approach to language, assuming the way we use words is the way those words have always been used. And even more importantly, it’s not that I have found answers about the poem. It’s that I found a new way to ask questions.
Notes
Moretti, Franco. “Graphs, Maps, Trees 2: Abstract Models for Literary History.” New Left Review, vol. 26, no. March-April, 2004, p. 94.↩
Faludi, Susan. Stiffed: The Betrayal of the American Man. Harper Perennial, 1999.↩
Blau, Sheridan. The Literature Workshop: Teaching Texts and Their Readers. Heinemann, 2003, p. 73.↩
Digging through some old files I came across notes from a roundtable discussion I contributed to in 2009. The occasion was an “Unthinking Television” symposium held at my then-institution, George Mason University. If I remember correctly, the symposium was organized by Mason’s Cultural Studies and Art and Visual Technology programs. Amazingly, the site for the symposium is still around.
The roundtable was called “Screen Life”—all about the changing nature of screens in our lives. I’m sharing my old notes here, if for nothing else than the historical perspective they provide. What was I, as a new media scholar, thinking about screens in 2009, which was like two epochs ago in Internet time? YouTube was less than five years old. The iPhone was two years old. Avatar was the year’s highest grossing film. Maybe that was even three epochs ago.
Do my “four trends” still hold up? What would you add to this list, or take away? And how embarrassing are my dated references?
Four Trends of Screen Life
Coming from a literary studies perspective, I suppose everyone expects me to talk about the way screens are changing the stories we tell or the way we imagine ourselves. But I’m actually more interested in what we might call the infrastructure of screens. I see four trends with our screens:
(1) A proliferation of screens
I can watch episodes of “The Office” on my PDA, my cell phone, my mp3 player, my laptop, and even on occasion, my television.
(2) Bigger is better and so is smaller
We encounter a much greater range in screen sizes on a daily basis. My new high definition videocamera has a 2” screen and I can hook that up directly via HDMI cable to my 36” flat screen, and there are screen sizes everywhere in between and beyond.
(3) Screens aren’t just to look at
We now touch our screens. Tactile response is just as important as video resolution.
(4) Our screens now look at us
Distribution networks like Tivo and Dish and Comcast have long had unobtrusive ways to track what we’re watching, or at least what our televisions were tuned to. But now screens can actually look at us. I’m referring to screens that aware of us, of our movements. The most obvious is the Wii and its use IR emitters in its sensor bar to triangulate the position of the Wiimote, and hence, the player. GE’s website has been showcasing an interactive “hologram” that uses a webcam. In both cases, the screen sees us. This is potentially the biggest shift in what it means to have a “screen life.” In both this case and my previous trend concerning the new haptic nature of screens, we are completing a circuit that runs between human and machine, machine and human.
In anticipation of the upcoming Modern Language Association annual convention, here’s a crowdsourced list of digital humanities sessions at the conference: MLA 2016 Digital Humanities Sessions.
In 1965 the singer-songwriter Phil Ochs told an audience that “a protest song is a song that’s so specific you can’t mistake it for bullshit.” Ochs was introducing his anti-war anthem “I Ain’t Marching Anymore”—but also taking a jab at his occasional rival Bob Dylan, whose expressionistic lyrics by this time resembled Rimbaud more than Guthrie. The problem with Dylan, as far as Ochs was concerned, wasn’t that he had gone electric. It was that he wasn’t specific. You never really knew what the hell he was singing about. Meanwhile Ochs’ debut album in 1964 was an enthusiastic dash through fourteen very specific songs. The worst submarine disaster in U.S. history. The Cuban Missile Crisis. The murder of Emmett Till, the assassination of Medgar Evers. The sparsely produced album was called All the News That’s Fit to Sing, a play on the New York Times slogan “All the News That’s Fit to Print.” But more than mere parody, the title signals Ochs’ intention to best the newspaper at its own game, pronouncing and denouncing, clarifying and explaining, demanding and indicting the events of the day.
Ochs and the sixties protest movement are far removed from today’s world. There’s the sheer passage of time, of course. But there’s also been a half century of profound social and technological change, the greatest being the rise of computational culture. Networks, databases, videogames, social media. What, in this landscape, is the 21st century equivalent of a protest song? What is the modern version of a song so specific in its details, its condemnation, its anger, that it could not possibly be mistaken for bullshit?
One answer is the protest bot. A computer program that reveals the injustice and inequality of the world and imagines alternatives. A computer program that says who’s to praise and who’s to blame. A computer program that questions how, when, who and why. A computer program whose indictments are so specific you can’t mistake them for bullshit. A computer program that does all this automatically.
Bots are small automated programs that index websites, edit Wikipedia entries, spam users, scrape data from pages, launch denial of service attacks, and other assorted activities, both mundane and nefarious. On Twitter bots are mostly spam, but occasionally, they’re creative endeavors.
The bots in this small creative tribe that get the most attention—the @Horse_ebooks of the world (though @horse_ebooks would of course turn out later not to be a bot)—are surreal, absurd, purposeless for the sake of purposelessness. There is a bot canon forming, and it includes bots like @tofu_product, @TwoHeadlines, @everycolorbot, and @PowerVocabTweet. This emerging bot canon reminds me of the literary canon, because it values a certain kind of bot that generates a certain kind of tweet.
To build on this analogy to literature, I think of Repression and Recovery, Cary Nelson’s 1989 effort to reclaim a strain of American poetry excluded from traditional literary histories of the 20th century. The crux of Nelson’s argument is that there were dozens of progressive writers in the early to mid-20th century whose poems provided inconvenient counter-examples to what was considered “poetic” by mainstream culture. These poems have been left out of the canon because they were not “literary” enough. Nelson accuses literary critics of privileging poems that display ambivalence, inner anguish, and political indecision over ones that are openly polemical. Poems that draw clear distinctions between right and wrong, good and bad, justice and injustice are considered naïve by the academic establishment and deemed not worthy of analysis or teaching, and certainly not worthy of canonization. It’s Dylan over Ochs all over again.
A similar generalization might be made about what is valued in bots. But rather than ambivalence and anguish being the key markers of canon-worthy bots, it’s absurdism, comical juxtaposition, and an exhaustive sensibility (the idea that while a human cannot tweet every word or every unicode character, a machine can). Bots that don’t share these traits—say, a bot that tweets the names of toxic chemicals found in contaminated drinking water or tweets civilian deaths from drone attacks—are likely to be left out of the bot canon.
I don’t care much about the canon, except as a means to clue us in to what stands outside the canon. We should create and pay attention to bots that don’t fit the canon. And protest bots should be among these bots. We need bots that are not (or not merely) funny, random, or comprehensive. We need bots that are the algorithmic equivalent of the Wobblies’ Little Red Songbook, bots that fan the flames of discontent. We need bots of conviction.
Bots of Conviction
In his classic account of the public sphere, that realm of social life in which individuals discuss and shape public opinion, the German sociologist Jürgen Habermas describes a brief historical moment in the early 19th century in which the “journalism of conviction” thrived. The journalism of conviction did not simply compile notices as earlier newspapers had done; nor did the journalism of conviction seek to succeed purely commercially, serving the private interests of its owners or shareholders. Rather, the journalism of conviction was polemical, political, fervently debating the needs of society and the role of the state.
We may have lost the journalism of conviction, but it’s not too late to cultivate bots of conviction. I want to sketch out five characteristics of bots of conviction. I’ll name them here and describe each in more details. Bots of conviction are topical, data-based, cumulative, oppositional, and uncanny.
Topical. Asked where the ideas for his song came from, Ochs once pulled out a Newsweek and smiled, “From out of here.” Though probably apocryphal, the anecdote highlights the topical nature of protest songs, and by extension, protest bots. They are not about lost love or existential anguish. They are about the morning news—and the daily horrors that fail to make it into the news.
Data-based. Bots of conviction are based in data, which is another way of saying they don’t make this shit up. They draw from research, statistics, spreadsheets, databases. Bots have no subconscious, so any imagery they use should be taken literally. Protest bots give witness to the world we inhabit.
Cumulative. It is the nature of bots to do the same thing over and over again, with only slight variation. Repetition with a difference. Any single iteration may be interesting, but it is in the aggregate that a protest bot’s tweets attain power. The repetition builds on itself, the bot relentlessly riffing on its theme, unyielding and overwhelming, a pile-up of wreckage on our screens.
Oppositional. This is where the conviction comes in. Whereas the bot pantheon is populated by l’bot pour l’bot, protest bots take a stand. Society being what it is, this stance will likely be unpopular, perhaps even unnerving. Just as the most affecting protest songs made their audiences feel uncomfortable, bots of conviction challenge us to consider our own complicity in the wrongs of the world.
Uncanny. I’m using uncanny in the Freudian sense here, but without the psychodrama. The uncanny is the return of the repressed. The appearance of that which we had sought to keep hidden. I have to thank Zach Whalen for highlighting this last characteristic, which he frames in terms of visibility. Protests bots often reveal something that was hidden; or conversely, they might purposefully obscure something that had been in plain sight.
It’s one thing to talk about bots of conviction in theory. It’s quite another to talk about them in practice. What does a bot of conviction actually look like?
Consider master botmaker Darius Kazemi’s @TwoHeadlines. On one hand, the bot is most assuredly topical, as it functions by yoking two distinct news headlines into a single, usually comical headline. The bot is obviously data-driven too; the bot scrapes the headline data directly from Google News. On the other hand, @TwoHeadlines is neither cumulative nor oppositional. The bot posts at a moderate pace of once per hour, but while the individual tweets accumulate they do not build up to something. There is no theme the algorithm compulsively revisits. Each tweet is a one-off one-liner. Most critically, though, the bot takes no stance. @TwoHeadlines reflects the news, but it does not reflect on the news. It may very well be Darius’ best bot, but it lacks all conviction.
What about another recent bot, Chuck Rybak’s @TheHigherDead? [Update: @TheHigherDead account has disappeared.] Chuck lampoons utopian ed-tech talk in higher education, putting jargon such as “disrupt” and “innovate” in the mouths of zombies. Chuck uses the affordances of the Twitter bio to sneak in a link to the Clayton Christensen Institute. Christensen is the Harvard Business School professor who popularized terms like “disruptive innovation” and “hybrid innovation”—ideas that when applied to K12 or higher ed appear to be little more than neo-liberal efforts to pare down labor costs and disempower faculty. When these ideas are actually put into action, we get the current crisis in the University of Wisconsin system, where Chuck teaches. @TheHigherDead is oppositional and uncanny, in the way that anything having to do with zombies is uncanny. It’s even topical, but is it a protest bot? It’s parody, but its data is too eclectic to be considered data-based. If @TheHigherDead mined actual news accounts and ed-tech blogs for more jargon and these phrases showed up in the tweets, the bot would rise beyond parody to protest.
@TwoHeadlines and @TheHigherDead are not protest bots, but then, they’re not supposed to be. I am unfairly applying my own criteria to it, but only to illustrate what I mean by the terms topical, data-based, cumulative, oppositional, and uncanny. It’s worth testing this criteria against another bot: Zach Whalen’s @ClearCongress. This bot retweets members of Congress after redacting a portion of the original tweet. The length of the redaction corresponds to the current congressional approval rate; the lower the approval rating, the more characters are blocked.
MT █ SENJOHNTHUNE: ▓▓▓▓▒ ▒▓▓▓▓▓▓▒ ▓▓▒▓ ▓▓▓▓ ▓▓▓▓▓CKET WITH NEW ▒▓▓▓▓▒ ▓▓▓▓▓▒▓▓▓▒▓ @▒▓▒▓▓▒▒ ▓▒▓▓▓▓▒▓▓▓▓▓▓▒▒▓▒▓▓▓▓▒
Assuming our senators and representatives post about current news and policies, the bot is topical. It is also data-driven, doubly-so, since it pulls from congressional accounts and up-to-date polling data from the Huffington Post. The bot is cumulative as well. Scrolling through the timeline you face an indecipherable wall of ▒▒▒▒ and ▓▓▓▓, a visual effect intensified by Twitter’s infinite scrolling. By obscuring text, the bot plays in the register of the visible and invisible—the uncanny. And despite not saying anything legible, @ClearCongress has something to say. It’s an oppositional bot, thematizing the disconnect between the will of the people and the rulers of the land. At the same time, the bot suggests that Congress has replaced substance with white noise, that all senators and representatives end up sounding the same, regardless of their politics, and that, most damning of all, Congress is ineffectual, all but useless.
Another illustrative protest bot likewise uses Congress as its target. Ed Summers’ @congressedits tweets whenever anonymous edits are made to Wikipedia from IP addresses associated with the U.S. Congress. [Update: Ed has removed @congressedits from Twitter, but the bot now posts intermittently on Mastodon.] In other words, whenever anyone in Congress—likely Congressional staffers, but conceivably representatives and senators themselves—attempts to edit a Wikipedia article anonymously, the bot flags that edit and calls attention to it. This is the uncanny hallmark of @congressedits: making visible that which others seek to hide, bringing transparency to a key source of information online, and in the process highlighting the subjective nature of knowledge production in online spaces. @congressedits operates in near real-time; these are not historical revisions to Wikipedia, they are edits that are happening right now. The bot is obviously data-driven too. Summers’ bot responds to data from Wikipedia’s API, but it also send us, the readers, directly to the diff page of that edit, where we can clearly see the specific changes made to the page. It turns out that many of the revisions are copyedits—fixing punctuation, spelling, or grammar. This revelation undercuts our initial cynical assumption that every anonymous Wikipedia edit from Congress is ideologically-driven. Yet it also supports the message of @ClearCongress. Congress is so useless that they have nothing better to do than fix comma splices on Wikipedia? Finally, there’s one more layer of @congressedits to mention, which speaks again to the issue of transparency. Summers has shared the code on Github, making it possible for others to programmatically develop customized clones, and there are dozens of such bots now, tracking changes to Wikipedia.
There are not many bots of conviction, but they are possible, as @ClearCongress and @congress-edits demonstrate. I’ve attempted to make several agit-bots myself, though when I started, I hadn’t thought through the five characteristics I describe above. In a very real sense, my theory about bots as a form of civic engagement grew out of my own creative practice.
I made my first protest bot in the wake of the Snowden revelations about PRISM, the NSA’s downstream surveillance program. I created @NSA_PRISMbot. The bot is an experiment in speculative surveillance, imagining the kind of useless information the NSA might distill from its invasive data-gathering:
@NSA_PRISMbot is topical, of course, rooted in specificity. The Internet companies the bot names are the same services identified on the infamous NSA PowerPoint slide. When Microsoft later changed the name of SkyDrive to OneDrive, the bot even reflected that change. Similarly, @NSA_PRISMbot will occasionally flag (fake) social media activity using the list of keywords and search terms the Department of Homeland Security tracks on social media.
Any single tweet of NSA_PRISMbot may be clever, with humorous juxtapositions at work. But the real power of the bot is the way the individual invasions of privacy accumulate. The bot is like a devotional exercise, in which repetition is an attempt at deeper understanding.
I followed up @NSA_PRISMbot with @NSA_AllStars, whose satirical profile notes that it “honors the heroes behind @NSA_PRISMbot, who keep us safe from the bad guys.” This bot builds on the revelations that NSA workers and subcontractors had spied on their own friends and family.
The code of @nsa_allstars
The bot names names, including the various divisions of the NSA and the companies that are documented subcontractors for the NSA.
A Bot Canon of Anger
While motivated by conviction, neither of these NSA bots are explicit in their outrage. So here’s an angry protest bot, one I made out of raw emotion, a bitter compound of fury and despair. On May 23, 2014, Elliot Rodger killed six people and injured fourteen more near the campus of UC-Santa Barbara. In addition to my own anger I was moved by the grief of my friends, several of whom teach at UC Santa Barbara. It was Alan Liu’s heartfelt act of public bereavement that most clearly articulated what I sought in this protest bot:
What is the literary canon of anger that must back up that of consolation to give full-throated voice to #NotOneMore? →
Whereas Alan turns toward literature for a full-throated cry of anger, I turned toward algorithmic culture, to the margins of the computational world. I created a bot of consolation and conviction that—to paraphrase Phil Ochs in “When I’m Gone”—tweets louder than the guns.
The bot I made is @NRA_Tally. It posts imagined headlines about mass shootings, followed by a fictionalized but believable response from the NRA:
@NRA_Tally
The bot is topical, grievously so. More critically, you cannot mistake it for bullshit. The bot is data-driven, populated with statistics from a database of over thirty years of mass shootings in the U.S. Here are the individual elements that make up the template of every @NRA_Tally tweet:
A number. The bot selects a random number between 4 (the threshold for what the FBI defines as mass murder) and 35 (just above the Virginia Tech massacre, the worst mass shooting in American history).
The victims. The victims are generalizations drawn from the historical record. Sadly this means teachers, college students, elementary school children.
Location. The city and state names have all been sites of mass shootings. I had considered either seeding the location with a huge list of cities or simply generating fake city names (which is what @NSA_PRISMbot does). I decided against these approaches, however, because I was determined to have @NRA_Tally act as a witness to real crimes.
Firearm. The bot randomly selects the deadly weapon from an array of 64 items, all handguns or rifles that have been used in a mass shooting in the United States. An incredible 75% of the weapons fired in mass shootings have been purchased legally, the killers abiding by existing gun regulations. Many of the guns were equipped with high-capacity magazines, again, purchased legally. The 140-character constraint of Twitter means some weapon names have been shortened, dropping, for example the words “semiautomatic” or “sawed-off.”
Response. This is a statement from the NRA in the form of a press release. Every possible response mirrors actual rhetorical moves the NRA has made after previous mass shootings. There are currently 14 stock responses, but the NRA has undoubtedly issued other statements of scapegoating and misdirection. @NRA_Tally is participatory in the sense that you can contribute to its database of responses. Simply submit a generalized yet documented response and I will incorporate it into the code.
@NRA_Tally is terrifying and unsettling, posing scenarios that go beyond the plausible into the realm of the super-real. It is an oppositional bot on several levels. It is obviously antagonistic toward the NRA. It is oppositional toward false claims that “guns don’t kill people,” purposefully foregrounding weapons over killers. It is even oppositional to social media itself, challenging the logic of following and retweeting. Who would be comfortable seeing such tragedies in their timeline on an hourly basis? Who would dare to retweet something that could be taken as legitimate news, thereby spreading unnecessary rumors and lies?
Protest Bots as Tactical Media
A friend who saw an early version of @NRA_Tally expressed unease about it, wondering whether or not the bot would be gratuitous. The bot canon is full of playful bots that are nonsensical and superfluous. @NRA_Tally is neither playful nor nonsensical, but is it superfluous?
No, it is not. @NRA_Tally, like all protest bots, is an example of tactical media. Rita Raley, another friend at UCSB, literally wrote the book on tactical media, a form of media activism that engages in a “micropolitics of disruption, intervention, and education.” Tactical media targets “the next five minutes” rather than some far off revolutionary goal. As tactical media, protest bots do not offer solutions. Instead they create messy moments that destabilize narratives, perspectives, and events.
How might such destabilization work in the case of @NRA_Tally?
As Salon points out, it is the NRA’s strategy—this is a long term policy rather than a tactical maneuver—to shut down debate by accusing anyone who talks about gun control as politicizing the victims’ death. A bot of conviction, however, cannot be shut down by such ironic accusations. A protest bot cannot be accused of dishonoring the victims when there are no actual victims. As the bot inexorably piles on headline after headline, it becomes clear that the center of gravity of each tweet is the name of the weapon itself. The bot is not about victims. It is about guns and the organization that makes such preventable crimes possible.
The public debate about gun violence is severely limited. This bot attempts to unsettle it, just for a minute. And, because this is a bot that doesn’t back down and cannot cower and will tweet for as long as I let it, it has many of these minutes to make use of. Bots of conviction are also bots of persistence.
Adorno once said that it is the role of the cultural critic to present society a bill it cannot pay. Adorno would not have good things to say about computational culture, let alone social media. But even he might appreciate that not only can protest bots present society a bill it cannot pay, they can do so at the rate of once every two minutes. They do not bullshit around.
An earlier version of this essay on Protest Bots can be found on Medium.
A bottleneck is a great conceptual metaphor to describe those pedagogical moments where a significant number of learners get stuck. Identifying bottlenecks is the first step toward designing learning pathways through those bottlenecks. I’m borrowing the idea from the Decoding the Disciplines project at Indiana University. As Joan Middendorf, one of the project leaders, puts it, “Bottlenecks are important because they signal where students are unable to grasp crucial ways of knowing in our fields.” The question of bottlenecks is a central concern in the opening weeks of the Davidson Domains Digital Learning Community.
Let me backtrack. What is Davidson Domains? What is the Davidson Domains Learning Community?
Davidson Domains
Davidson Domains is a pilot program that gives faculty, staff, and students a “domain of one’s own”—an online space for blogs, exhibits, research, creative work, portfolios, web development, programming, and more. Users name their domain and maintain control over it. Faculty and students can create a domain for their courses, but they can also use it outside of coursework. The Davidson Domains pilot is a partnership between the Digital Studies program, Davidson’s Center for Teaching and Learning, and our instructional technology team. The pilot is funded by the Andrew W. Mellon Foundation.
The mission of Davidson Domains is to enable faculty and students to:
Develop technical and critical web literacies;
Forge a digital identity through online publishing;
Reclaim ownership and control over one’s digital footprint;
Explore the possibilities of blended learning and social pedagogies.
Underlying this mission is a fundamental concern of the liberal arts: to raise technical, philosophical, artistic, economic, and political questions about the role of the Internet on ourselves, our communities, and our practices.
We quietly launched Davidson Domains a year ago and have seen dramatic growth. To wit:
The number of accounts on Davidson Domains in September 2014: 0
The number of accounts on Davidson Domains in May 2015: 255
The number of accounts on Davidson Domains in September 2015: 500
And we’re about to add capacity for 500 more accounts, making Davidson Domains available to nearly half the campus community. We haven’t tied the roll-out of Davidson Domains to any particular year of students (say, all rising seniors) or program (for example, the First Year Writing Program). Rather, faculty and students are developing their Domains Across the Curriculum (DAC) based on interest and need. Given that we’ve registered 500 accounts in 9 months, that’s a lot of interest and need.
Davidson Domains Learning Community
We kicked off Davidson Domains in December 2014 with a two-day workshop led by Jim Groom and Tim Owens. Jim and Tim are pioneers of the “domain of one’s own” movement and co-founders of Reclaim Hosting, our partner providing the actual domains. My collaborators at Davidson, including Kristen Eshleman, Anelise Shrout, and Katie Wilkes, have worked tirelessly with faculty and students on Davidson Domains as well. But this formal and informal faculty development isn’t enough. We don’t simply want a bunch of people using Davidson Domains, we want to build a community of practice around Davidson Domains.
This desire for—as Etienne Wenger describes a community of practice—a group “of people who share a concern or a passion for something they do and learn how to do it better as they interact regularly” is the impetus behind the newly formed Davidson Domains Learning Community. Approximately 25 faculty, staff, and students will meet as a group throughout the semester to think through the rewards, challenges, and possibilities of Davidson Domains. Smaller affinity groups of 3-4 people will also meet on their own to explore more focused topics, for instance, using domains to foster student dialogue or to support longitudinal constructive student projects.
We’ve learned over the past year that faculty have recurring questions about Davidson Domains, which include:
How do domains fit in with other technologies (like Moodle)?
Where do we find good models?
What’s the balance between student agency and scaffolding?
What about privacy and copyright?
Can we preserve the work on domains?
We hope to answer these questions for our faculty and students, or at least begin conversations about them. But I also have my own questions about Davidson Domains, more conceptual in nature:
How does total and free access to online domains change teaching, learning, and research in a liberal arts environment?
What happens when a community asks the same questions together, and repeatedly, over the course of the semester?
These questions are not simply idle musings. They are research questions. The first tackles the underlying premise of the entire domain of one’s own movement, while the second tackles the notion of a learning community. Working with Kristen Eshleman, Davidson’s Director of Digital Learning Research & Design, I aim to systematically explore these questions, with the Davidson Domains Learning Community serving as our object of study.
The Bottlenecks of Davidson Domains
Which brings me back to the question of bottlenecks. The affinity groups have a topic to discuss during their first meeting, the notes of which they’ll share with the rest of the learning community. That topic is the question of bottlenecks—the essential skills, concepts, and ways of thinking that stump us:
What are the bottlenecks for you or your students for working with Davidson Domains?
As David Pace and Joan Middendorf point out, there is a typology of bottlenecks. Understanding what type of bottlenecks we and our students face makes it easier to design ways of overcoming them. Bottlenecks might be:
technical (getting the technology itself to work)
procedural (knowing how to enact conceptual knowledge)
affective (affective perspectives or emotional responses that hinder us)
disciplinary (discipline-specific knowledge and practices)
For example, one faculty member told me she struggles with what she calls “Internet shyness”—this is a kind of affective bottleneck. Another faculty member noted that the text- and image-heavy nature of blogs worked against her teaching priorities, which in the performing arts depend upon embodied knowledge. That’s a disciplinary bottleneck. Our students, I’m sure, will face these and many other bottlenecks. But until we articulate them, we’re unable to move forward to address them. (I guess this is the bottleneck of bottlenecks.)
We are just getting started with the learning community, and I can’t wait to see where we end up. I believe that Davidson Domains are essential for the liberal arts in the digital age, and this community of practice will help us explain why. I’ll record our progress here from a more conceptual perspective, while the nitty-gritty progress will show up on our learning community site. In the meantime I’ll leave you with the slides from our first plenary meeting.
Digital Studies and Digital Art students at Davidson making cyborg interfaces with Makey Makeys and toys.
The Digital Studies program at Davidson College is growing! We now offer an interdisciplinary minor and, through our Center for Interdisciplinary Studies (CIS), an interdisciplinary major. Last year Digital Studies and the History Department partnered on a tenure-track search—leading to Dr. Jakub Kabala joining Davidson as a digital medievalist with a background in computational philology and digital spatial analysis.
I’m delighted to announce that Digital Studies is collaborating once again on a tenure line search, this time with the Art Department. Along with Jakub and myself, this position will form the core of the Digital Studies faculty. My vision for Digital Studies has always emphasized three areas: (1) the history, practice, and critique of digital methodologies; (2) the study of cultural texts, media, and practices made possible by modern technology; and (3) the design and creation of digital art and new media, which includes robotics, interactive installations, and physical computing. Roughly speaking, I think of these three areas in terms of methodology, culture, and creativity. This latest tenure track search addresses the last area, though of course the areas blur into each other in very interesting ways.
Here is the official search ad for the digital artist position. Please share widely!
Davidson College invites applications for a tenure-track Assistant Professor of Art and Digital Studies, with a specialization in interactive installation, transmedia art, robotics, data art, physical computing, or a similar creative field. Artists must demonstrate a distinguished record of creative work and a commitment to undergraduate education. Preference will be given to artists with a broad understanding of contemporary trends in Digital and New Media Art, including its history, theory, and practice. MFA by August 1, 2016 is required.
This tenure-track position is shared between the Art Department and Digital Studies Program. Art and Digital Studies at Davidson explore the contemporary technologies that shape daily life, focusing on critical making and digital culture. The successful applicant will teach in both Studio Art and Digital Studies. The candidate’s letter of application should highlight experiences that speak to both roles. The teaching load is 5 courses per year (reduced to 4 courses the first year). Classes include introductory and advanced digital art studio courses, as well as classes that focus on digital theory and practice.
Apply online at http://jobs.davidson.edu/. A complete application includes a letter of application, CV, artist’s statement, teaching philosophy, and a list of three or more references. In addition, submit links for up to 20 still images or up to 7 minutes of video in lieu of a portfolio. The application deadline is December 1, 2015. Do not send letters of reference until requested.
Davidson is strongly committed to achieving excellence and cultural diversity and welcomes applications from women, members of minority groups, and others who would bring additional dimensions to the college’s mission. Consistently ranked among the nation’s top liberal arts colleges, Davidson College is a highly selective, independent liberal arts college located in Davidson, North Carolina, close to the city of Charlotte. Davidson faculty enjoy a low student-faculty ratio, emphasis on and appreciation of excellence in teaching, and a collegial, respectful atmosphere that honors academic achievement and integrity.
This summer I attended the first annual Institute for Liberal Arts Digital Scholarship (ILiADS) at Hamilton College. It was an inspiring conference, highlighting the importance of collaborative faculty/student digital work at small liberal arts colleges. My own school, Davidson College, had a team at ILiADS (Professor Suzanne Churchill, Instructional Technologist Kristen Eshleman, and undergraduate Andrew Rikard, working on a digital project about the modernist poet Mina Loy). Meanwhile I was at the institute to deliver the keynote address on the final day. Here is the text of my keynote, called “Your Mistake was a Vital Connection: Oblique Strategies for the Digital Humanities.”
Forty years ago, the musician Brian Eno and painter Peter Schmidt published the first edition of what they called Oblique Strategies.Oblique Strategies resembled a deck of playing cards, each card black on one side, and white on the other, with a short aphoristic suggestion on the white side.
Doctorow, Cory. Oblique Strategies Deck, PO Box, The Barbican, London, UK. Photography, June 14, 2013. https://www.flickr.com/photos/doctorow/9041086636/.
These suggestions were the strategies—the oblique strategies—for overcoming creative blocks or artistic challenges. The instructions that came with the cards described their use: “They can be used as a pack…or by drawing a single card from the shuffled pack when a dilemma occurs in a working situation. In this case, the card is trusted even if its appropriateness is quite unclear.”
When we look at some of the strategies from the original deck of 55 cards, we can see why their appropriateness might appear unclear:
From Broackes, Victoria, and Geoffrey Marsh, eds. David Bowie Is… Special edition. London : New York: Victoria & Albert Museum, 2013.
And other strategies:
Make sure nobody wants it.
Cut a vital connection
Make a blank valuable by putting it in an exquisite frame
Do something boring
Honor thy error as a hidden intention
And one of my favorites:
Repetition is a form of change.
Brian Eno explained the origins of the cards in an interview on KPFA radio in San Francisco in 1980: The cards were a system designed to, as Eno put it, “foil the critic” in himself and to “encourage the child.” They were strategies for catching our internal critics off-guard. Eno elaborated:
The Oblique Strategies evolved from me being in a number of working situations when the panic of the situation—particularly in studios—tended to make me quickly forget that there were others ways of working and that there were tangential ways of attacking problems that were in many senses more interesting than the direct head-on approach.
If you’re in a panic, you tend to take the head-on approach because it seems to be the one that’s going to yield the best results. Of course, that often isn’t the case—it’s just the most obvious and—apparently—reliable method. The function of the Oblique Strategies was, initially, to serve as a series of prompts which said, “Don’t forget that you could adopt *this* attitude,” or “Don’t forget you could adopt *that* attitude.”
Other ways of working. There are other ways of working. That’s what the Oblique Strategies remind us. Eno and Schmidt released a second edition in 1978 and a third edition in 1979, the year before Schmidt suddenly died. Each edition varied slightly. New strategies appeared, others were removed or revised.
For example, the 2nd edition saw the addition of “Go outside. Shut the door.” A 5th edition in 2001 added the strategy “Make something implied more definite (reinforce, duplicate).” For a complete history of the various editions, check out Gregory Taylor’s indispensable Obliquely Stratigraphic Record. The cards—though issued in limited, numbered, editions—were legendary, and even more to the point, they were actually used.
David Bowie famously kept a deck of the cards on hand when he recorded his Berlin albums of the late seventies. His producer for these experimental albums was none other than Brian Eno. I’m embarrassed to say that I didn’t know about Bowie’s use of the Oblique Strategies
I knew about Tristan Tzara’s suggestion in the 1920s to write poetry by pulling words out of a bag. I knew about Brion Gysin’s cut-up method, which profoundly influenced William Burroughs. I knew about John Cage’s experimental compositions, such as his Motor Vehicle Sundown, a piece orchestrated by “any number of vehicles arranged outdoors.” Or Cage’s use of chance operations, in which lists of random numbers from Bell Labs determined musical elements like pitch, amplitude, and duration. I knew how Jackson Mac Low similarly used random numbers to generate his poetry, in particular relying on a book called A Million Random Digits with 100,000 Normal Deviates to supply him with the random numbers (Zweig 85).
RAND Corporation. A Million Random Digits with 100,000 Normal Deviates, 1955. http://www.rand.org/pubs/monograph_reports/MR1418/index2.html.
I knew about the poet Alison Knowles’ “The House of Dust,” which is a kind of computer-generated cut-up written in Fortran in 1967. I even knew that Thom Yorke composed many of the lyrics of Radiohead’s Kid A using Tristan Tzara’s method, substituting a top hat for a bag.
But I hadn’t heard encountered Eno and Schmidt’s Oblique Strategies. Which just goes to show, however much history you think you know—about art, about DH, about pedagogy, about literature, about whatever—you don’t know the half of it. And I suppose the ahistorical methodology of chance operations is part of their appeal. Every roll of the dice, every shuffle of the cards, every random number starts anew. In his magisterial—and quite frankly, seemingly random—Arcades Project, Benjamin devotes an entire section to gambling, where his collection of extracts circles around the essence of gambling. “The basic principle…of gambling…consists in this,” says Alain in one of Benjamin’s extracts, “…each round is independent of the one preceding…. Gambling strenuously denies all acquired conditions, all antecedents…pointing to previous actions…. Gambling rejects the weighty past” (Benjamin 512). Every game is cordoned off from the next. Every game begins from the beginning. Every game requires that history disappear.
That’s the goal of the Oblique Strategies—to clear a space where your own creative history doesn’t stand in the way of you moving forward in new directions. Now in art, chance operations may be all well and good, even revered. But what does something like the Oblique Strategies have to do with the reason we’re here this week: research, scholarship, the production of knowledge? After all, isn’t rejecting “the weighty past” an anathema to the liberal arts?
Well, I think one answer goes back to Eno’s characterization of the Oblique Strategies: there are other ways of working. We can approach the research questions that animate us indirectly, at an angle. Forget the head-on approach for a while.
One way of working that I’ve increasingly become convinced is a legitimate—and much-needed form of scholarship—is deformance. Lisa Samuels and Jerry McGann coined this word, a portmanteau of deform and performance. It’s an interpretative concept premised upon deliberately misreading a text. For example, reading a poem backwards line-by-line. As Samuels and McGann put it, reading backwards “short circuits” our usual way of reading a text and “reinstalls the text—any text, prose or verse—as a performative event, a made thing” (Samuels & McGann 30). Reading backwards revitalizes a text, revealing its constructedness, its seams, edges, and working parts.
Let me give you an example of deformance. Mary Lee and Katharine are two social media stars, with tens of thousands of followers on Twitter each. They’re also great white sharks in the Atlantic Ocean, tagged with geotrackers by the non-profit research group OCEARCH. Whenever either of the sharks—or any of the dozens of other sharks that OCEARCH has tagged—surfaces longer than 90 seconds, the tags ping geo-orbiting satellites three times in order to triangulate a position. That data is then shared in real-time on OCEARCH’s site or app.
OCEARCH Tracking Map (screenshot)
The sharks’ Twitter accounts, I should say, are operated by humans. They’ll interact with followers, post updates about the sharks, tweet shark facts, and so on. But these official Mary Lee and Katharine accounts don’t automatically tweet the sharks’ location updates.
Sometime this summer—well, actually, it was during shark week—I thought wouldn’t it be cool to create a little bot, a little autonomous program, that automatically tweeted Mary Lee and Katharine’s location updates. But first I needed to get the data itself. I was able to reverse engineer OCEARCH’s website to find an undocumented API, a kind of programming interface that allows computer programs to talk to each other and share data with each other. OCEARCH’s database gives you raw JSON datathat looks like this to a human reader:
But to a computer reader, it looks like this:
Structured data is a thing of beauty.
Reverse engineering the OCEARCH API is not the deformance I’m talking about here. What I found when the bot started tweeting location updates of these two famous sharks was, it was kind of boring. Every few days one of the sharks would surface long enough to get a position, it would post to Twitter, and that was that.
21 July 2015 11:09:39 AM: Katharine pinged satellites at 33.76481, -75.01413. pic.twitter.com/nlGqhhpANG
Something was missing. I wanted to give this Twitter account texture, a sense of personality. I decided to make Mary Lee and Katharine writers. And they would share their writing with the world on this Twitter account. The only problem is, I don’t have time to be a ghost writer for two great white sharks.
So I’ll let a computer do that.
I asked some friends for ideas of source material to use as deformance pieces for the sharks. These would be texts that I could mangle or remix in order to come up with original work that I would attribute to the sharks. A friend suggested American Psycho—an intriguing choice for a pair of sharks, but not quite the vibe I was after. Mary Lee and Katharine are female sharks. I wanted to use women writers. Then Amanda French suggested Virginia Woolf’s novel Night and Day, which just happens to feature two characters named Katharine and Mary. It was perfect, and the results are magical.
Now, Katharine tweets odd mashed-up fragments from Night and Day, each one paired with historical location data from OCEARCH’s database. On December 9, 2014, Katharine was very close to the shore near Rhode Island, and she “wrote” this:
Katharine: Down all luxuriance and plenty to the verge of decency; and in the night, bereft of life (09-Dec-2014) pic.twitter.com/SEEsv3FBKm
In every case, the journal part of the tweet—the writing—is extracted randomly from complete text of Night and Day and then mangled by a Python program. These fragments, paired with the location and the character of a shark, stand on their own, and become new literary material. But they also expose the seams of the original source.
Whereas Katharine writes in prose fragments, I wanted Mary Lee to write poetry:
The line of heroes stands, godlike: Though we wander about, the tangled thread falls slack.
How does Mary Lee writer this? Her source material comes from the works of H.D.—Hilda Doolittle, whose avant-garde Imagist poems are perfect for the cut-up method.
I send you this, a single house of the hundred to freighted ships, baffled in wind and blast.
Mary Lee follows the cut-up method described by Brion Gysin decades ago. I’ve made a database of 1,288 lines of H.D.’s most anthologized poetry. Every tweet from Mary Lee is some combination of three of those 1,288 lines, along with slight typographic formatting. All in all, there are potentially 2 billion, 136 million and 719 thousand original poems that Mary Lee could write.
The snow is melted, we have always known you wanted us. My mind is reft.
What kind of project is @shark_girls? Is it a public humanities project—sharing actual data—dates, locations, maps—that helps people to think differently about wildlife, about the environment, about the interactions between humans and nature? Is it an art project, generating new, standalone postmodern poetry and prose? Is it a literary project, that lets us see Virginia Woolf and H.D. in a new light? Is it all three?
I’ll let other people decide. We can’t get too hung up on labels. What’s important to me is that whatever @shark_girls is about, it’s also about something else. As Susan Sontag wrote about literature: “whatever is happening, something else is always going on.” And the oblique nature of deformance will often point toward that something else. Deformance is a kind of oblique strategy for reading a poem. If the Oblique Strategies deck had a card for deformance it might read:
Work backwards.
Or maybe, simply,
Shuffle.
Another kind of deformance—another oblique strategy for reading—are Markov Chains. Markov chains are statistical models of texts or numbers, based on probability. Let’s say we have the text of Moby Dick.
Just eyeballing the first page we can see that certain words are more likely to be followed by some words than other words. For example, the pronoun “I” is likely to be followed by the verb “find” but not the word “the.” A two-gram Markov Chain looks at the way one pair of words is likely to be followed by a second pair of words. So the pair “I find” is likely to be followed by “myself growing” but not the pair of words “me Ishmael.” A three-gram Markov parses the source text into word triplets. The chain part of a Markov Chain happens when one of these triplets is followed by another triplet, but not necessarily the same triplet that appears in the source text. And then another triplet. And another. It’s a deterministic way to create texts, with each new block of the chain independent of the preceding blocks. Talk about rejecting the weighty past. If you work with a big enough source text, the algorithm generates sentences that are grammatically correct but often nonsensical.
Let’s generate some Markov chains of Moby Dick on the spot. Here’s a little script I made. If it takes a few seconds to load, that’s because every time it runs, it’s reading the entire text of Moby Dick and calculating all the statistical models on the fly. Then spitting out a 3-, 4-, or 5-gram Markov chain. The script tells you what kind of Markov n-gram it is. The script is fun to play around with, and I’ve used it to teach what I call deep textual hacks. When I show literature folks this deformance and teach them how to replace Moby Dick with a text from their own field or time period, they’re invariably delighted. When I show history folks this deformance and teach them how to replace Moby Dick with a primary source from their own field or time period, they’re invariably horrified. History stresses attentiveness to the nuances of a primary source document, not the way you can mangle that very same primary source. Yet, also invariably, my history colleagues realize what Samuels and McGann write about literary deformance is true of historical deformance as well: deformance revitalizes the original text and lets us see it fresh.
All of this suggests what ought to be another one of Brian Eno and Peter Schmidt’s Oblique Strategies:
Misreading is a form of reading.
And to go further, misreading can be a form of critical reading.
Now, let me get to the heart of the matter. I’ve been talking chance operations, deterministic algorithms, and other oblique strategies as a way to explore cultural texts and artifacts. But how do these oblique strategies fit in with the digital humanities? How might oblique strategies not only be another way to work in general, but specifically, another way to work with the digital scholarship and pedagogy we might otherwise more comfortably approach head-on, as Brian Eno put it.
Think about how we value—or say we value—serendipity in higher education. We often praise serendipity as a tool for discovery. When faculty hear that books are going into off-site storage, their first reaction is, how are we going to stumble upon new books when browsing the shelves?
A recent piece by the digital humanities Victorianist Paul Fyfe argues that serendipity has been operationalized, built right into the tools we use to discover new works and new connections between works (Fyfe 262). Serendipomatic, for example, is an online tool that came out of the Roy Rosenzweig Center for History and New Media. You can dump in your entire Zotero library, or even just a selection of text, and Serendipomatic will find sources from the Digital Public Library of America or Europeana that are connected—even if obliquely—to your citations. Let your sources surprise you, the tagline goes.
Tim Sherratt has created a number of bots that tweet out random finds from the National Library of Australia. I’ve done the same with the Digital Public Library of America, creating a bot that posts random items from the DPLA.Similarly, there’s @BookImages, which tweets random cat-pics images from the 3.3 million public domain images from pre-1922 books that the Internet Archive uploaded to Flickr.
Fyfe suggests that “these machines of serendipity sometimes offer simple shifts of perspective” (263)—and he’s totally right. And simple shifts of perspective are powerful experiences, highlighting the contingency and plurality of subjectivity.
But in all these cases, serendipity is a tool for discovery, not a mode of work itself. We think of serendipity as a way to discover knowledge, but not as a way to generate knowledge. This is where the oblique strategies come into play. They’re not strategies for discovery, they’re practices for creativity.
Let me state it simply: what if we did the exact opposite of what many of you have spent the entire week doing. Many of you have been here a whole week, thinking hard and working hard—which are not necessarily the same thing—trying to fulfill a vision, or at the very least, sketch out a vision. That is good. That is fine, necessary work. But what if we surrendered our vision and approached our digital work obliquely—even, blindly.
I’m imagining a kind of dada DH. A gonzo DH. Weird DH. Which is in fact the name of a panel I put together for the 2016 MLA in Austin in January. As I wrote in the CFP, “What would an avant-garde digital humanities look like? What might weird DH reveal that mainstream DH leaves out? Is DH weird enough already? Can we weird it more?”
My own answer to that last question is, yes. Yes, we can. Weird it more. The folks on the panel: Micki Kaufman, Shane Denson, Kim Knight, Jeremy Justus will all be sharing work that challenges our expectations about the research process, about the final product of scholarship, and even what counts as knowledge itself, as opposed to simply data, or information.
So many of the methodologies we use in the digital humanities come from the social sciences—network analysis, data visualization, GIS and mapping, computational linguistics. And that’s all good and I am 100 percent supportive of borrowing methodological approaches. But why do we only borrow from the sciences? What if—and this is maybe my broader point today—what if we look for inspiration and even answers from art? From artists. From musicians and poets, sculptors and quilters.
And this takes me back to my earlier question: what might a set of oblique strategies—originally formulated by a musician and an artist—look like for the digital humanities?
Well, we could simply take the existing oblique strategies and apply them to our own work.
Do something boring.
Maybe that’s something we already do. But I think we need a set of DH-specific oblique strategies. My first thought was to subject the original Oblique Strategies to the same kind of deterministic algorithm that I showed you with Moby-Dick, that is, Markov chains.
Here are a few of the Markov Chained Oblique Strategies my algorithm generated:
Breathe more human. Where is the you do?
Make what’s perfect more than nothing for as ‘safe’ and continue consistently.
Your mistake was a vital connection.
I love the koan-like feeling of these statements. The last one made so much sense that I worked it into the title of my talk: your mistake was a vital connection. And I truly believe this: our mistakes, in our teaching, in our research, are in fact vital connections. Connections binding us to each other, connections between domains of knowledge, connections between different iterations of our own work.
But however much I like these mangled oblique strategies, they don’t really speak specifically about our work in the digital humanities. So in the past few weeks, I’ve been trying to create DH-specific oblique strategies, programmatically.
The great thing about Markov chains is that you can combine multiple source texts, and the algorithm will treat them equally. My Moby Dick Markov Chains came from the entire text of the novel, but there’s no reason I couldn’t also dump in the text of Sense and Sensibility, creating a procedurally-generated mashup that combines n-grams from both novels into something we might call Moby Sense.
So I’m going to try something for my conclusion. And I have no idea if this is going to work. This could be a complete and utter failure. Altogether, taking into account the different editions of the Oblique Strategies, there are 155 different strategies. I’m going to combine those lines with texts that have circulated through the digital humanities community in the past few years. This source material includes Digital_Humanities, The Digital Humanities Manifesto, and a new project on Critical DH and Social Justice, among other texts. (All the sources are linked below.) I’ve thrown all these texts together in order to algorithmically generate my new DH-focused oblique strategies.
[At this point in my keynote I started playing around with the Oblique DH Generator. The version I debuted is on a stand-alone site, but I’ve also embedded it below. My talk concluded—tapered off?—as I kept generating new strategies and riffing on them. We then moved to a lively Q&A period, where I elaborated on some of the more, um, oblique themes of my talk. As nicely as this format worked at ILiADS, it doesn’t make for a very satisfying conclusion here. So I’ll wrap up with a new, equally unsatisfying conclusion, and then you can play with the generator below. And draw your own conclusions.]
My conclusion is this, then. A series a oblique strategies for the digital humanities that are themselves obliquely generated. The generator below is what I call a webtoy. But I’ve also been thinking about it as what Ted Nelson calls a “thinkertoy”—a toy that helps you think and “envision complex alternatives” (Dream Machines 52). In this case, the thinkertoy suggests alternative approaches to the digital humanities, both as a practice and as a construct (See Kirschenbaum on the DH construct). And it’s also just plain fun. For, as one of the generated oblique strategies for DH says, Build bridges between the doom and the scholarship. And what better way to do that than playing around?
Benjamin, Walter. The Arcades Project. Edited by Rolf Tiedemann. Translated by Howard Eiland and Kevin McLaughlin. Cambridge, Massachusetts: Belknap-Harvard UP, 1999.
Kirschenbaum, Matthew. “What Is ‘Digital Humanities,’ and Why Are They Saying Such Terrible Things about It?” Differences 25, no. 1 (2014): 46–63. doi:10.1215/10407391-2419997.
Nelson, Theodor H. Computer Lib/Dream Machines. 1st ed. Chicago: Hugo’s Book Service, 1974.
Samuels, Lisa, and Jerome McGann. “Deformance and Interpretation.” New Literary History 30, no. 1 (January 1, 1999): 25–56.
Sontag, Susan. “In Jerusalem.” The New York Review of Books, June 21, 2001. http://www.nybooks.com/articles/archives/2001/jun/21/in-jerusalem/.
Zweig, Ellen. “Jackson Mac Low: The Limits of Formalism.” Poetics Today 3, no. 3 (July 1, 1982): 79–86. doi:10.2307/1772391.
I’m at the Electronic Literature Organization’s annual conference in Bergen, Norway, where I hope to capture some “think aloud” readings of electronic literature (e-lit) by artists, writers, and scholars. I’ve mentioned this little project elsewhere, but it bears more explanation.
The think aloud protocol is an important pedagogical tool, famously used by Sam Wineburg to uncover the differences in interpretative strategies between novice historians and professional historians reading historical documents (see Historical Thinking and Other Unnatural Acts, Temple University Press, 2001).
The essence of a think aloud is this: the reader articulates (“thinks aloud”) every stray, tangential, and possibly central thought that goes through their head as they encounter a new text for the first time. The idea is to capture the complicated thinking that goes on when we interpret an unfamiliar cultural artifact—to make visible (or audible) the usually invisible processes of interpretation and analysis.
Once the think aloud is recorded, it can itself be analyzed, so that others can see the interpretive moves people make as they negotiate understanding (or misunderstanding). The real pedagogical treasure of the think aloud is not any individual reading of a new text, but rather the recurring meaning-making strategies that become apparent across all of the think alouds.
By capturing these think alouds at the ELO conference, I’m building a set of models for engaging in electronic literature. This will be invaluable to undergraduate students, whose first reaction to experimental literature is most frequently befuddlement.
If you are attending ELO 2015 and wish to participate, please contact me (samplereality at gmail, @samplereality on Twitter, or just grab me at the conference). We’ll duck into a quiet space, and I’ll video you reading an unfamiliar piece of e-lit, maybe from either volume one or volume two of the Electronic Literature Collection, or possibly an iPad work of e-lit. It won’t take long: 5-7 minutes tops. I’ll be around through Saturday, and I hope to capture a half dozen or so of these think alouds. The more, the better.



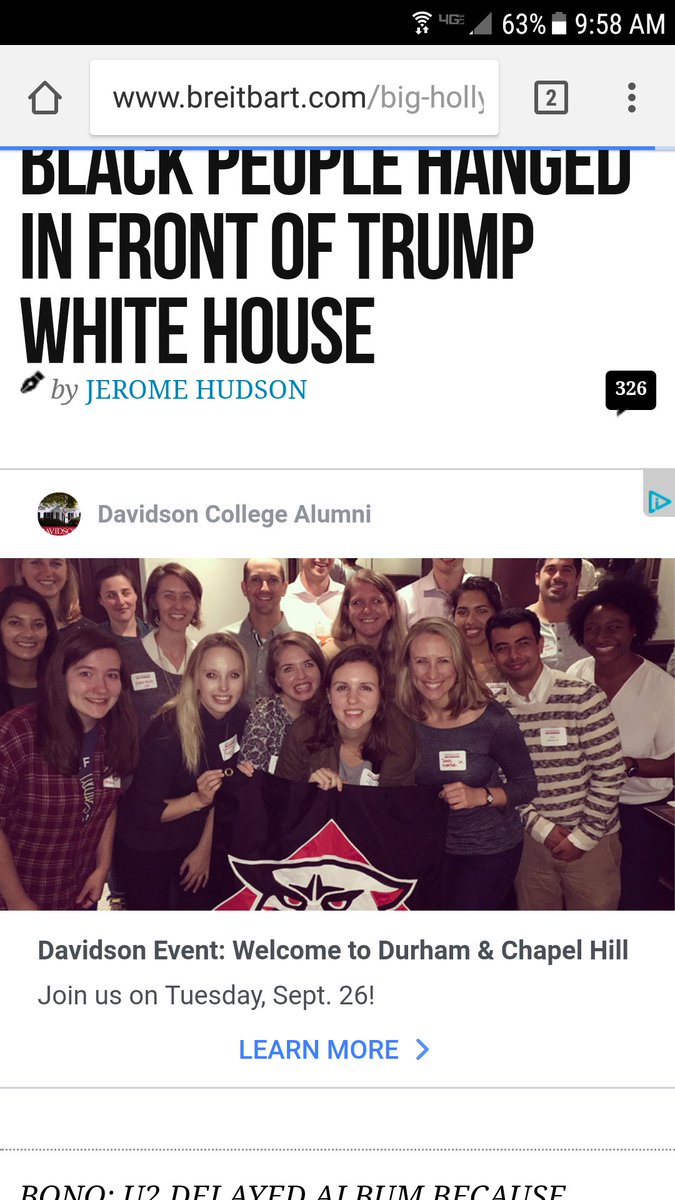

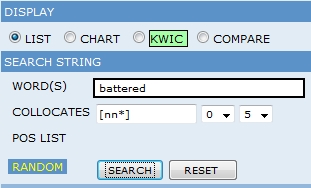
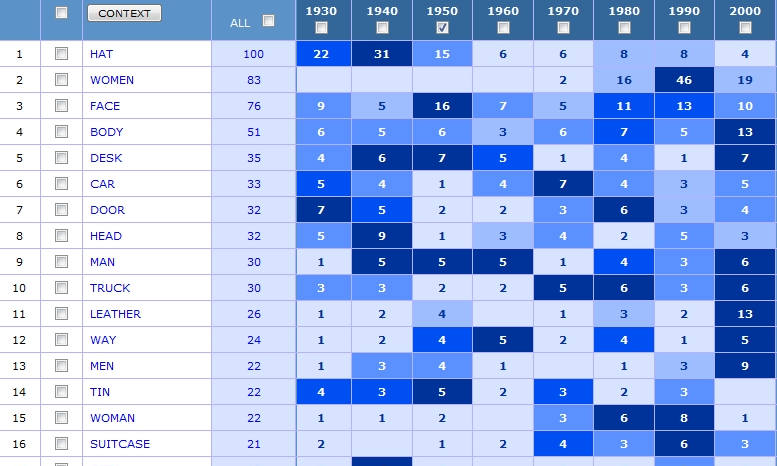
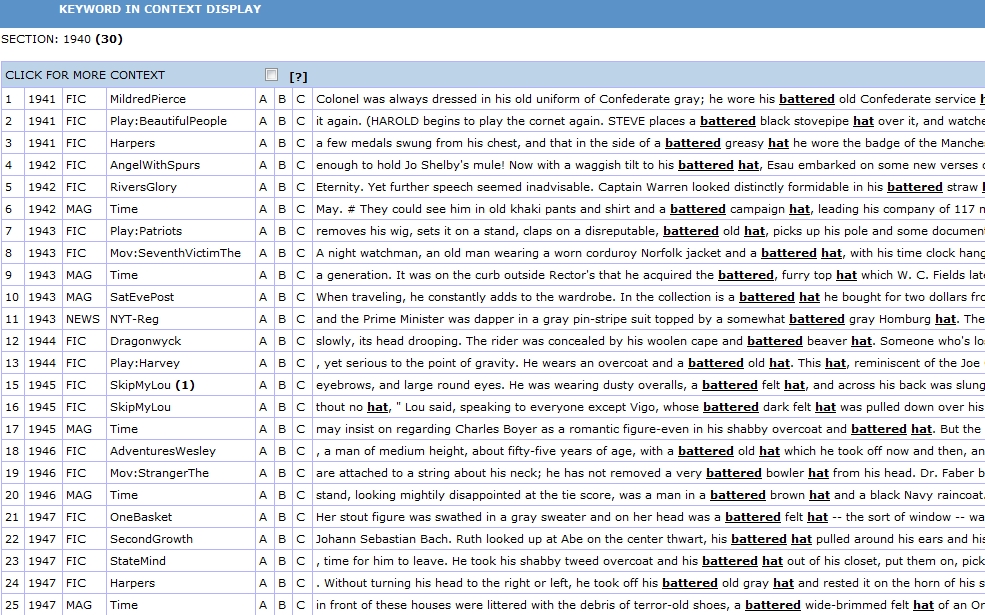



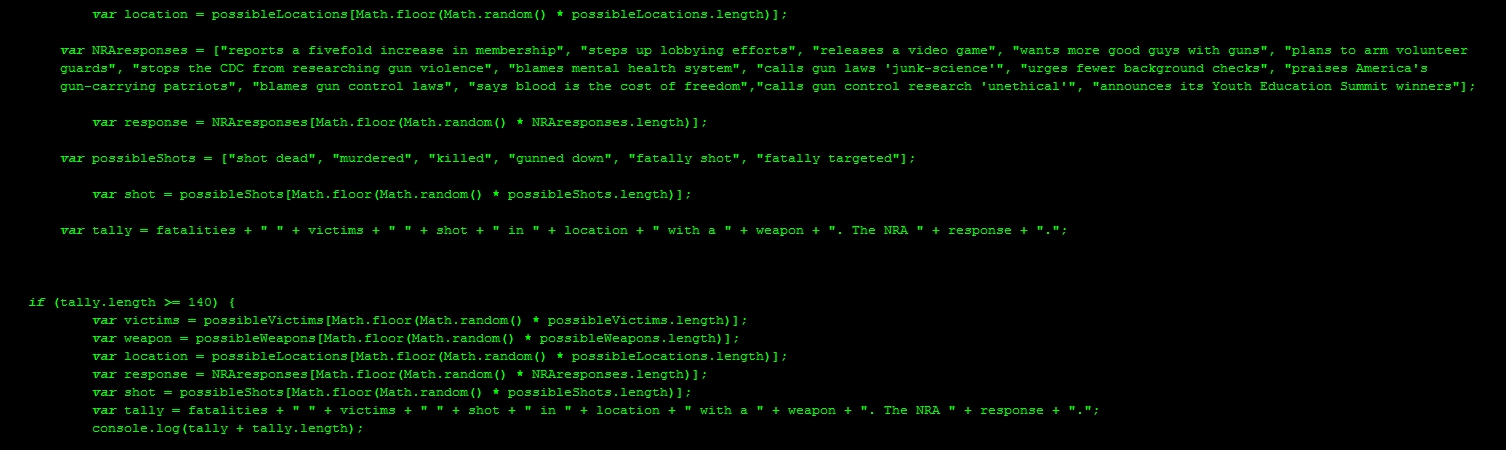
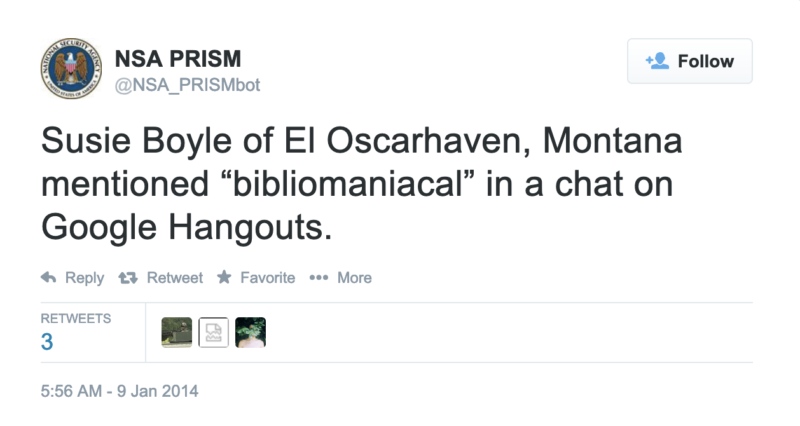

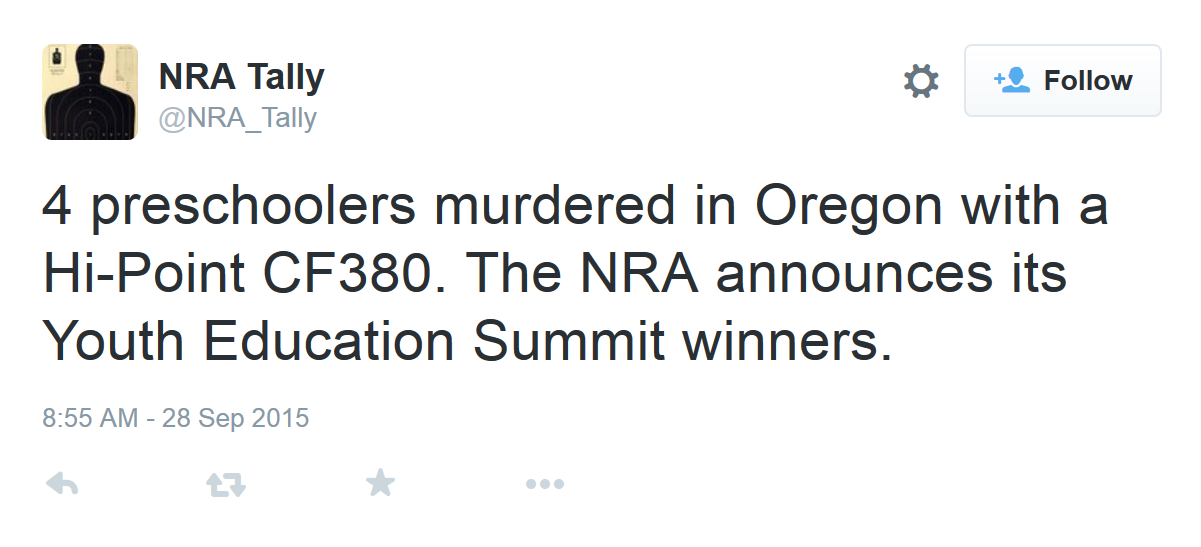









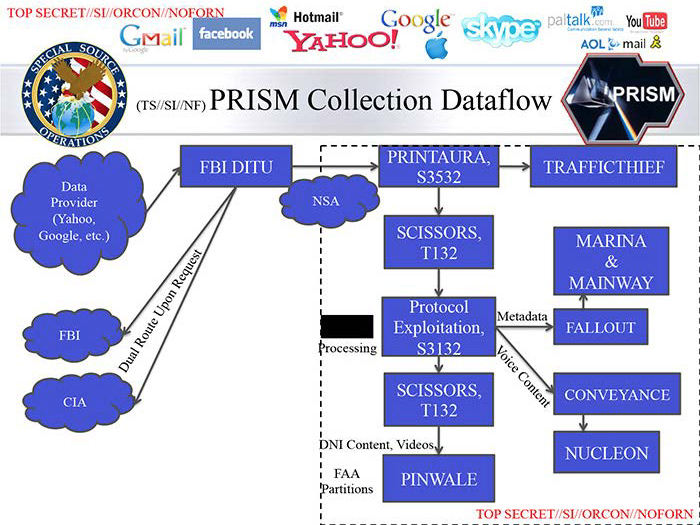{kind=link}
{kind=link}